
作者:陈颖祥、杨子晗
编译:AI有道
项目地址:
https://github.com/YC-Coder-Chen/feature-engineering-handbook
本项目将探讨数据预处理部分:介绍了如何利用 scikit-learn 处理静态的连续变量,利用 Category Encoders 处理静态的类别变量以及利用 Featuretools 处理常见的时间序列变量。
目录
特征工程的数据预处理我们将分为三大部分来介绍:
- 静态连续变量
- 静态类别变量
- 时间序列变量
本文将介绍 1.2 静态类别变量的数据预处理(下部分,即1.2.7-1.2.11)。下面将结合 Jupyter,使用 sklearn,进行详解。

1.2 Static Categorical Variables 静态类别变量
真实世界的数据集还往往包含类别特征。但是由于scikit-learn中的模型只能处理数值特征,因此我们需要将类别特征编码为数值特征但是,很多新的模型开始直接提供类别变量支持,例如lightGBM和Catboost。这里我们使用category_encoders包,因为它涵盖了更多的编码方法。
1.2.7 M-estimate Encoding M估计量编码
M估计量编码是目标编码的一个简化版本。与目标编码器相比,M估计量编码仅具有一个可调参数(m),而目标编码器具有两个可调参数(min_samples_leaf和smoothing)。
公式:
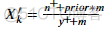
其中m为用户定义的参数;
m:m为非负数, m的值越高,先验概率的权重则更大。
????′????为类别特征X中类别k的编码值;
Prior:目标变量的先验概率/期望值;
????+:训练集中特征X类别为k,而且具有正因变量标签的样本数;
????+:训练集中具有正因变量标签的样本数;
参考文献:Micci-Barreca, D. (2001). A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems. ACM SIGKDD Explorations Newsletter, 3(1), 27-32.
import numpy as npimport pandas as pd
from category_encoders.m_estimate import MEstimateEncoder
# category_encoders 直接支持dataframe
# 随机生成一些训练集
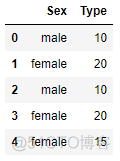
train_set = pd.DataFrame(np.array([['male',10],['female', 20], ['male',10],
['female',20],['female',15]]),
columns = ['Sex','Type'])
train_y = np.array([False, True, True, False, False])
# 随机生成一些测试集, 并有意让其包含未在训练集出现过的类别与缺失值
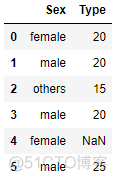
test_set = pd.DataFrame(np.array([['female',20],['male', 20], ['others',15],
['male',20],['female',40], ['male', 25]]),
columns = ['Sex','Type'])
test_set.loc[4,'Type'] = np.nantrain_set # 原始训练集
handle_unknown='value',
handle_missing='value').fit(train_set,train_y) # 在训练集上训练
encoded_train = encoder.transform(train_set) # 转换训练集
encoded_test = encoder.transform(test_set) # 转换测试集
# handle_unknown 和 handle_missing 被设定为 'value'
# 在目标编码中,handle_unknown 和 handle_missing 仅接受 ‘error’, ‘return_nan’ 及 ‘value’ 设定
# 两者的默认值均为 ‘value’, 即对未知类别或缺失值填充训练集的因变量平均值
encoded_test # 编码后的变量数与原类别变量数一致
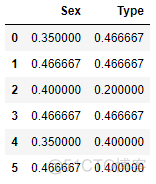
y_positive = 2 # 在训练集中,共有两个样本有正的因变量标签
n_positive = 1 # 在训练集中,共有两个样本在变量‘Sex’中有‘male’标签,在两个样本中仅有一个有正的因变量标签
prior = train_y.mean() # 训练集因变量先验概率
m = 1.0 # 默认值
male_encode = (n_positive + prior * m)/(y_positive + m)
male_encode # return 0.4666666666666666,与要验证的值吻合
0.4666666666666666
encoded_train # 训练集结果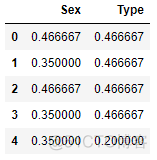
1.2.8 James-Stein Encoder James-Stein 编码
James-Stein编码也是一种基于目标编码的编码方法。与M估计量编码一样,James-Stein编码器也尝试通过参数B来平衡先验概率与观测到的条件概率。但与目标编码与M估计量编码不同的是,James-Stein编码器通过方差比而不是样本大小来平衡两个概率。
