将不同的数据源合并在一起是数据处理中最有趣的事情之一,在pandas中进行数据的合并,既可以使用pd.concat 进行简单的数据合并,也可以使用pd.merge, pd.join 进行复杂的合并;本节主要内
将不同的数据源合并在一起是数据处理中最有趣的事情之一,在pandas中进行数据的合并,既可以使用pd.concat 进行简单的数据合并,也可以使用pd.merge, pd.join 进行复杂的合并;本节主要内容是pd.concat。
pd.concat() 的用法
语法格式:
pandas.concat(objs, axis=0, join=‘outer’, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)
参数 解释 objs 表示需要连接的对象,多个df的话,用列表的方式传入该参数 axis {0/‘index’, 1/‘columns’}要连接的轴。0 为上下堆叠,1为左右拼接 join {‘inner’, ‘outer’}, 默认‘outer’。join='outer’表示外连接,保留两个表中的所有信息;join="inner"表示内连接,拼接结果只保留两个表共有的信息 ignore_index bool,默认为 False。如果为 True,则不要沿连接轴使用索引值。结果轴将标记为 0, …, n - 1。如果您要连接对象,而连接轴没有有意义的索引信息,这将非常有用。请注意,连接中仍然尊重其他轴上的索引值。 keys 键序列,默认无。如果通过了多个级别,则应包含 元组 。使用传递的键作为最外层构建层次索引。 levels 序列列表,默认无。用于构造 MultiIndex 的特定级别(唯一值)。否则,它们将从密钥中推断出来。 names 默认无。生成的分层索引中的级别名称。 verify_integrity bool 值,默认为 False。检查新的连接轴是否包含重复项。相对于实际的数据连接,这可能非常昂贵。 sort bool 值,默认为 False。如果连接为“外部”时尚未对齐,则对非连接轴进行排序。这在 join=‘inner’ 时无效,它已经保留了非串联轴的顺序。在 1.0.0 版更改: 默认情况下更改为不排序。 copy bool 值,默认 True。如果为 False,则不要不必要地复制数据。说明:虽然参数参数有这么多,但其实很多都不常用,常用的参数只有:axis,join ;只要记着两个就OK啦~
