目录
数据分析前景
环境准备
Python语法
语法查漏补缺
鸭子类型
可变对象与不可变对象
字节与Unicode
数据结构查漏补缺
切片与索引
zip语法
序列生成字典
函数
每文一语
数据分析前景
曾经有一个老师这样问过他的学生,21世纪什么最值钱?刹那间,众说纷纭,有人说知识最值钱,也有人说颜值最值钱,更有甚者说“生命诚可贵,爱情价更高”,老师让每一个人说出了自己心中的答案,坐在一角的同学说了这样一句话,让这个答案似乎完美的回应了这个问题。“你最需要的东西才是最有价值的”,好像确实如此,有人缺少健康,花去一身钱财也觉得坦然,有人的缺少快乐,纵然世间万般精彩他也毫无动力,突然间让我想起了那一句话“人生如逆旅,我亦是行人”。
如果作为一个数据分析的学习者,那么我一定会从这个角度来说,不错,答案就是“数据最有价值”。数据看似是一个冷冰冰的数字,但是它却给社会带了希望,给企业带来了财富,给个人带来了规划。大数据的浪潮冲击之下,无数人选择数据分析的岗位,那么怎样才能脱颖而出,成为行业的领军人物。基础最重要,掌握好数据分析的基础就像是作家小时候学习词汇一样,就如同诗人掌握格律辞调一般,至于以后的日子,就是留给你自己发挥那独特的魅力和书写五彩的蓝图时间了!
数据分析与大数据切合在一起,据2019年统计未来市场上数据分析的人才紧缺,大约缺口30万左右。随着时间的推移,相信现在更加的紧迫,所以数据分析、大数据分析在未来的前景还是不错的,学好基础就等于掌握了内功,要想内力十足,就让我们一起开启数据分析之旅吧!
环境准备
数据分析基于pandas 与numpy模块,建议在交互式的环境下学习和应用,便于调试。如果你还是初学者,没有安装好环境建议移步到《初识Python之软件安装篇》,会详细的介绍如何搭建环境,我们一般搭建好之后,就可以使用了,基于anaconda的ipython和jupyter-notebook的环境,都是安装好之后就会有的,jupyter-notebook只需要在anaconda的终端输入:pip install jupyter 安装即可,之后就会弹出一个图标,然后点击就好了,自动打开你的默认浏览器,你就可以开始敲代码了。

Python语法
在这里我不会介绍Python的语法,如果有需要的小伙伴请去本人博客主页专栏上查看《Python语法入门到精通》,详细的介绍Python的语法知识。

本文只介绍关于Python的一些数据分析技巧,从下一篇我们将会详细得介绍每一个数据分析的模块使用
关于在ipython的环境下我们需要注意的是,缩进原则,一切皆对象在Python中,每一个对象都会在内存里面,并且会关联到每一种类型。
语法查漏补缺
鸭子类型
在平常的情况下,我们不会具体的关心某一个对象的具体的类型,而是会去关心它的特殊方法和行为。鸭子类型就是说可迭代,如果一个对象不可遍历,我们可以通过转换,比如X不是一个列表或者数组,那么我们可以将其转换。
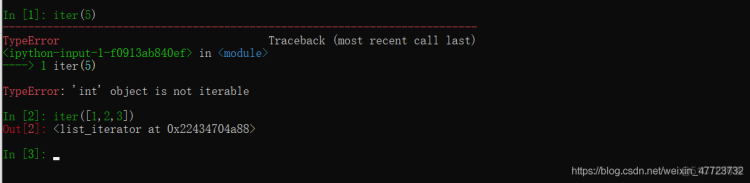
一个单纯的数字5并不可迭代,而一个列表可以,这样说你应该明白了。
可变对象与不可变对象
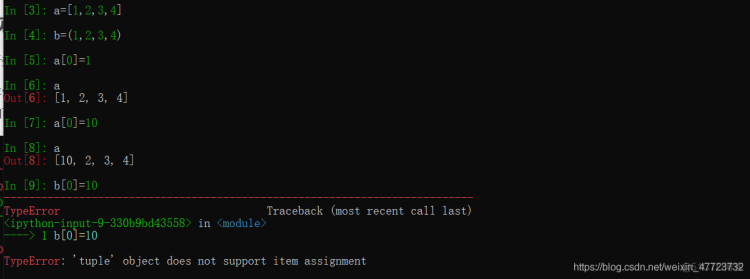
在Python中的大部门对象,例如字典、列表、numpy数组都是可变对象,就是说可以修改,但是对于元组和字符串是不可以变的,我们不能通过直接修改,但是可以通过切片和组合的方式修改一些属性。
字节与Unicode
在爬虫的时候我们会遇到很多解码与转码的问题,那么对于字节我们应该如何的去实现了,我们常用的是utf-8类型下面我们看看

