上次讲了一下playwright获取网站的数据。但是吧这个playwright,他终究是一个自动化调试工具,多多少少会占一点本地的资源。
这次的Splash可不一样了,他是部署在服务器上的,可以把负载的资源放在一个甚至多个服务器上,实现在服务器上将想要请求的网站,请求加渲染,把最后的HTML返回给你,让你解析数据。
一、Splash和Splash配置
Splash是一个JavaScript的渲染服务,这是一款带有HTTP API的轻量级web浏览器,同时啊他还接入了python3的Twisted and QT5库。
Spalsh配置这里介绍下Liunx+Docker的配置,以下几步:
安装Docker,保证Docker安装的版本>=17
使用Docker拉取镜像
启动容器,开启Splash服务
1. Pull the image:2. $ sudo docker pull scrapinghub/splash
3. Start the container:
4. $ sudo docker run -it -p 8050:8050 --rm scrapinghub/splash
配置完成后,在你的浏览器输入服务器地址加端口号8050验证是否成功:
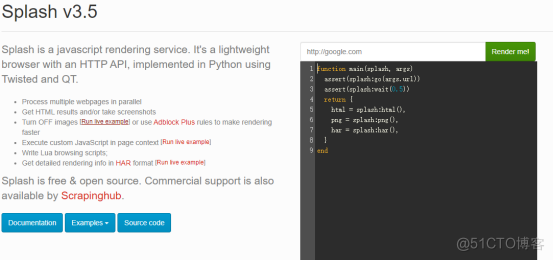
像这样你就成功了
二、Splash+requests的使用
Splash是用Lua语言写的脚本,用Lua语言模拟了浏览器加载的过程,从而返回各种结果,如网页源码,截图等。
那怎么配合python使用呢?
Splash有一个强大的接口:execute。此接口可以实现与Lua脚本的对接。当然Splash还有render接口,在此先按下不表,想要了解的话还是请自行查看文档。
1. import requests2. import json
3.
4. splashUrl = "我的splash地址:8050/execute"
5. def get_splash():
6. param = {
7. "timeout": 10,
8. "url": 'https://www.google.com/',
9. "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36",
10. "lua_source": """
11. function main(splash, args)
12. splash:go(args.url)
13. splash:wait(5)
14. splash.images_enabled = false
15. return splash:html()
16. end
17. """
18. }
19. response = requests.post(url=splashUrl, data=json.dumps(param),headers={"content-type": "application/json"})
20. print(response.text)
这里是通过requests传参数通过post请求Splash接口,而传递的param参数中不仅有splash的配置,还有lua_source中的Lua脚本。
其中这部分就是刚才浏览器中打开里面的脚本:splash go请求args传入的url连接,等待10秒不获取图片,最后返回请求后的html内容:
1. function main(splash, args)2. splash:go(args.url)
3. splash:wait(5)
4. splash.images_enabled = false
5. return splash:html()
6. end
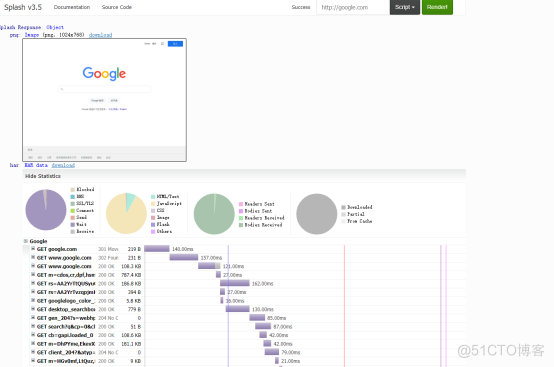
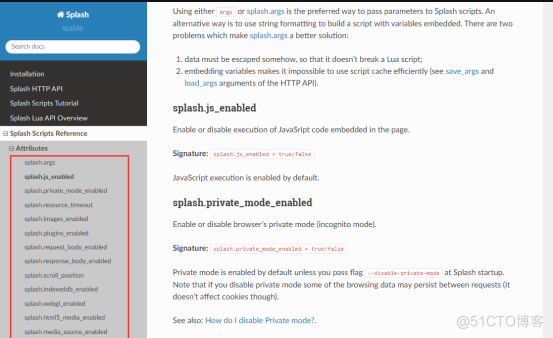
其中,在请求execute是的param传参,还可以加上其他的参数,就像里面的timeout就是设置5秒超时,什么get/post请求啦,启动或禁用图片加载啦,禁止或启用js啦都可以加上,详情请自行查询文档哦:
三、Splash+requests的代理配置
哎,Python获取内容怎么能少得了代理呢。
Splash的代理配置非常的简单,在传参的param加上proxy参数就可以了:
1. param = {2. "timeout": 10,
3. "url": 'https://api.myip.la/en?json',
4. "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36",
5. "proxy":getApiIp(),
6. "lua_source": """
7. function main(splash, args)
8. splash:go(args.url)
9. splash:wait(5)
10. splash.images_enabled = false
11. return splash:html()
12. end
13. """
14. }

看到这里的IP地址已经挂上了。
说到代理,我这里使用的是ipidea的代理。稳定高效的代理就像是你获取数据道路上的明灯,如黑暗里的一束光。即使再被封禁,被阻拦,也会带你获取到你想要的数据。:)
我以往使用Splash一般是处理前后端分离的网页用的,有时候后台接口获取的json数据并不是我们想要的内容。在写这篇文章之前,我甚至还觉得Splash只能获取get请求,没想到这个东西还是挺好用的。写了文章之后我也学习了不少东西。
最后提一嘴啊,Splash可以多服务器配置负载均衡的,已经有多个Splash的服务器的情况下,在用一台用公网IP的Nginx的服务器,修改下nginx的配置文件,配置认证就可以使用了。