前言: 历史背景,公司使用的jenkins的cicd架构中(部署在容器云,腾讯云做的nfs的pvc存储,本地镜像较大,jenkins的插件很多,重启耗时),某次发版发现pod的cpu打到了limit限制,ansibl
前言:
历史背景,公司使用的jenkins的cicd架构中(部署在容器云,腾讯云做的nfs的pvc存储,本地镜像较大,jenkins的插件很多,重启耗时),某次发版发现pod的cpu打到了limit限制,ansible命令消耗cpu较大。查了百度,谷歌没人分享过该场景,故简单写一下原因和结论。
问题分析:
1、手动分析ansible时可以,时超时(cpu的limit已经打满)
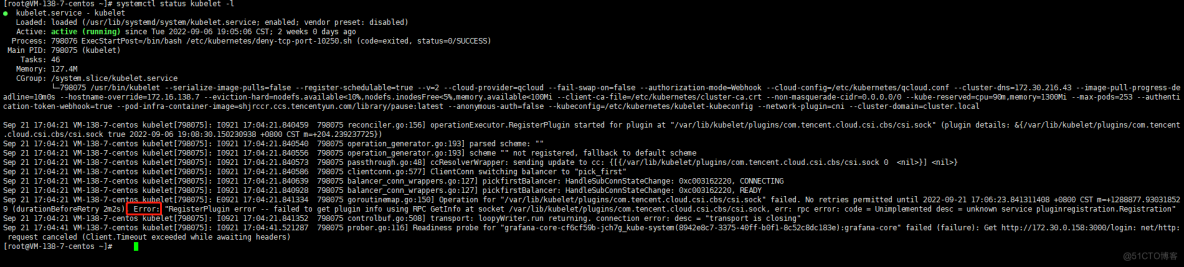
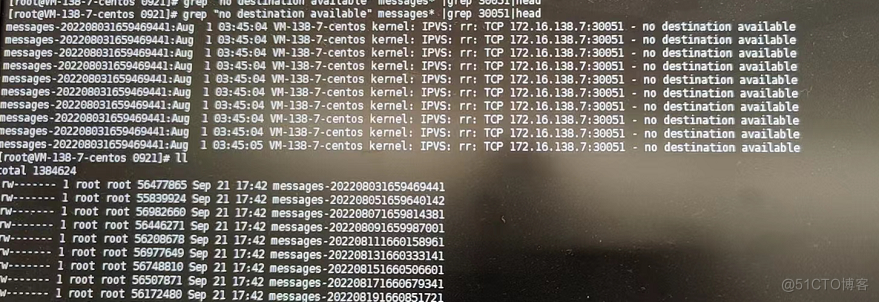
2、分析kubelet日志有csi的报错(不确定有无性能影响,数据采集给了腾讯云售后)
3、分析pod中确实是发版的ansible命令,但是cpu占用很大,分析理论不应该。
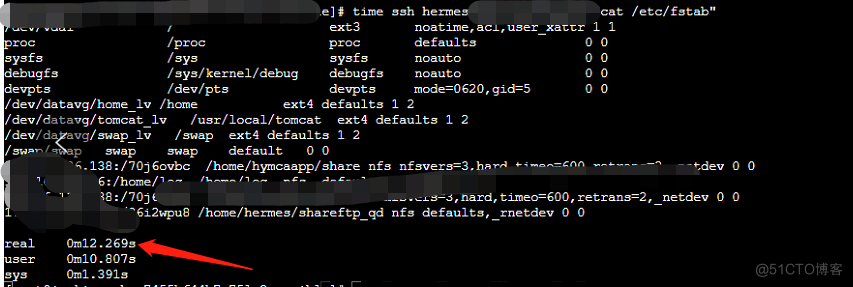
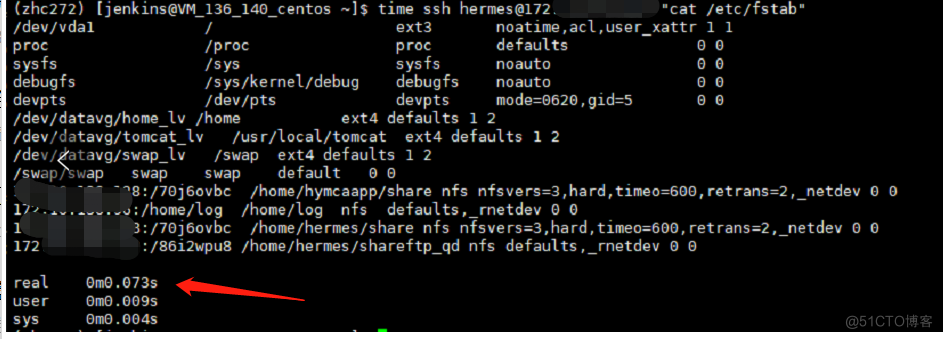
4、time命令对比pod和node,ansible命令,分别是12s和0.xx毫秒(明显出现了性能问题)
5、排查非ssh配置问题或者dns解析慢,但是kubelet有报错(会不会关联引发性能问题?)
6、对比了message的工作和jenkins上次发版记录(最早8月份就有了该报错,理论不应该是kubelet引起)
问题汇总:
1、kubelet的报错原因
2、pod中ssh耗时(12s)
问题原因:
1、kubelet后端经多方核实排查,目前判断是因为组件版本问题导致在控制台组件管理处更新一下组件版本,包括cbs,cfs,cos,升级不会对已有业务造成影响。 --抽空处理即可
2、jenkins容器中/root/.ssh/known_hosts这个配置文件占用2GB左右(原因是最初设计jenkins的架构,利用crontab追加到pod中做同用户互相) --因为认证文件1条key占比很小,故不熟悉最初部署架构的时候,还真不会想到这里。
3、当然,架构的设计,pod的大小设计,监控,应急等各方面也有问题,再慢慢优化吧(生产优先保障稳定性)