本文导读
*RCU 的全称是(Read-Copy-Update) *,意在读写-复制-更新,在 Linux 提供的所有内核互斥的设施当中属于一种免锁机制。
一、什么是 RCU 锁
前面介绍了自旋锁、互斥锁、信号量、读写锁、req 顺序锁。读者是否发现自己突然懂了很多锁实现方案。锁也只能这样了吗?好像都是很常规的锁结构。还有没有一种方式比这些间接需要阻塞的案更强大的、不需要阻塞操作的呢?上述锁都需要被阻塞,读者应该听说过 CopyOnWrite,它就是一种以时间换空间的操作,先复制一份,然后将该副本修改完成后粘贴至来位置处。
本节的标题 rcu,它是哪几个单词的组合呢? read、copy、update ,这不就是 COW 么,先读出来,然后复制,最后更新,一个无锁结构出来了。
二、RCU 锁实现原理
1、 RCU 锁原理解析
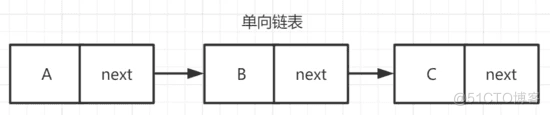
图中有一个链表操作,每个节点有两个字段,即数据字段和 next 指针字段。其中,数据字段保存数据;next 指针字段指向下一个节点。
现在有读任务 M、写任务 N 同时运行。任务 M 读取了 B 节点,任务 N 删除了 B 节点。会有以下结果。
1、无锁。当任务 M 正在读 B 时,任务 N 把 B 删除了,B 的 next 指针将为 NULL,这是不对的,因为在任务 M 读取 B 时,B 的 next 为 C,造成业务异常。
2、互斥锁。可取,当任务 M 读取链表时,可以上锁,这时任务 N 阻塞,这没问题,数据一致,然而降低了系统性能。
3、读写锁。有多个读任务时可以并行,任务 N 修改属于写者需要阻塞。看似读者性能提高了,写者却会导致饥饿状态,而且在写者操作期间,读者被阻塞。
4、seq 锁。涉及指针操作,无法使用。
以上结论就是,只能用读写锁和互斥锁。但是二者性能都不是特别好,能不能想个办法让读者直接获取锁,不像 seq 一样需要重试,也不像读写锁和互斥锁一样,读写完全互斥。于是,任务就开始着手考虑这个问题了。
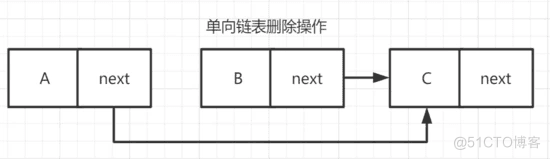
通过链表操作我们可以观察到一件事,读任务 M 在读取 B 时,写任务 N 删除 B,这意味着需要断开 B 节点的 next 指针,然后修改 A 节点的 next 指针指向 C。那么,如果在读任务 M 操作完成后再删除 B 节点是否可行。也就是说,先修改 A 节点的 next 指针为 C 节点,同时保留 B 节点,注册一个 callback,等读任务 M 用完 B 节点后,直接删除 B 节点即可。
2、ruc 锁内核源码解析
ruc 锁营运而生,对于之前需要 B 节点状态的所有任务均不影响,而对于 N 务修改之后的状态这是正确的逻辑。所以这种做法是可取的。
// 定义一个foo 的结构,包含a、b、c 3个变量struct foo {
int a;
char b;
long c;
}
DEFINE_SPINLOCK(foo_mutex); // 定义一个自旋锁
struct foo *gbl_foo; // 定义结构体指针
void foo_update_a(int new_a) { // 更新a变量
struct foo *new_fp;
struct foo *old_fp;
new_fp=kmalloc(sizeof(*new_fp),GFP_KERNEL); // 分配foo大小的空间
spin_lock(&foo_mutex); // 上自旋锁
old_fp= gbl_foo; // 保存old foo的引用
*new_fp = *old_fp; // 将old foo 的值赋值给new foo空间内
new_fp->a =new a; // 将新值赋值给新的foo
// 给RCU保护的指针也就是这里的全局共享的gbl_foo赋值
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex); // 释放自旋锁
// 等待所有读任务完成,也即等待所有CPU核都完成一次任务抢占
synchronize_kernel();
kfree(old_fp); // 释放old 指针的引用
}
// 获取变量a
int foo_get_a(void) {
int retval;
rcu_read_lock(); // 上rcu读锁,本质上是禁止抢占
retval=rcu_dereference(gbl_foo)->a; // 从gbl_foo中获取a的值
rcu_read_unlock(); // 释放rcu 读锁,本质上是打开抢占
return retval;
}
上述就是完整的 rcu 锁使用例子,可以看到写任务通过 rcu_assign_pointer 来修改指针,通过 synchronize_kernel 来等待所有的读任务完成。而读任务通过 rcu_read_lock、rcu_read_unlock rcu_dereference 来上锁、解锁、获取引用值。
有没有发现这几步操作有点像垃圾回收机制?即写者修改了之前的引用统一用替换来操作,而替换过后,之前的引用由于还有读任务在用,因此不删除,等它们都结束后,写任务才删除它。那么如何判断所有读任务都完成了呢?注意看 rcu_read_lock 的操作:禁止抢占。是不是认为当所有,锁了呢?因为有释放了锁,才能开启抢占。这一段等待 CPU 的时间就称为宽限期(grace period)。
总结
rcu 锁源码可以看到写任务通过 rcu_assign_pointer 来修改指针,通过 synchronize_kernel 来等待所有的读任务完成。而读任务通过 rcu_read_lock、rcu_read_unlock rcu_dereference 来上锁、解锁、获取引用值。
【文章原创作者:美国服务器 https://www.68idc.cn 欢迎留下您的宝贵建议】