

即将迎来了2019世界人工智能大会,相信这个会议又一次推动人工智能的发展,有兴趣的同学可以去参加感受一下人工智能的热度,绝不会低于这个夏天的高温。
今天“计算机视觉战队”为大家分析一个关于人脸检测识别!
1
导 读
大量带注释的数据集和可承受的计算效率的可用性导致了令人印象深刻的改进CNNs对各种物体检测和识别基准的性能。这些,以及对深度的更好理解学习方法也导致了机器对面部的理解的能力。CNNs能够检测面部、定位面部关键点、估计姿势和识别不受约束的图像和视频中的人脸。
今天要说的,就是详细描述了一种用于无约束人脸识别和验证的深度学习流水线,它在几个基准数据集上达到了最先进的性能。提出了一种新的人脸检测、深度金字塔单镜头人脸检测器(DPSD),该检测器是一种快速、有能力的人脸检测器。用于检测具有大尺度变化(尤其是微小表面)的人脸。给出了在自动中涉及的各个模块的设计细节人脸识别:人脸检测、关键点定位和对齐以及人脸识别/验证。
提供评估结果提出了一种具有挑战性的无约束人脸检测数据集的人脸检测器。然后,给出了IARPA的实验结果。Janus基准A、B和C(IJB-A、IJB-B、IJB-C)和Janus挑战集5(CS5)。
1
背景及现状
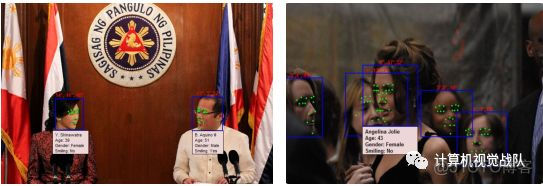
人脸分析是研究的一个活跃领域。它涉及提取诸如关键点、姿势、表情、性别、年龄、身份等的信息。它有若干应用,包括执法、设备的主动认证、支付的面部生物识别、自驾驶车辆等。
人脸识别和验证系统通常有三个模块。首先,需要一种用于在图像中定位人脸的人脸检测器。人脸检测器的理想特性是对姿态、光照和尺度的变化具有鲁棒性。此外,一个好的人脸检测器应该能够输出一致和良好的位置边界框。第二个模块定位面部关键点,如眼睛中心、鼻尖、嘴角、耳垂尖等。这些标志被用来对齐面部,减轻平面内旋转和缩放的影响。第三,特征提取器在高维描述中对身份信息进行编码,然后使用这些描述符来计算两个面之间的相似度。有效的特征提取器需要对流水线中先前的步骤所带来的错误具有鲁棒性:人脸检测、关键点定位和人脸对齐。


人脸检测

人脸检测是任何人脸识别/验证过程中的第一步。人脸检测算法通常以边界框的形式输出给定输入图像中所有人脸的位置。人脸检测器需要对姿态、光照、视点、表情、比例、肤色、某些遮挡、伪装、化妆等方面的变化具有鲁棒性,最近基于DCNN的人脸检测器受到一般目标检测方法的启发。cnn检测器可分为两个子类别:1)基于区域的检测器,2)基于滑动窗口的检测器。
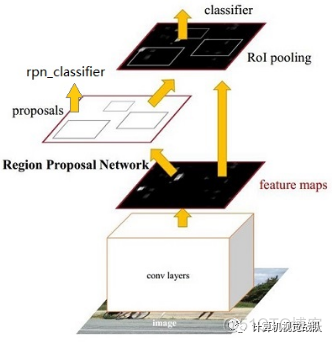
- 基于区域的方法首先生成一组目标候选,并使用CNN分类器将每个候选分类为人脸或非人脸。第一步通常是现成的候选生成器,如选择性搜索[J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders, “Selective search for object recognition,” International journal of computer vision, vol. 104, no. 2, pp. 154–171, 2013.]。最近使用这种方法的一些检测器是HyperFace[R. Ranjan, V. Patel, and R. Chellappa, “Hyperface: A deep multitask learning framework for face detection, landmark localization, pose estimation, and gender recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.],以及All-in-One Face[R. Ranjan, S. Sankaranarayanan, C. D. Castillo, and R. Chellappa, “An all-in-one convolutional neural network for face analysis,” IEEE International Conference on Automatic Face and Gesture Recognition (FG), 2017]。Faster RCNN[S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” in Advances in neural information processing systems, 2015, pp. 91–99]使用区域候选网络(RPN),而不是用一般的方法生成对象候选。同样,[Y. Li, B. Sun, T. Wu, and Y. Wang, “Face detection with end-to-end integration of a convnet and a 3d model,” European Conference on Computer Vision (ECCV), 2016]提出了一种基于Faster RCNN框架的多任务人脸检测器。Chen等人[D. Chen, G. Hua, F. Wen, and J. Sun, “Supervised transformer network for efficient face detection,” in European Conference on Computer Vision. Springer, 2016, pp. 122–138]训练了一个用于人脸检测和面部关键点定位的多任务RPN。这使他们减少了多余的人脸候选,提高了人脸目标候选的质量。