James-Stein编码可使用独立方法,合并方法等多种方法来估计参数B。有关更多信息,请参阅category_encoders官方网站:
http://contrib.scikit-learn.org/categorical-encoding/jamesstein.html
James-Stein编码假定服从正态分布。因此为了满足所需的假设,Category Encoders默认使用对数比来转换二分类问题。
独立方法的公式:
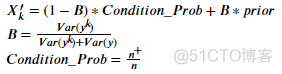
其中,
????′????是类别特征X中类别k的编码值;
先验概率:目标变量的先验概率/期望值;
????+:在训练集中,在类别特征X上的标签为k且具有因变量正标签的样本数;
????: 在训练集中,在类别特征X上标签为k的样本数;
????????????(????????):训练集中,在特征X上标签为k的样本因变量方差;
????????????(????):总体因变量的方差;
????????????(????????)和????????????(????)都应通过样本统计数据进行估算。
从直觉的角度来讲,B起到来平衡先验概率与观测到的条件概率的作用,若条件概率的均值不可靠(y_k具有高方差),则我们应当对先验概率赋予更大的权重。
import numpy as npimport pandas as pd
from category_encoders.james_stein import JamesSteinEncoder
# category_encoders 直接支持dataframe
# 随机生成一些训练集
train_set = pd.DataFrame(np.array([['male',10],['female', 20], ['male',10],
['female',20],['female',15]]),
columns = ['Sex','Type'])
train_y = np.array([False, True, True, False, False])
# 随机生成一些测试集, 并有意让其包含未在训练集出现过的类别与缺失值
test_set = pd.DataFrame(np.array([['female',20],['male', 20], ['others',15],
['male',20],['female',40], ['male', 25]]),
columns = ['Sex','Type'])
test_set.loc[4,'Type'] = np.nantrain_set # 原始训练集
handle_unknown='value',
model='independent',
handle_missing='value').fit(train_set,train_y) # 在训练集上训练
encoded_train = encoder.transform(train_set) # 转换训练集
encoded_test = encoder.transform(test_set) # 转换测试集
# handle_unknown 和 handle_missing 被设定为 'value'
# 在目标编码中,handle_unknown 和 handle_missing 仅接受 ‘error’, ‘return_nan’ 及 ‘value’ 设定
# 两者的默认值均为 ‘value’, 即对未知类别或缺失值填充训练集的因变量平均值
encoded_test # 编码后的变量数与原类别变量数一致
# 因为在category_encoders中,其对前文所述的公式做了一些修改,故此处不会进一步验证结果
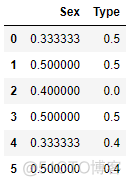
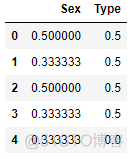
1.2.9 Weight of Evidence Encoder 证据权重编码
与上述方法类似,证据权重编码器也是根据类别变量与因变量的关系对分类变量进行编码。
公式:

以上是WoE的原始定义,但在category_encoders中,它还增加了正则项以应对过拟合。带正则项的 ????????????????????????????????????????????????_????????_???????????????????????????????? , ????????????????????????????????????????????????_????????_???????????????????????????????? 如下所示:
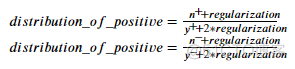
import pandas as pd
from category_encoders.woe import WOEEncoder
# category_encoders 直接支持dataframe
# 随机生成一些训练集
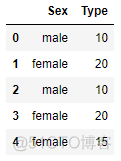
train_set = pd.DataFrame(np.array([['male',10],['female', 20], ['male',10],
['female',20],['female',15]]),
columns = ['Sex','Type'])
train_y = np.array([False, True, True, False, False])
# 随机生成一些测试集, 并有意让其包含未在训练集出现过的类别与缺失值
test_set = pd.DataFrame(np.array([['female',20],['male', 20], ['others',15],
