在现代计算机中,CPU往往都是多核的,而由于每个CPU Core中都有自己的高速缓存Cache,因此就会造成内存数据读写的不一致性,表现为 指令乱序 与 不可见性 问题。为此,java为了统一物理世界中的计算机组成架构,提出了JMM内存模型,并抽象了 LoadLoad , StoreStore , LoadStore , StoreLoad 四个内存屏障指令来应对不同CPU的体系。本文先介绍下多核CPU体系下,并发编程需要克服的问题,然后再介绍下Java的内存屏障各自的含义,并举例说明对应的场景。
顺序性与可见性
在执行程序时,为了提高性能,编译器和处理器会通常对指令进行重排序,即:
也就是说,即使指令的执行没有重排序,是按顺序执行的,但由于缓存的存在,仍然会出现数据的非一致性的情况。我们把这种 普通读``普通写 可以理解为是 有延迟的 延迟读 、 延迟写 , 因此即使读在前、写在后,因为有延迟,然后仍然会出现写在前、读在后的情况。
为了解决上述重排带来的问题,提出了 as-if-serial 原则,即不管怎么重排序,程序执行的结果在 单线程 里保持不变。为了遵守 as-if-serial 原则,我们需要一种特殊的指令来阻止特定的重排,使其保持结果一致,这种指令就是 内存屏障 。
内存屏障有两个效果:
因此,在CPU的物理世界里,内存屏障通常有三种:
JMM的四种读写屏障
由于物理世界中的CPU屏障指令和效果各不一样,为了实现跨平台的效果,针对读操作load和写操作store,Java在JMM内存模型里提出了针对这两个操作的四种组合来覆盖读写的所有情况,即:读读LoadLoad、读写LoadStore、写写StoreStore、写读StoreLoad。
- LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
- LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
那么如何理解这四个屏障指令呢?或者为什么需要这四种屏障指令,如果没有会出现什么情况。讨论这个问题,我们可以把目光聚焦在 可见性 上,因为如果顺序性都不能保证,那结果肯定是有问题的,即无法保证 as-if-serial 原则。那么, 在指令都是顺序执行的情况下,为什么会存在数据不一致的问题呢?
这就是CPU中的缓存系统导致的重排序,由于普通的读和写面向的是每个CPU core自己内部的cache,从而导致读可能读到的是旧值,写的数据没有即时刷入主存,让其他CPU core变的可见。也就是, 因为CPU中cache的存在,导致读和写都是有“延迟”的 。由于无法保证读和写的及时性,所以也就出现了由于“可见性”问题而产生的指令重排问题。
LoadLoad v.s. StoreStore
这两个屏障指令相对好理解,即CPU物理世界中的 读屏障lfence 和 写屏障sfence ,确保 load1; LoadLoad; load2 中的load1读取的数据保证在load2读取前完成,以及确保 store1; StoreStore; store2 中的store1必须在store2刷入数据前已经刷入数据并保证对其他处理器可见。
请注意,这里的读取数据指的是读取那些“最新”的数据,是其他处理器中对外可见的那些数据,也即,读的不是自己缓存中的数据,而是内存中的数据。写数据也是,指的是写入数据完成的标准是对其他处理器可见,也即是,store1的数据会优先对于store2写入内存,从而其他处理器可以正确获取store1和store2的写入顺序。
但是,不管是读屏障,还是写屏障,他们只是保证了读最新数据的顺序,写入最新数据的顺序,但并不保证立即执行,即读写可能是延迟的,例如 store1; StoreStore; store2 中,store1和store2的数据不一定会及时刷入内存, 但如果刷入,一定是store1比store2先刷入的。
同时,每个屏障指令只负责自己的场景,即 LoadLoad 负责前后的读数据是有先后顺序的,但不保证写的顺序,例如 load1; LoadLoad; store1 ,由于读和写都是有延迟的,而 LoadLoad 并不负责写操作相关的,所以这种情况下,就需要有其他两个屏障指令 LoadStore StoreLoad 来帮助,通过自由组合以上四种指令,才能确保实现 as-if-serial 原则。
//初始状态a,b都为0int a = 0, int b = 0;
// CPU 0 执行 foo()
void foo(void) {
a = 1;
//StoreStore;
b = 1;
}
// CPU 1 执行 bar()
void bar(void) {
while (b == 0) continue;
//LoadLoad;
assert(a == 1);
}