一、数据准备:
import pandas as pd df1=pd.DataFrame({'姓名':['周杰伦','蔡徐坤','王菲'],'歌曲':['明明就','情人','如愿'],'发行时间':[2019,2018,2021]},index=[1,2,3]) df2=pd.DataFrame({'姓名':['林俊杰','凤凰传奇'],'歌曲':['修炼爱情','海底'],'发行时间':[2016,2022]},index=[1,2])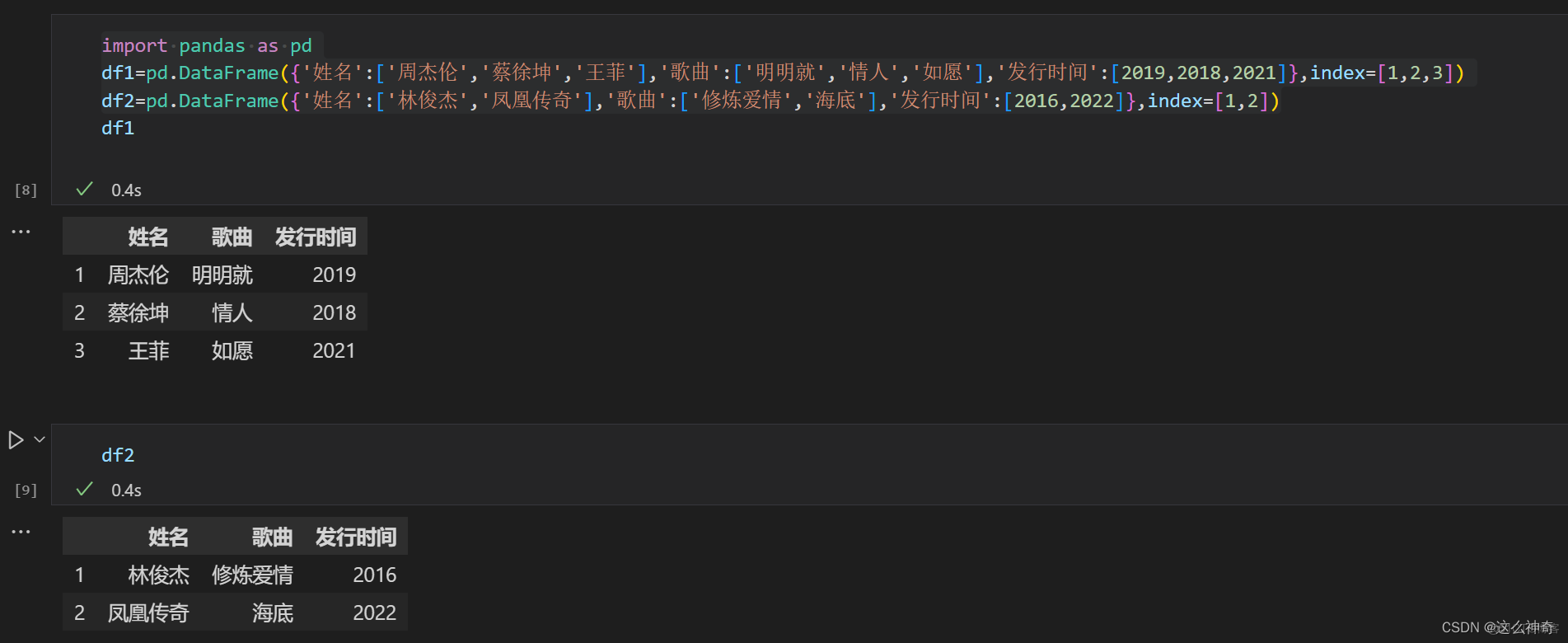
二、上下堆叠合并 axis=0
更多时候,pd.concat 就是为了将表上下拼接起来,所以这里的内容是非常重要的;
import pandas as pd df1=pd.DataFrame({'姓名':['周杰伦','蔡徐坤','王菲'],'歌曲':['明明就','情人','如愿'],'发行时间':[2019,2018,2021]},index=[1,2,3]) df2=pd.DataFrame({'姓名':['林俊杰','凤凰传奇'],'歌曲':['修炼爱情','海底'],'发行时间':[2016,2022]},index=[1,2]) df3 = pd.concat([df1,df2])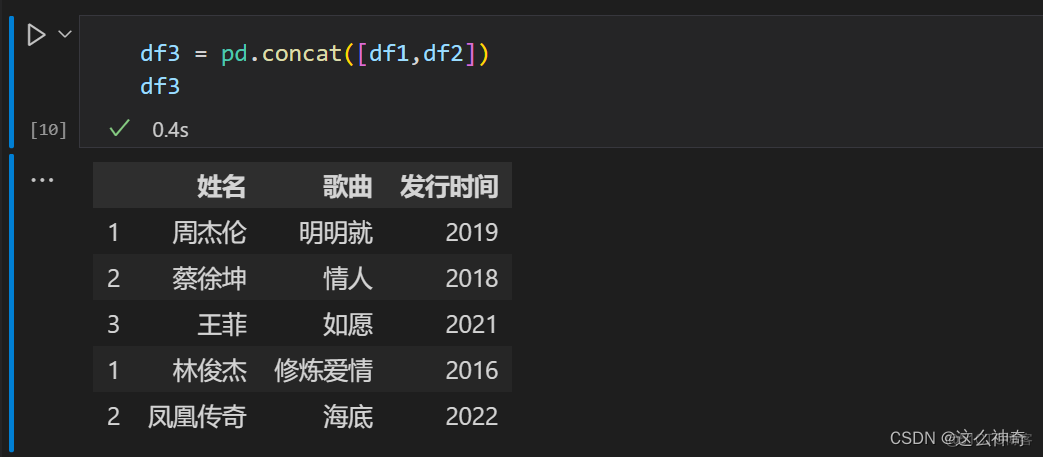
若两个表所包含的列名有不同,举例如下:
import pandas as pd df1=pd.DataFrame({'姓名':['周杰伦','蔡徐坤','王菲'],'歌曲':['明明就','情人','如愿'],'发行时间':[2019,2018,2021]},index=[1,2,3]) df2=pd.DataFrame({'姓名':['林俊杰','凤凰传奇'],'歌曲':['修炼爱情','海底'],'金曲奖':['是','否']},index=[1,2]) df3 = pd.concat([df1,df2])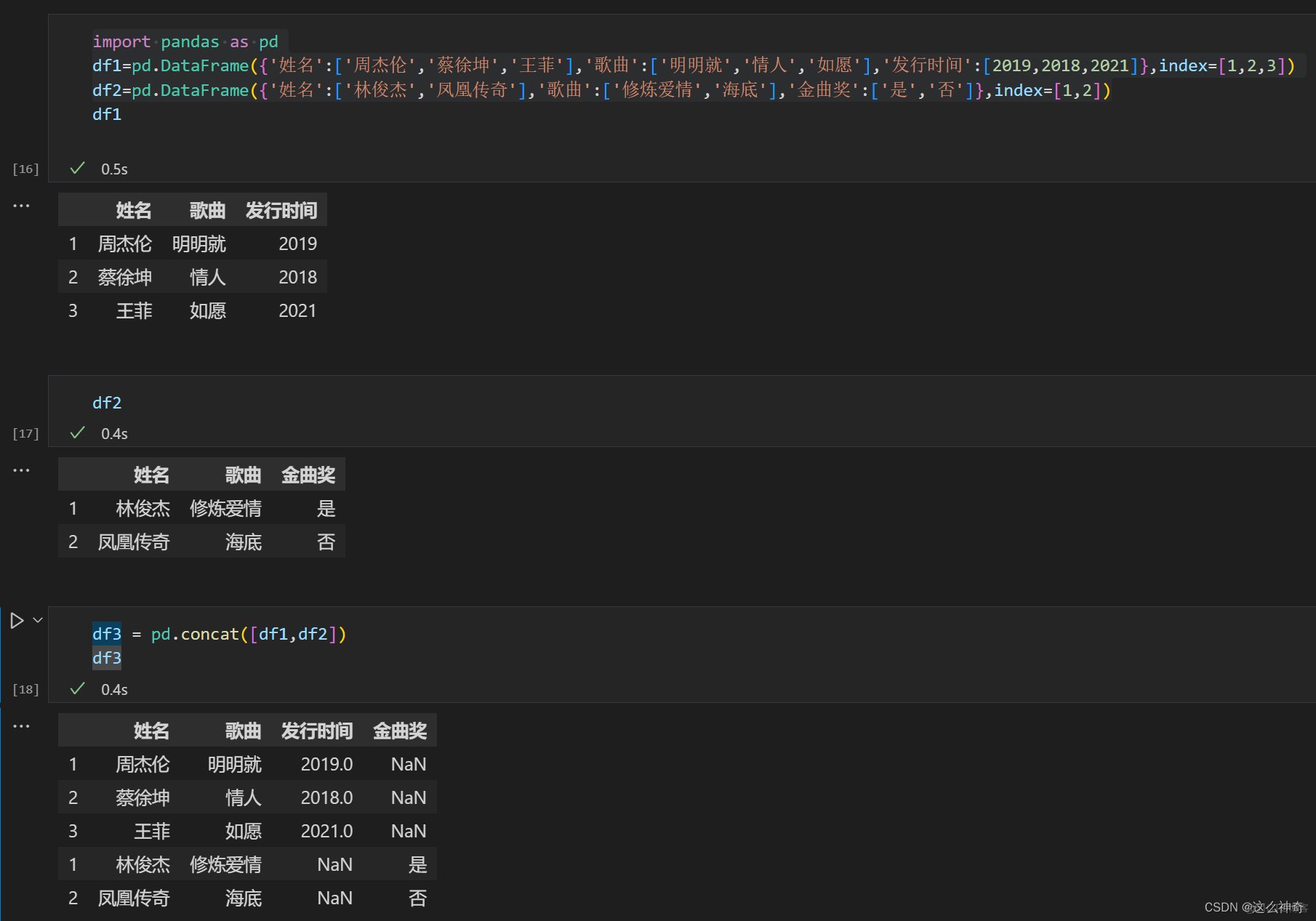
三、左右拼接合并 axis=1