['male',20],['female',40], ['male', 25]]),
columns = ['Sex','Type'])
test_set.loc[4,'Type'] = np.nantrain_set # 原始训练集
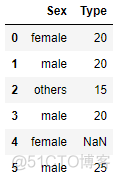
handle_unknown='value',
handle_missing='value').fit(train_set,train_y) # 在训练集上训练
encoded_train = encoder.transform(train_set) # 转换训练集
encoded_test = encoder.transform(test_set) # 转换测试集
# handle_unknown 和 handle_missing 被设定为 'value'
# 在目标编码中,handle_unknown 和 handle_missing 仅接受 ‘error’, ‘return_nan’ 及 ‘value’ 设定
# 两者的默认值均为 ‘value’, 即对未知类别或缺失值填充训练集的因变量平均值
encoded_test # 编码后的变量数与原类别变量数一致
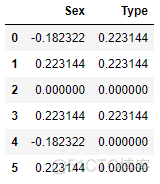
y = 5 # 训练集中一共有5个样本
y_positive = 2 # 训练集中2个样本有正标签
n = 2 # 训练集中有2个样本在Sex变量上有‘male’ 标签
n_positive = 1 # 这两个样本中仅有一个有正标签
regularization = 1.0 # 默认值
dis_postive = (n_positive + regularization) / (y_positive + 2 * regularization)
dis_negative = (n - n_positive + regularization) / (y - y_positive + 2 * regularization)
male_encode = np.log(dis_postive / dis_negative)
male_encode # return 0.22314355131420976,与要验证的值吻合
0.22314355131420976
encoded_train # 训练集结果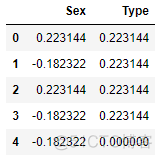
1.2.10 Leave One Out Encoder 留一法编码
留一法编码器通过组因变量均值对每个组进行编码。此处组指的是类别变量中的不同类别。
留一法同时考虑了过拟合问题,训练集中的每一个样本的编码值是除去该样本后的组因变量均值。因此,在训练集中,其可以将处于相同组的每个样本编码为不同的值。
留一法以不同的方式对测试集进行编码。测试集中的每个样本均由训练集中的组均值编码,计算过程中没有考虑去除该样本。
公式:
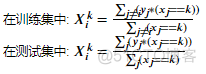
此处,若样本j拥有k标签,则( ????????==???? )返回1,否则返回0
???????????? 为样本i的标签为k情形下的编码值
import numpy as npimport pandas as pd
from category_encoders.leave_one_out import LeaveOneOutEncoder
# category_encoders 直接支持dataframe
# 随机生成一些训练集
train_set = pd.DataFrame(np.array([['male',10],['female', 20], ['male',10],
['female',20],['female',15]]),
columns = ['Sex','Type'])
train_y = np.array([False, True, True, False, False])
# 随机生成一些测试集, 并有意让其包含未在训练集出现过的类别与缺失值
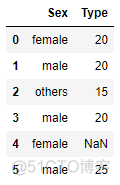
test_set = pd.DataFrame(np.array([['female',20],['male', 20], ['others',15],
['male',20],['female',40], ['male', 25]]),
columns = ['Sex','Type'])
test_set.loc[4,'Type'] = np.nantrain_set # 原始训练集
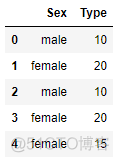
handle_unknown='value',
handle_missing='value').fit(train_set,train_y) # 在训练集上训练
encoded_train = encoder.transform(train_set) # 转换训练集
encoded_test = encoder.transform(test_set) # 转换测试集
# handle_unknown 和 handle_missing 被设定为 'value'
# 在目标编码中,handle_unknown 和 handle_missing 仅接受 ‘error’, ‘return_nan’ 及 ‘value’ 设定
# 两者的默认值均为 ‘value’, 即对未知类别或缺失值填充训练集的因变量平均值
encoded_test # 编码后的变量数与原类别变量数一致
# 结果可见,所有类别值都被编码为训练集中的类别因变量均值
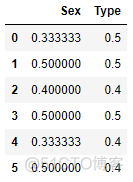
LeaveOneOutEncoder(cols=['Sex','Type'],