上面的代码,若没有内存屏障,CPU0中,可能会先将b=1写入主存,从而导致CPU1中的读a时,a的值仍然为0。当插入StoreStore屏障后,确保了b=1时a肯定也是1,但如果CPU1中没有插入LoadLoad仍然会导致a读到的是旧值(a=0), 所以也需要LoadLoad读屏障,保证a读到的是最新值a = 1。
LoadStore
LoadStore相对 LoadLoad 和 StoreStore 难理解一点,在 load1; LoadStore; store1 中,要确保在store1刷入数据对其他处理器可见前,load1已经读到最新的数据。这种情形,比较难以用代码来表示。我们想象一下在一个缓存系统里,例如cache aside模式中,对读数据时,顺序是先查找缓存,若发现缓存中没有该数据,然后继续读数据库,读完数据库之后并装载入缓存中。写数据时,则先更新数据库,然后让缓存失效。这里,就会存在一种小概率情况就是,当读操作读完数据库并要载入缓存的时候,此时后续的写操作正好更新完数据库,并置缓存失效,在这之后读操作的数据才载入缓存,进而导致了缓存里的数据是脏数据。
同样的,把这里的数据库换成 主存 ,缓存换成CPU中的 cache ,就是 load1; LoadStore; store1 中的情形。请记住,前面说的,普通读和普通写都是有 延迟 的,即使指令执行的顺序有先后,但执行完成的顺序并不能保证有序。因此,需要 LoadStore 这个屏障指令,该指令保证读操作在确认已经加数据载入缓存后,再执行后续的写操作,防止乱序。
//初始状态a,b都为0int a = 0, int b = 0;
// CPU 0 执行 foo()
void foo(void) {
assert(a == 0);
//LoadStore;
b = 1;
}
// CPU 1 执行 bar()
void bar(void) {
while (b == 0) continue;
//LoadLoad;
assert(a == 1);
}
这里,我们假设a和b两个变量都在同一个cache line上(cache line是cpu缓存中的最小读写单位,一个cache line通常是64字节,可以存放16个int型),在CPU0中,在执行 assert(a==0) 时,会把主存中的a=0和b=0作为一个cache line载入缓存中,如果没有LoadStore屏障,会存在 b=1 的写入早于cache line(a=0,b=0)载入缓存前,先写入cache line并置为invalid,然后读操作时的cache line(a=0, b=0)载入缓存,进而导致CPU1中读到b的值永远为0,从而进入死循环。
StoreLoad
和 LoadStore 类型,需要确保 store1; StoreLoad; load1 中store1刷入数据对其他处理器可见之后,才能进行读操作。类似的,若不加屏障指令,由于普通读和普通写是延迟的,就会遇到写指令还未让缓存失效,读操作已经读取了缓存内的数据,导致了脏读。StoreLoad可以说是具备了其他三种指令的所有功能。首先需要保证store指令完成且对其他处理器可见,然后再进行读,既用到了 写屏障 又用到了 读屏障 ,所以StoreLoad是四种屏障指令里代价最高的一个。
为什么说 LoadStore 没有 StoreLoad 重呢,因为只需要保证load操作执行完再执行写操作即可,也就是写操作允许是延迟的,不需要理解刷入数据对其他处理器可见。某种程度上,在物理实现领域里, LoadLoad 类似于 LoadStore ,但由于JMM是需要跨平台的抽象,为此定义了功能完备的四种指令。
//初始状态a,b都为0int a = 0, int b = 0;
boolean isFinished = false;
// CPU 0 执行 foo()
void foo(void) {
a = 1;
//StoreLoad
if(a == 1 && b == 1) {
isFinished = true;
}
}
// CPU 1 执行 bar()
void bar(void) {
b = 1;
//StoreLoad
if(a == 1 && b == 1) {
isFinished = true;
}
}
上面的代码意图是,当执行完 a = 1 和 b = 1 两个操作后,将 isFinished 置为 true ,很明显,如果按照 as-if-serial 原则,不管是CPU0的代码先执行,还是CPU1的代码先执行,总会有一个最终会让 isFinished 为 true 。然而,如果没有 StoreLoad 屏障,即使 a = 1 和 b = 1 在后续读操作前完成,但因为不可见,CPU0读到的 b 的值仍为0,CPU1读到的 a 的值也仍为1,导致 isFinished 仍为 false 。
什么时候需要插入内存屏障?
