
1. 案例一:rw=randwrite


根据以上命令,iodepth=64,可以看到commit 队列的深度永远停在64,一旦释放一笔命令,立马就填充一笔命令

这是一笔写的log,填充buff,到最后被调度进入队列中,ddir=1是写,最后的depth是当前队列深度。

前面三行是第一笔写的返回值,IO 队列检查到一笔命令返回了,min=1表示一笔命令,然后通知host这边接收到一个事件,complete表示这条命令正真的完成。
当这笔写命令完成以后,立马就开始读该结果,因为设置的—verify_backlog=1
这是一笔读的操作log,ddir=0是读

这是这笔读的完成消息,说明读没有问题

这是这笔写的随机序列,第一个参数是offset,第二个参数是len,因为这笔FIO 的bs=4k,所以每笔write或者read的lengh=8个512.
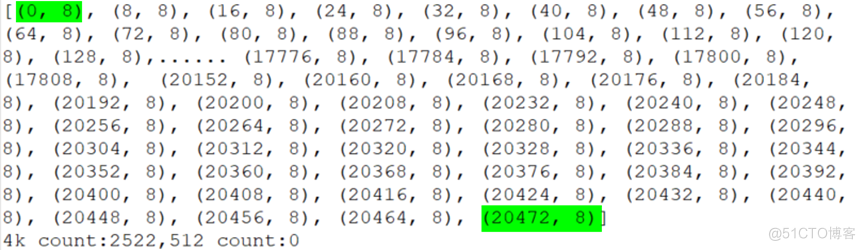
对所有的序列进行排序可以看到起始位置从0开始,最后一个offset的起始位置是20472
10M=1010241024/512=20480个LBA(每个LBA是512B)
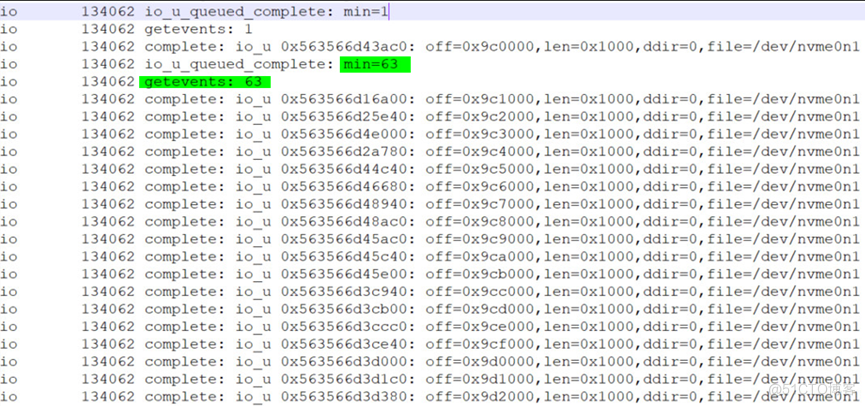
当write命令全部发完以后,一次性收到了63个read的response
在上面这个例子中设置的rw=randwrite,为什么会有读呢,原因是设置了verify_backlog

2. 案例二:rw=randwrite,并且设置bssplit


默认是随机生成offset,这里的结果是排序后的结果
但是可以看到当设置bssplit=512:4k的时候,默认发送的512的write是4k的4倍左右。

默认情况下如果没有给百分比,那就是随机的。
debug的脚本:
import re
f=open("ming.log","r")
offset_list=[]
bs_list=[]
count512=0
count4k=0
pattern=re.compile(r'.*off=(\S+),len=(\S+),ddir=0')
for line in f.readlines():
if "complete" in line:
match=pattern.match(line)
if match:
(offset,bs)=match.groups()
offset_list.append(int(int(offset,16)/512))
bs_list.append(int(int(bs,16)/512))
if int(int(bs,16)/512)==8:
count4k+=1
else:
count512+=1
#每一个元素包含一个io起始的sector位置和io的长度
io_seq_list=zip(offset_list,bs_list)
io_seq_list=list(io_seq_list)
#print (io_seq_list)
#print io_seq_list
def choose_first(item):
return item[0]
#将随机的io顺序排列
(io_seq_list).sort(key=choose_first)
print (io_seq_list)
print("4k count:{},512 count:{}".format(count4k,count512))