一、Pandas 简介
Pandas是使用Python语言开发的用于数据处理和数据分析的第三方库。它擅长处理数字型数据和时间序列数据,当然文本型的数据也能轻松处理。 Pandas 可以处理的数据格式非常多,常见的数据文件格式都可以快速导入,比如 CSV、JSON、SQL、Microsoft Excel 导入数据。 由于Pandas对数据的强大处理能力,被广泛的应用于金融,数据处理等方面,是大家学习数据处理时,不可避免的存在;如果想要学好数据处理,就一起来学习Pandas吧!!! 总结:Pandas 在数据处理方面很强大!封装了我们常用的功能,直接调用相关的函数即可,省去了我们很多工作,让我们一起好好学习Pandas吧!
二、Pandas 数据结构
Pandas 的主要数据结构有两种,分别是: Series (一维数据)与 DataFrame(二维数据);所以后面的内容也是围绕着这两部门展开的;
2.1 Series (一维数据)
似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。即:Series 与Numpy 数组基本是一样的,只不过多了数据标签(索引);
Series 格式: pandas.Series( data, index, dtype, name, copy)
参数说明:
参数 解释说明 data 一组数据(ndarray 类型) ,即Numpy数据; index 数据索引标签,如果不指定,默认从 0 开始。 dtype 数据类型,默认会自己判断。 name 设置名称。(不常用) copy 拷贝数据,默认为 False。(不常用)Series 举例:
import pandas as pd a = ['x','y','z'] b = [1,2,3] mynum1 = pd.Series(b) print(mynum1) # 0 1 # 1 2 # 2 3 mynum2 = pd.Series(b,index=a) print(mynum2) # x 1 # y 2 # z 3 # dtype: int64 mynum3 = pd.Series(b,index=a,dtype=float) print(mynum3) # x 1.0 # y 2.0 # z 3.0 # dtype: float64注意事项:
2.2 DataFrame(二维数据)
类似于二维数组的对象,是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引;可以当作是许多个共用同一个索引的Series组成的数据结构;DataFrame 图解如下:
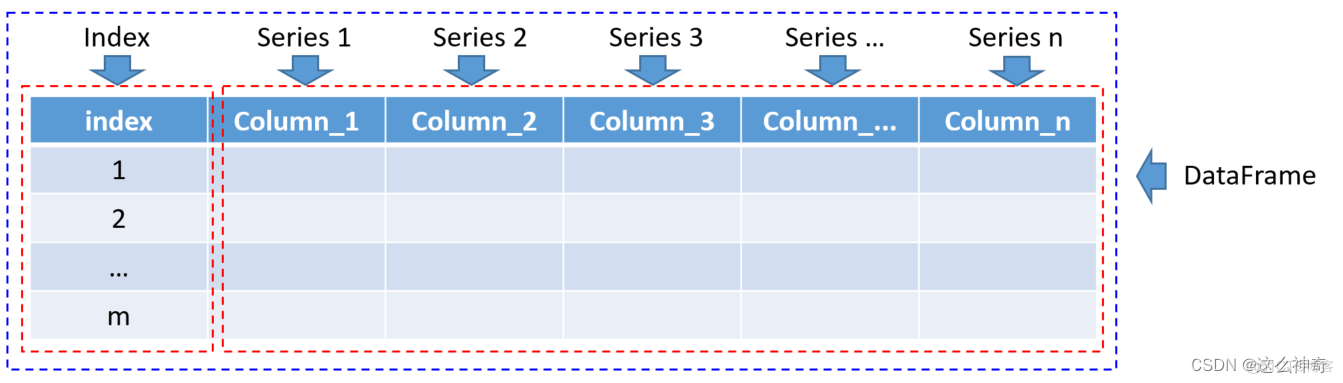 上图所表示的就是一个由n 个Series组成的DataFrame; 所有的Series 共享同一个Index ;
上图所表示的就是一个由n 个Series组成的DataFrame; 所有的Series 共享同一个Index ;
DataFrame 格式:pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
参数 解释说明 data 一组数据(ndarray 类型) ,即Numpy数据; index 数据索引标签,也可称为行标签 columns 数据列标签,如果不指定,默认从 0 开始。也可称为列标签。 dtype 数据类型,默认会自己判断。 copy 拷贝数据,默认为 False。(不常用)三、Series 的创建
3.1 由数创建
不指定Index的时候,用单个数值只能创建一个元素的Series;
mySer = pd.Series(2) print(mySer) # 0 2 # dtype: int64通过指定Index 可以生成多个相同元素的Series,举例如下:
mySer = pd.Series(2,index=range(3)) print(mySer) # 0 2 # 1 2 # 2 2 # dtype: int643.2 由列表创建
当不指定Index的时候,会默认生成RangeIndex(start=0, stop=n-1, step=1)的Index; 举例如下:
lis = [3,4,5] mySer = pd.Series(lis) print(mySer) # 0 3 # 1 4 # 2 5 # dtype: int64 print(mySer.index) # RangeIndex(start=0, stop=3, step=1) print(mySer.values) # [3 4 5]也可以指定Index, 举例如下:
lis = [3,4,5] ind = ["马里奥","路易吉","林克"] mySer = pd.Series(lis,index=ind) print(mySer) # 马里奥 3 # 路易吉 4 # 林克 5 # dtype: int64 print(mySer.index) # Index(['马里奥', '路易吉', '林克'], dtype='object') print(mySer.values) # [3 4 5]