由于内存屏障的指令代价要比普通指令高(涉及总线锁或者缓存锁),因此并不是所有的指令中间都需要插入内存屏障,在java spec中给出了每种屏障插入的时机。
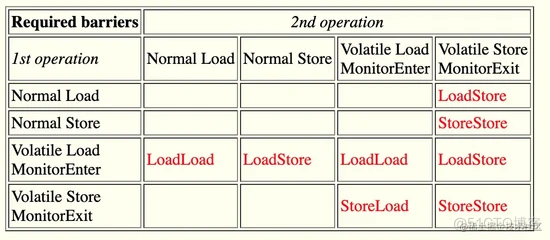
以及对应的代码举例:

物理世界中的内存屏障
在物理实现中,CPU中除了高速缓存cache外,还有StoreBuffer和InvalidQueue来加快缓存的处理实现,其大致的示意图如下:
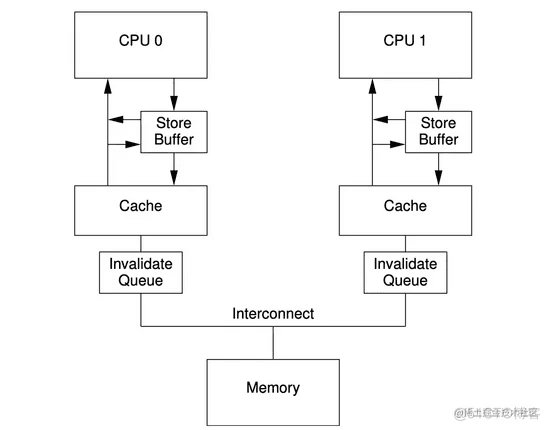
对于写操作时,为了优化写入性能,会先写入storebuffer队列中,然后发送Invalidate消息给其他CPU,待收到ack后,再把数据刷入到cache line中;同样,为了加速invalidate的ack回复,cpu会把所有invalidate消息保存在InvalidateQueue中,但需要的时候通过清空InvalidateQueue来更新cache line。
为了避免单个CPU核的写读顺序问题,读的时候会优先从storebuffer中获取数据,确保单核内部数据是一致的。
由于storebuffer和invalidateQueue的存在,导致了读和写都是有延迟的,无法直接写入缓存或者从缓存中读取最新值。为此,CPU中提供了读屏障和写屏障,其中读屏障会把InvalidateQueue中的消息清空,让对应的Cache Line直接失效,从而确保读到的都是最新值。写屏障则是直接flush storebuffer中的数据,直接全部写入cache中。
以上是CPU Cache工作的一个简化示意图,真实的CPU要比这个复杂的多,由于JMM是要解决跨平台兼容的,因此,把四种屏障指令与物理世界进行了对应:
从图中看到,在x86体系中,除了 StoreLoad 外,其他三个指令都是 no-op ,这是为什么呢?其原因是,x86的CPU中并没有InvalidateQueue,所有的读操作都是及时的,所以不需要读屏障,也即 LoadLoad 是 no-op 了。又由于storebuffer的关系,对于 StoreStore 的写入,其本身写入storebuffer就是有序的。 LoadStore 则是因为读操作是及时的,而写操作是写入storebuffer,是延迟的,所以确保了load操作一定在store之前了。所以唯一需要解决的就是 StoreLoad ,因此x86中对此提供了 mfence or cpuid or locked insn 多种方式,由于 locked 是最成熟且性能更优,因此在java中 StoreLoad 的实现,用的是 locked 指令。
在Java Spec中解释了为什么JDK中用 locked 来实现 StoreLoad ,其原文是:
On x86, any lock-prefixed instruction can be used as a StoreLoad barrier. (The form used in linux kernels is the no-op lock; addl $0,0(%%esp).) Versions supporting the "SSE2" extensions (Pentium4 and later) support the mfence instruction which seems preferable unless a lock-prefixed instruction like CAS is needed anyway. The cpuid instruction also works but is slower.翻译下来就是,早期的intel处理器只支持 locked 和 cpuid 两种,后期奔腾4开始,才支持 mfence ,虽然 mfence 性能要比 locked 优秀,但为了简化以及向前兼容,所以仍然选用了 locked 。至于 cpuid 则是因为性能不如 locked 指令。
那对应 no-op 的其他三种屏障的使用是不是没有代价呢? 其实还是有的,JDK会对这三类屏障插入 no-op 指令,编译器和CPU看到 no-op 指令则不再进行指令优化(为了保证顺序性),因此也是有代价的,只是代价要比 StoreLoad 要低很多。这也从另一个角度解释了前面说的: StoreLoad 指令代价最高,并同时具备了其他三种屏障的效果。