import pandas as pd df1=pd.DataFrame({'姓名':['周杰伦','蔡徐坤','王菲'],'歌曲':['明明就','情人','如愿'],'发行时间':[2019,2018,2021]},index=[1,2,3]) df2=pd.DataFrame({'姓名':['林俊杰','凤凰传奇'],'歌曲':['修炼爱情','海底'],'发行时间':[2016,2022]},index=[1,2]) df3 = pd.concat([df1,df2],axis=1)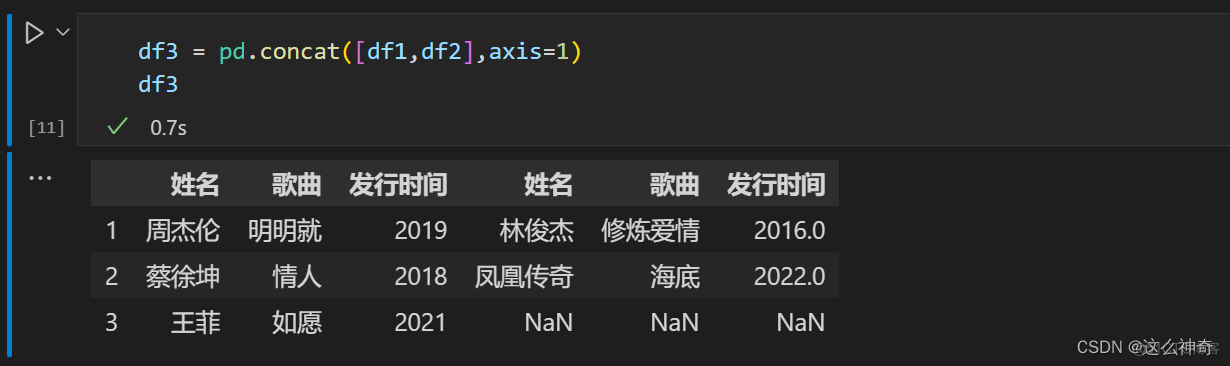
若两个表所包含的列不同,举例如下:
import pandas as pd df1=pd.DataFrame({'姓名':['周杰伦','蔡徐坤','王菲'],'歌曲':['明明就','情人','如愿'],'发行时间':[2019,2018,2021]},index=[1,2,3]) df2=pd.DataFrame({'姓名':['林俊杰','凤凰传奇'],'歌曲':['修炼爱情','海底'],'金曲奖':['是','否']},index=[1,2]) df3 = pd.concat([df1,df2],axis=1)可以看到,左右拼接合并时,是以Index作为拼接的关联值的;所以这个方法不是非常常用;因为不太好用;所以,可以忘记这里;