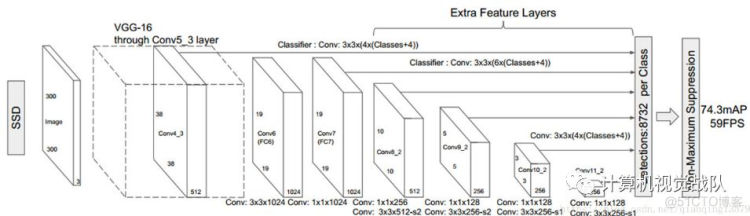
- 基于滑动窗口的方法在给定的尺度上输出特征图中每个位置的人脸检测。这些检测由人脸检测分数和边界框组成。这种方法不依赖于单独的候选生成步骤,因此比基于区域的方法要快得多。在一些方法[R. Ranjan, V. M. Patel, and R. Chellappa, “A deep pyramid deformable part model for face detection,” in Biometrics Theory, Applications and Systems (BTAS), 2015 IEEE 7th International Conference on. IEEE, 2015, pp. 1–8],[S. S. Farfade, M. J. Saberian, and L.-J. Li, “Multi-view face detection using deep convolutional neural networks,” in ACM on International Conference on Multimedia Retrieval(CVPR), 2015, pp. 5325–5334]多分辨率采用级联结构。单镜头检测器(SSD)[W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in European Conference on Computer Vision (ECCV), 2016, pp. 21–37]也是一种基于多尺度滑动窗口的目标检测器,然而它没有使用目标金字塔进行多尺度处理,而是利用了深层CNN的层次结构性质。像ScaleFace[S. Yang, Y. Xiong, C. C. Loy, and X. Tang, “Face detection through scale-friendly deep convolutional networks,” arXiv preprint arXiv:1706.02863, 2017]和S3FD[S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li, “s3 fd: Single shot scale-invariant face detector,” arXiv preprint arXiv:1708.05237, 2017]这样的方法使用类似的技术进行人脸检测。
人脸关键点检测与头部定位
人脸关键点包括眼睛的角、鼻尖、耳叶口角等。需要这些来进行表面对准,其对于人脸识别/验证非常重要。头部姿势另一个重要的利益信息。人脸关键点检测方法可分为两个类型:基于模型和基于回归。
基于模型的方法在训练过程中创建形状的表达,在测试过程中使用该方法来配合人脸。基于模型的方法包括:PIFA和3DDFA。Jurabloo等人考虑人脸对齐作为密集3D模型拟合问题并使用用于估计相机的基于DCNN的正则表达式的级联投影矩阵和3D形状参数。Antonakos等人使用基于多个图形的成对法线建模的外观修补程序之间的分布。基于级联回归的方法将图像外观直接映射到目标输出。Zhang等人使用了级联,几个连续的堆叠自编码器网络。该方法细化从第一个堆叠中获得的粗略位置使用后续网络的自动编码器网络。Bulat等人。还首先对每个人脸关键点进行粗略定位,然后对其进行细化检测结果。同样,Sun公司提出的方法[Y. Sun, X. Wang, and X. Tang, “Deep convolutional network cascade for facial point detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 3476–3483]每个级别的多个网络的融合输出级联。
另一种方法基于回归是级联组成学习(CCL)[S. Zhu, C. Li, C.-C. Loy, and X. Tang, “Unconstrained face alignment via cascaded compositional learning,” in IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3409–3417]。库马尔提出了一种用于关键点估计的迭代方法和姿势预测。Georgis等人提出的方法联合训练一个卷积递归神经网络。在另一项工作中,Kumar等人[A. Kumar, R. Ranjan, V. Patel, and R. Chellappa, “Face alignment by local deep descriptor regression,” arXiv preprint arXiv:1601.07950, 2016]开发了一种用于关键点定位的CNN。