通过encode转码为bytes类型,然后通过decode解码即可,涉及到很多字节编码,比如gbk、utf-16等,有需要可以去网上查看一下相关的文档
数据结构查漏补缺
列表排序根据长度、字典根据里面的值排序(默认升序),使用lambda函数即可对象键里面的值

切片与索引
在数据对象里面我们已经利用索引来解决一些场景的应用
1.无论如何切片,只要记住索引出来的元素个数为首尾数字相减取绝对值即可,比如[3:7],[-6:-3],[-4:],[:6]分别代表取出索引出4,3,4,6个元素。
2.在有一些特定场景,我们需要取出特定的字符,之前写过一篇自动获取汇率转换篇,详情请查看有很多关于索引的应用。
3.请记住无论是正索引还是负索引最后面的那个位置不能获取,除非省略了,比如[-6:]自动获取从最后面的一个元素(包含最后一个)到前面的6个元素。
4.对于多重索引[::2]从第一个开始(取到)每个2个数取一个值
5.对于元素和列表进行翻转利用向步进传值-1,比如[::-1]就可以达到翻转的作用,当然列表里面有专门翻转的内置函数方法:list(reversed(a))、sorted(listNode,reverse = True)。

zip语法
在之前的Python语法里面漏掉了这一个模块的讲解,在这里我将详细的介绍一波;Zip将列表、元组或其他序列的元素配对,新建一个元组构成的列表,Zip可以处理任意的长度序列,它生成的列表长度由最短的序列决定,它的应用场景是同时遍历多个序列。
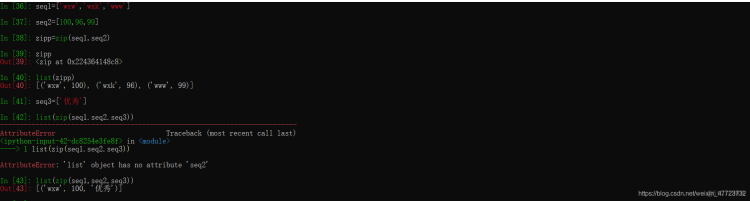
对于已经配对好的序列,Zip函数有一种拆分的方法:a,b=zip(*zipp),就会把已经组成好的拆分两个独立的元组,也就是类似于字典的键值对那种,只是单独的取出来了
reserveed函数将序列的元素倒序排列
序列生成字典
我们可以使用dict.keys()取出所有的键,dict.values()取出所有的值,dict.items()取出所有的键值对,如果我们有一个字典需要合并(加入)到另外一个字典,我们只需要dict.update(dict1)即可,如果新的字典里面含有和原来的字典里面的键一样的名称,它会自动覆盖它的值并更新新的值。

更多的字典介绍请移步到《计算机二级语法整理》
函数
函数的返回值一定要相应的位置接收
掌握好Python环境的语言的基础后,下一篇就是我们学习数据分析计算值numpy了
每文一语
文字总是要含蓄的,也要向酒一样,浅斟最好。