作为从事爬虫工作的技术人员都知道再数据抓取的时候经常遇到获取信息慢的问题,尤其是批量多线程采集数据时尤为明显。那么通过什么样的方法才能提高采集效率呢 ?下面让我们一
作为从事爬虫工作的技术人员都知道再数据抓取的时候经常遇到获取信息慢的问题,尤其是批量多线程采集数据时尤为明显。那么通过什么样的方法才能提高采集效率呢 ?下面让我们一起了解采集慢的具体原因,以及如何应对它的方法。
首先是尽可能降低目标网站访问频率
我们都知道单次爬虫的时候多数情况下都是等待网络请求响应上,因此如果能降低网站访问次数就降低访问,这样不仅能降低自己的工作量,还能减低网站压力防止被封危险。单个线程固定地区爬取频繁很容易触发网站反爬机制。
例如第一步要做的就是对流程进行优化,把流程精简化,应规避再同一个页面频繁访问。
再接着就是去重,这件步骤同样重要,一般根据url或者id进行唯一性判别,对于爬过的就不再爬了。
其次就是分布式爬虫
当你所有方法都想过用过之后,单个线程的爬取网页数据就算再快也会达到极限。对于需要大量获取数据信息的,必须要用机器换取时间了,那就是分布式多线程并发爬取。
第一步我们要知道分布式并非是爬虫的本质,也不是必要的,对于不存在相同的任务利用不同机器爬取不同目标网站各自执行,能有效的减少机器工作量,这样能够大大的减少费时。
比如有三百万的网站需要爬取,我们可以利用多台服务器各自分配不同的网页分别爬取,相对单机来说就有效的缩短了工作时间。
再比如存在着需要通信的情况,一个变动的带爬列队,每爬一次这个队列就会发生变化,即便分割任务也就有交叉重复,因为各个机器在程序运行时的待爬队列都不一样了——这种情况下只能用分布式,一个Master存储队列,其他多个Slave各自来取,这样共享一个队列,取的情况下互斥也不会重复爬取。scrapy-redis是一款用得比较多的分布式爬虫框架。
当然如果多线程海量爬取,肯定是需要海量爬虫ip支持的。
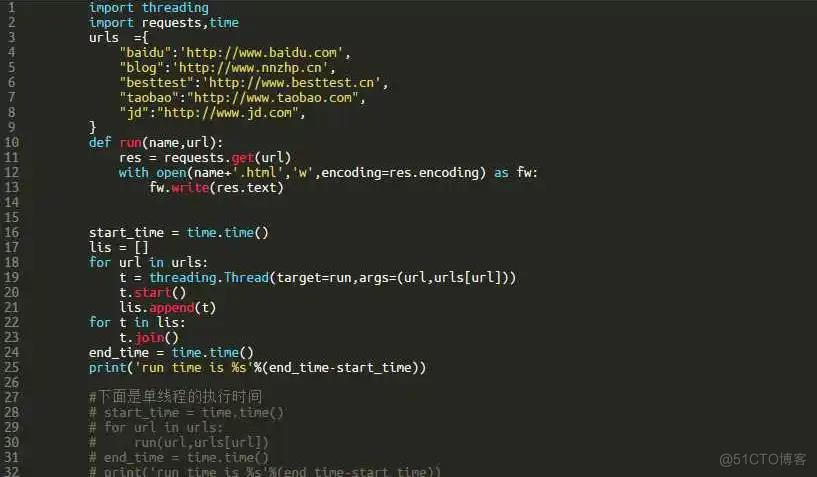
多线性爬虫代码如下:
import requestsimport threading
def fetch(url):
response = requests.get(url)
print('Get %s: %s' % (url, response))
h1 = threading.Thread(target = fetch, args = ("https://jshk.com.cn/",))
h2= threading.Thread(target = fetch, args = ("https://www.zhihu.com/",))
h3= threading.Thread(target = fetch, args = (" https://www.taobao.com/",))
h1.start()
h2.start()
h3.start()
h1.join()
h2.join()
h3.join()