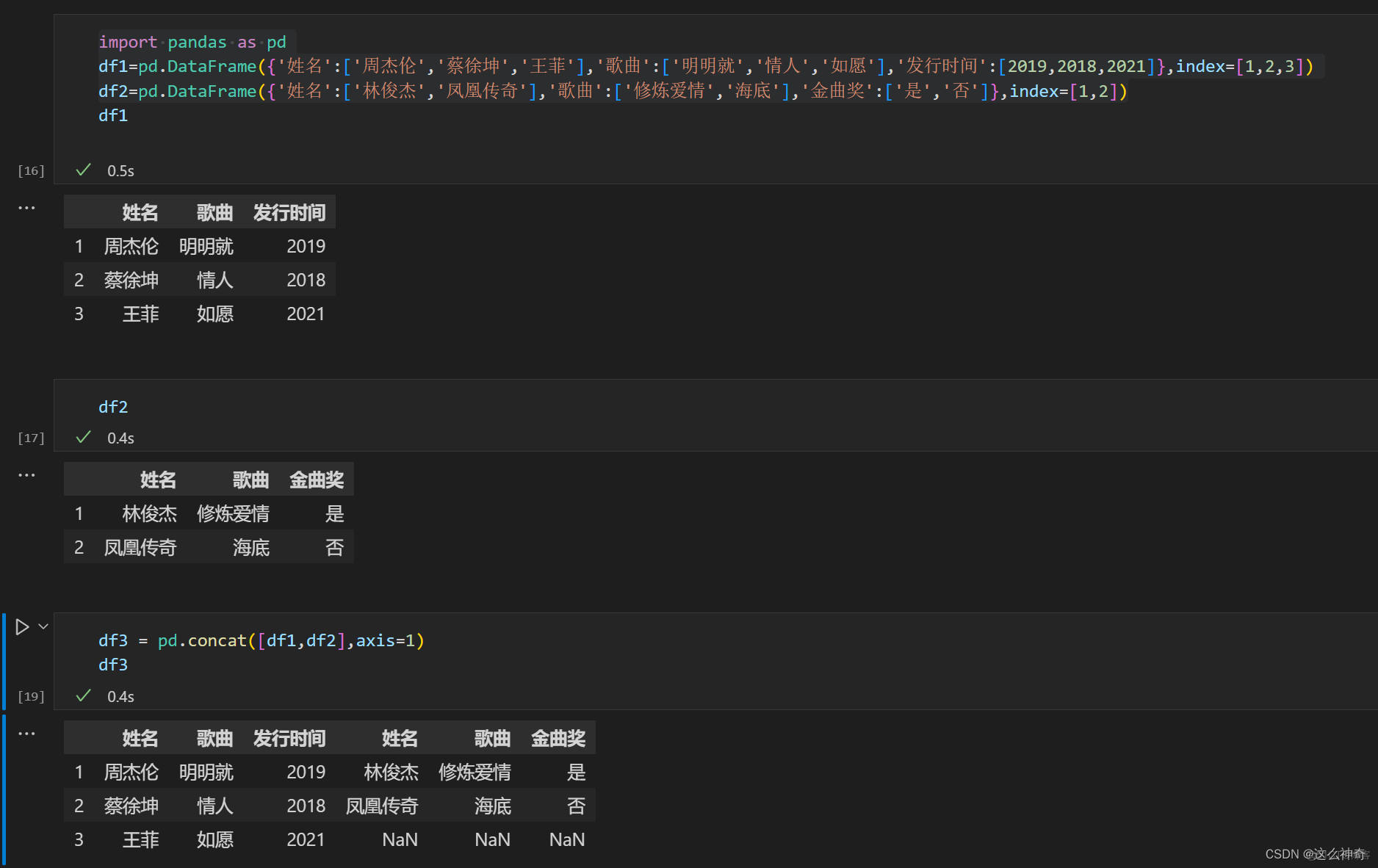
四、inner 与 outer 对比
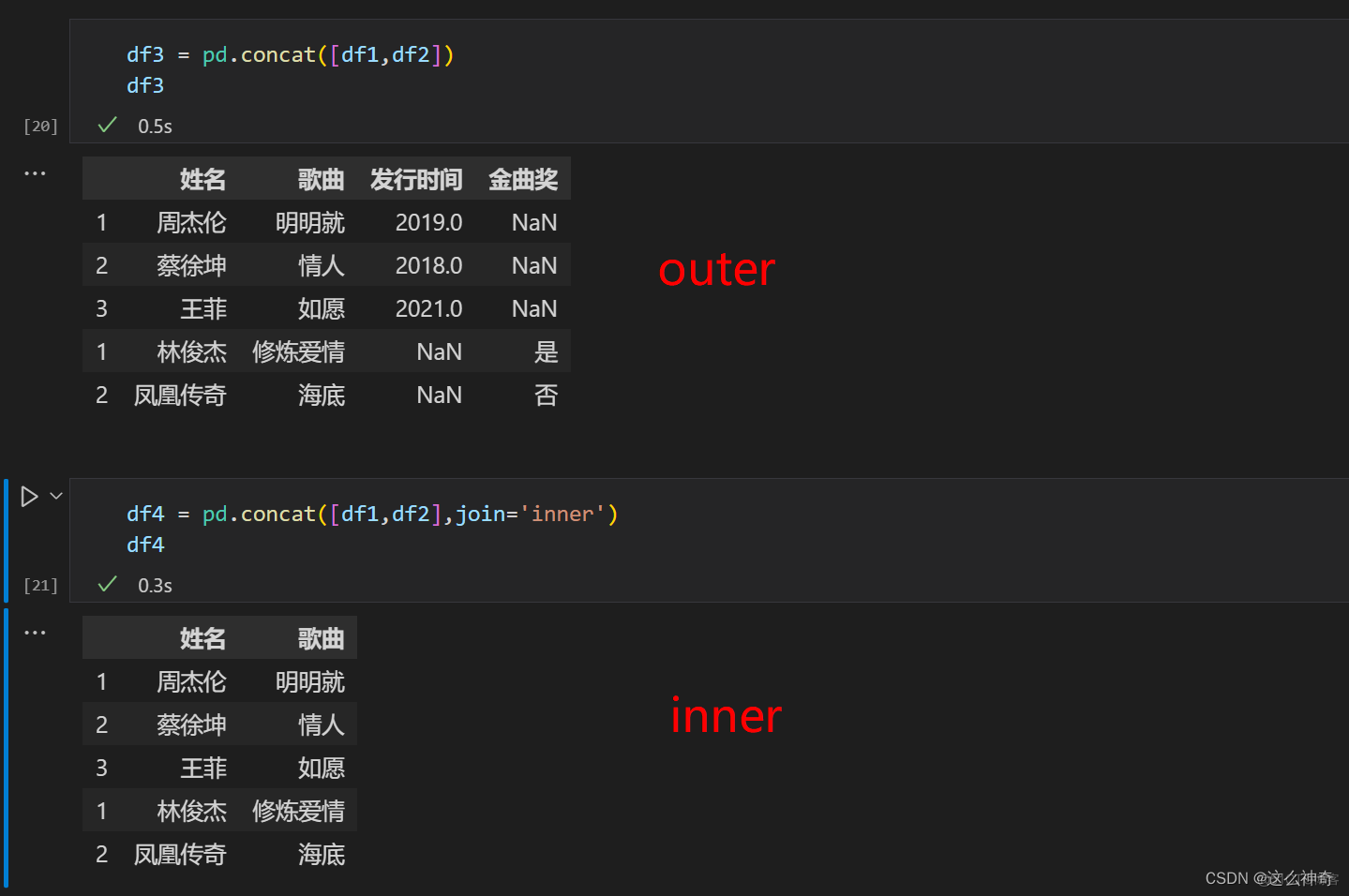
join = 'outer' 就是默认值,所以上面所举的例子都是join = 'outer'的结果,两个参数的对比为:
参数 说明 join = 'outer' 保留所有的数据 join = 'inner' 只保留共有信息举例如下:
写在最后
pd.concat() 函数虽然参数参数有很多,但其实很多都不常用,常用的参数只有:axis,join ;所以只要知道这两个,一般情况下,就完全够用了;另外,pd.concat() 函数在通常情况下都只用于上下堆叠合并,所以其实我们只要知道上下堆叠合并,这一种使用方法就完全OK啦~
这里多余写这段话,主要就是想大家把精力放在重点上,避免在不重要的地方投入过多精力;
以上为个人理解,如有错误,还请不吝赐教,多多指导~~