300 Faces In-the-Wild database(300W)[C. Sagonas, E. Antonakos, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic, “300 faces in-the-wild challenge: Database and results,” Image and Vision Computing, vol. 47, pp. 3–18, 2016]是对不同面部检测方法进行公平比较的基准。它组合并扩展了几个以前可用的数据集,LFPW、Helen、AFW、iBug和600个测试图像。

人脸识别与验证
人脸识别/ 验证系统有两个主要部分:1) 鲁棒人脸表示;2) 分类器(在识别的情况下) 或相似性度量(用于验证)。
鲁棒人脸表达
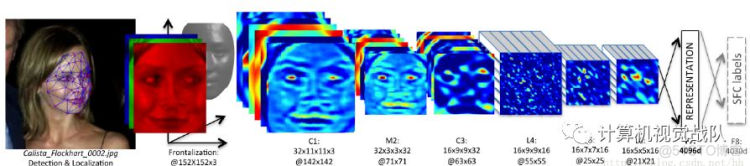
当使用大型数据集进行训练时,深度网络能够学习判别特征。[G. B. Huang, H. Lee, and E. Learned-Miller, “Learning hierarchical representations for face verification with convolutional deep belief networks,” in IEEE International Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2012, pp. 2518–2525]使用基于局部受限Boltzmann的卷积深信念网络学习人脸表示。它们的模型在LFW数据集上获得了良好的性能,而不需要大量标注的人脸数据集。另一方面,塔格曼等人使用一个由4000多个身份的400万张脸组成的专用脸数据集来训练一个九层深网络(DeepFace)[Y. Taigman, M. Yang, M. A. Ranzato, and L. Wolf, “Deepface: Closing the gap to human-level performance in face verification,” in IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1701–1708]。他们没有使用标准的卷积层,而是使用了几个局部连接的层而没有权重共享。同样,FaceNet[F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” arXiv preprint arXiv:1503.03832, 2015]也接受了关于大约800万张身份的2亿张图像的数据集的培训。它直接优化了嵌入本身,使用了大致对齐匹配/非匹配的三重人脸贴片。DeepID框架[Y. Sun, X. Wang, and X. Tang, “Deep learning face representation from predicting 10000 classes,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 1891–1898]、[Y. Sun, Y. Chen, X. Wang, and X. Tang, “Deep learning face representation by joint identification-verification,” in Advances in Neural Information Processing Systems, 2014, pp. 1988–1996]、[Y. Sun, X. Wang, and X. Tang, “Deeply learned face representations are sparse, selective, and robust,” arXiv preprint arXiv:1412.1265, 2014]使用了比DeepFace或FaceNet更小的深卷积网络集合。每个DCNN由四个卷积层组成,并接受了大约20万张大约10000个身份的图像的训练。使用一组模型和大量不同的身份有助于DeepID学习鉴别人脸表示,从而使其能够在LFW数据集上实现超人人脸验证性能。
判别度量学习
学习分类器或相似性度量是获取鲁棒人脸特征的下一步。对于人脸验证,属于同一个人的两张人脸的特征应该是相似的,而属于不同人的人脸的特征应该是不同的。

