
计算机视觉研究院专栏
作者:Edison_G
NVIDIA发布其首款基于Arm架构的数据中心CPU处理器,在最复杂的AI和高性能计算工作负载下,可实现10倍于当今最快服务器的超高性能。


4月12日晚,英伟达GTC 2021大会在线上开始了。

「这是世界第一款为terabyte级别计算设计的CPU」在GTC大会上,黄仁勋祭出了英伟达的首款中央处理器Grace,其面向超大型AI模型的和高性能计算。
先来说下优点:

NVIDIA创始人兼首席执行官黄仁勋表示:“前沿的AI和数据科学正推动当今的计算机架构超越其极限,以处理规模难以想象的海量数据。NVIDIA借助Arm授权的 IP设计了Grace,这是一款专为大规模AI和HPC设计的CPU。与GPU和DPU一起, Grace为我们提供了计算的第三种基础技术,以及为了推进AI发展重构数据中心的能力。NVIDIA现在是一家拥有三种芯片的公司。”



NVIDIA利用Arm数据中心架构极大的灵活性构建了Grace。通过推出新的服务器级 CPU,NVIDIA正在推进在AI和HPC领域中技术多样性的目标。在这些领域,更多选择是实现解决全球最迫切问题所需创新的关键。

Arm首席执行官Simon Segars表示:“作为全球授权范围最广的处理器架构,Arm 每天正在以不可思议的新方式推动创新。NVIDIA 推出Grace 数据中心 CPU 明确表明Arm的授权模式如何促进一项重要创新,这将进一步支持世界各地 AI 研究人员和科学家们非凡的工作。”
Grace的首批使用者推动科学和AI的极限发展
CSCS和洛斯阿拉莫斯国家实验室计划将于2023年推出由慧与构建的、搭载Grace的超级计算机。
CSCS总监Thomas Schulthess教授表示:“利用 NVIDIA全新的Grace CPU,使得我们能将AI技术和传统的超级计算融合在一起,来解决计算科学领域一些最难的问题。我们很高兴能够向我们的瑞士和全球用户提供这款全新NVIDIA CPU,用于处理分析海量和复杂的科学数据集。”
洛斯阿拉莫斯国家实验室主任Thom Mason表示:“通过创新地平衡内存带宽和容量,新一代系统将重塑我们机构的计算策略。凭借NVIDIA全新Grace CPU,我们可以在比以前更大的数据集上完成高逼真度3D仿真和分析,从而进行先进的科学研究工作。”
实现性能突破
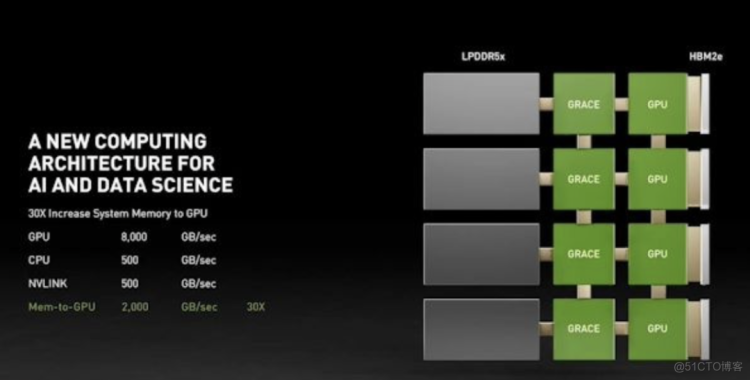
Grace的强大性能基于第四代NVIDIA NVLink® 互联技术,该技术在Grace和NVIDIA GPU之间提供创纪录的900 GB/s连接速度,使总带宽比当今领先的服务器高 30 倍。
Grace还将利用创新的LPDDR5x内存子系统,该子系统的带宽是DDR4内存的两倍,能效达DDR4的10倍。此外,新架构提供单一内存地址空间的缓存一致性,将系统和HBM GPU内存相结合,以简化可编程性。
Grace将获得NVIDIA HPC软件开发套件以及全套CUDA® 和 CUDA-X™ 库的支持,可以对2,000多个 GPU应用程序加速,使得应对全球重大挑战的科学家和研究人员探索速度更快。
预计将于2023年初开始供货。
再来说说缺点:
鉴于目前Grace还处于PPT阶段,在发布会上,技术上也只是提到了LPDDR5x和NVIDIA NVLink 这些比较不怎么让人意外的技术,那我们可以从市场方面简单聊一聊。
「Grace是一款高度专业化的处理器,主要解决工作负载问题,例如训练拥有超过1万亿个参数的下一代NLP模型。当与英伟达GPU紧密结合时,基于Grace CPU的系统将比当今最先进的基于英伟达DGX的系统(运行在x86 CPU上)的性能还要快10倍。」
Grace CPU是一款服务器CPU,主要用途是数据中心,并不是消费者业务,所以它和Apple 的M1芯片定位完全不同,普通用户暂时没有不会用得到Grace CPU。对于服务器计算领域,ARM架构芯片并不是一个非常新鲜的名词,比如华为的鲲鹏,亚马逊的Graviton,Fujistu的A64FX等等。
它的定位也并不是传统的通用计算,而是用来辅助自家的GPU,来提供更有竞争力的AI数据中心解决方案。这里的内在原因是,数据中心的芯片市场已经越来越成为主流市场,消费者市场正在日渐衰弱。

计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式