handle_unknown='value',
handle_missing='value').fit_transform(train_set,train_y)
# 进行小验算:
# 对第一个样本而言,其在Sex变量上的标签为‘male’
# 除去该样本后,‘male’标签样本的因变量平均值为1.0 (仅剩样本3有‘male’标签,且其有正的因变量标签)
# 同理,对第三个同样有‘male’标签的样本,除去它后标签样本的因变量平均值变为了0.0
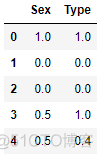
1.2.11 Catboost Encoder Catboost 编码
CatBoost是一个基于树的梯度提升模型。其在包含大量类别特征的数据集问题中具有出色的效果。该模型针对分类特征提出了一种基于“留一法编码器”的新编码系统。在使用Catboost编码器之前,必须先对训练数据随机排列,因为在Catboost中,编码是基于“时间”的概念,即数据集中观测值的顺序。
公式:
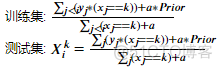
其中,若样本j拥有k标签,则( ????????==???? )返回1,否则返回0
???????????? 为样本i的标签为k情形下的编码值
Prior 为因变量的先验概率/期望值
a为正则化系数
import numpy as npimport pandas as pd
from category_encoders.cat_boost import CatBoostEncoder
# category_encoders 直接支持dataframe
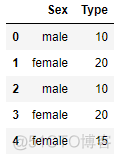
# 随机生成一些训练集
train_set = pd.DataFrame(np.array([['male',10],['female', 20], ['male',10],
['female',20],['female',15]]),
columns = ['Sex','Type'])
train_y = np.array([False, True, True, False, False])
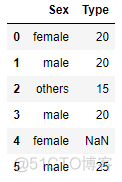
# 随机生成一些测试集, 并有意让其包含未在训练集出现过的类别与缺失值
test_set = pd.DataFrame(np.array([['female',20],['male', 20], ['others',15],
['male',20],['female',40], ['male', 25]]),
columns = ['Sex','Type'])
test_set.loc[4,'Type'] = np.nantrain_set # 原始训练集
# 但由于我们的数据本身已经是随机生成的,故无需打乱
encoder = CatBoostEncoder(cols=['Sex','Type'],
handle_unknown='value',
handle_missing='value').fit(train_set,train_y) # 在训练集上训练
encoded_train = encoder.transform(train_set) # 转换训练集
encoded_test = encoder.transform(test_set) # 转换测试集
# handle_unknown 和 handle_missing 被设定为 'value'
# 在目标编码中,handle_unknown 和 handle_missing 仅接受 ‘error’, ‘return_nan’ 及 ‘value’ 设定
# 两者的默认值均为 ‘value’, 即对未知类别或缺失值填充训练集的因变量平均值
encoded_test # 编码后的变量数与原类别变量数一致
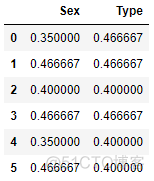
Prior = train_y.mean() # 先验概率
n = 2 # 在训练集中,两个样本在Sex变量上具有‘male’标签
n_positive = 1 # 这两个样本中,仅有一个拥有正标签
a = 1 # 正则化系数, 默认值为1
encoded_male = (n_positive + a * prior) / (n + a)
encoded_male # return 0.4666666666666666,与要验证的值吻合
0.4666666666666666
# 验证一下训练集的结果CatBoostEncoder(cols=['Sex','Type'],
handle_unknown='value',
handle_missing='value').fit_transform(train_set,train_y)
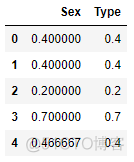
Prior = train_y.mean() # 先验概率
n = 1 # 在第三个样本前仅有一个样本有‘male’标签
n_positive = 0 # 这仅有的一个样本没有正标签
a = 1 # 正则化系数
encoded_male = (n_positive + a * Prior) / (n + a)
encoded_male # return 0.2
0.2
好了,以上就是关于静态类别变量(下部分)的数据预处理介绍。建议读者结合代码,在 Jupyter 中实操一遍。
目前该项目完整中文版正在制作中,请持续关注哦~
中文版 Jupyter 地址:
https://github.com/YC-Coder-Chen/feature-engineering-handbook/blob/master/1.%20Data%20Preprocessing.ipynb