最近的一些工作提出了在训练损失函数或网络设计中编码这一要求的方法。第一种方法使用图像对来训练一个特征嵌入,其中正对更近,负对更远。Hu等人[J. Hu, J. Lu, and Y.-P. Tan, “Discriminative deep metric learning for face verification in the wild,” in IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1875–1882]使用深层神经网络学习一种判别尺度。[S. Sankaranarayanan, A. Alavi, C. Castillo, and R. Chellappa, “Triplet probabilistic embedding for face verification and clustering,” arXiv preprint arXiv:1604.05417, 2016]使用三重子损失将DCNN特征嵌入到区分子空间中。这导致了人脸验证方面的性能改进。
另一种方法是修改常用的交叉熵损失,以纳入判别约束。温等人[Y. Wen, K. Zhang, Z. Li, and Y. Qiao, “A discriminative feature learning approach for deep face recognition,” in European Conference on Computer Vision (ECCV), 2016, pp. 499–51]介绍了学习判别人脸嵌入的中心损失。Ranjan等人介绍了crystal loss[R. Ranjan, A. Bansal, H. Xu, S. Sankaranarayanan, J.-C. Chen, C. D. Castillo, and R. Chellappa, “Crystal loss and quality pooling for unconstrained face verification and recognition,” arXiv preprint arXiv:1804.01159, 2018],它在Softmax损失之前使用了特征归一化和缩放。类似地,DeepVisage[M. A. Hasnat, J. Bohne, J. Milgram, S. Gentric, and L. Chen, “Deepvis- ´ age: Making face recognition simple yet with powerful generalization skills.” in ICCV Workshops, 2017, pp. 1682–1691]使用批处理规范化的特例来规范这些特性。SphereFace[W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song, “Sphereface: Deep hypersphere embedding for face recognition,” IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2017]提出的angular softmax,它产生角分辨特征。CosFace[H. Wang, Y. Wang, Z. Zhou, X. Ji, Z. Li, D. Gong, J. Zhou, and W. Liu, “Cosface: Large margin cosine loss for deep face recognition,” arXiv preprint arXiv:1801.09414, 2018]L2对特征和权重进行归一化以消除径向变化,并引入余弦裕度项来最大化角空间中的决策裕度。
Implementation
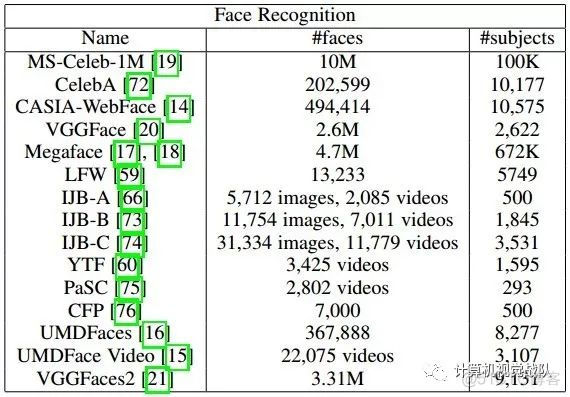
获取判别性和鲁棒性特征对于人脸识别和验证都具有重要意义。对于人脸验证,给定一对人脸,使用相似性度量对这两个人脸特征进行比较。L2距离和余弦相似度是比较两种人脸特征表示最常用的度量方法。为了进行识别,将给定探针人脸的特征与大型图片库进行比较,最相似的图片库人脸给出了探测面的标识。为了获得鲁棒性特征,可以利用DCNN的集合来提取不同的人脸表示,然后将其融合成单一的鲁棒表示。深度网络非常需要数据,有几个公开可用的人脸数据集,可以用来训练深层网络的人脸识别和验证。下表显示了其中一些数据集的详细信息。
预处理和模型/数据集的选择是在训练人脸识别系统之前需要做出的非常重要的决定。最近,Bansal等人研究了这类决定的好做法和坏做法。他们试图回答以下问题:(1)我们能否对静止图像进行训练,并期望系统能够处理视频?(2)如果给定一组图像,更深的数据集意味着每个主题的图像更多,而更宽的数据集意味着更多的主题?(3)添加标签噪声会导致深层网络性能的提高吗?(4)人脸识别需要对齐吗?他们从本质上证明了使用干净的训练数据、良好的人脸对齐以及结合静止图像和视频帧训练深层网络的重要性。
A. Bansal, C. D. Castillo, R. Ranjan, and R. Chellappa, “The do’s and don’ts for cnn-based face verification,” arXiv preprint arXiv:1705.07426, 2017.

今天暂时将人脸的相关分享到此,下一期我们继续分享,并详细给大家讲解精准的人脸检测、识别和验证系统框架,有兴趣的同学请持续关注“计算机视觉战队”!
