写在前面
这一节非常的重要,因为Pandas中的数据集合并,最常用的方法就是 merge, 如果大家对数据库熟悉的话,那么会觉得 merge 非常容易理解,因为这个的使用和数据库的合并几乎完全一样。稍微有一点点难点的,应该就是对合并方式的理解,即:inner、outer、left、right 这四种合并方式的理解,下面我们来一起看 pd.merge()的使用方法吧;
pd.merge()的使用方法
语法格式:
pd.merge(left, right, how = ‘inner’, on = None, left_on = None, right_on = None, left_index = False, right_index = False, sort = True, suffixes = (‘_x’,’_y’), copy = True, indicator = False, validate = None)
参数 解释 left、right 需要连接的两个DataFrame或Series,一左一右 。重要参数! how 两个数据连接方式,默认为inner,可设置inner、outer、left或right 。重要参数! on 作为连接键的字段,当左右两个表的列名相同时使用。如果不相同,需要用left_on和right_on来分别指定。重要参数! left_on 左表的连接键字段 。 重要参数! right_on 右表的连接键字段。重要参数! left_index 为True时将左表的索引作为连接键,默认为False right_index 为True时将右表的索引作为连接键,默认为False suffixes 如果左右数据出现重复列,新数据表头会用此后缀进行区分,默认为_x和_y sort 排序 indicator 标注数据来源,即:left_only, right_only, both参数很多,但其实最重要的只有两个参数,即:how, on; 其余参数只要了解就好;
一、数据准备
需要使用两张表,表数据如下,可以复制到本地进行练习;
表一:name_list
Name,from,Year 塞尔达传说,任天堂,2017 只羊,FS,2019 战神,Sony,2018 王者荣耀,Tencent,2015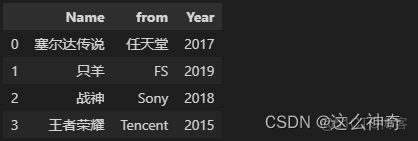
表二:best_list
Name,最佳游戏 塞尔达传说,是 战神,是 王者荣耀,否 双人成形,是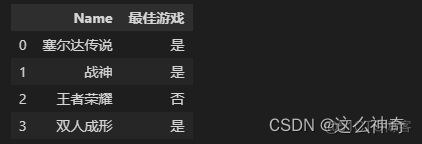
读入数据:
import pandas as pd path_1 = r"./name_list.csv" path_2 = r"./best_game.csv" df_name = pd.read_csv(path_1) df_best = pd.read_csv(path_2)二、参数left 与 right
pd.merge()只能用于两个表的拼接,而且通过参数名称也能看出连接方向是左右拼接,一个左表一个右表,不可以用作上下的拼接;
这里的两个参数传入后,如果有公共的列名,则可以直接Merge, 举例如下:从例子中我们可以看到,默认的参数如下:on="Name", how="Inner";
import pandas as pd path_1 = r"./name_list.csv" path_2 = r"./best_game.csv" df_name = pd.read_csv(path_1) df_best = pd.read_csv(path_2) df3 =pd.merge(df_name,df_best) # 等价于 df3 =pd.merge(left = df_name,right = df_best, on="Name",how="inner")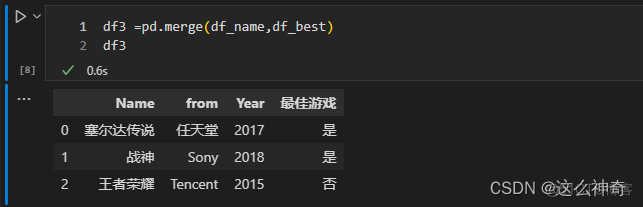
三、参数 on
参数on 用来指定用那些列来进行拼接,如果不特别不指定,则,相同信息的列都会作为拼接依据; 故一般情况下,还是推荐用on将列指定,避免后续的bug;
当两个表需要拼接的列,列名相同时,直接用on=列名,即可; 若两个表需要拼接的列,列名不同时,需要使用参数:left_on 与 right_on,举例如下:
列名相同:
df3 =pd.merge(left = df_name,right = df_best, on="Name")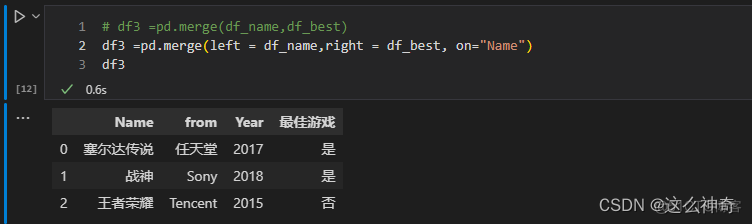
列名不同:
df_best.columns = ['Game_name','最佳游戏'] #修改列名 df3 =pd.merge(left = df_name,right = df_best, left_on="Name",right_on="Game_name")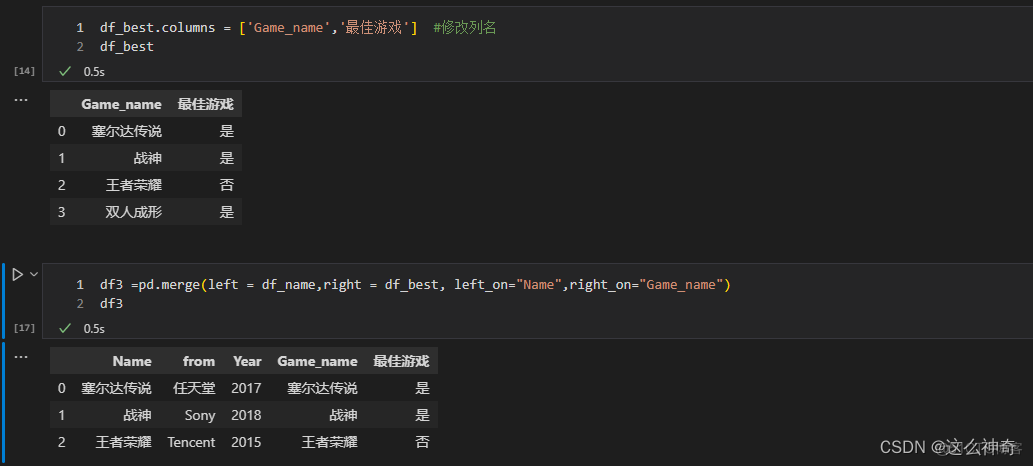
四、参数 leftindex 和 rightindex
可以用Index作为合并列,在有工号,身份证号等这样的不重复信息时,可以大大提高运算的速度,举例如下:
pd.merge(df_name_index,df_best_index,left_index=True,right_index=True)
全部代码如下:
import pandas as pd path_1 = r"./name_list.csv" path_2 = r"./best_game.csv" df_name = pd.read_csv(path_1) df_best = pd.read_csv(path_2) df_name_index = df_name.set_index(["Name"]) df_best.columns = ['Game_name','最佳游戏'] #修改列名 df_best_index = df_best.set_index("Game_name") df_index = pd.merge(df_name_index,df_best_index,left_index=True,right_index=True)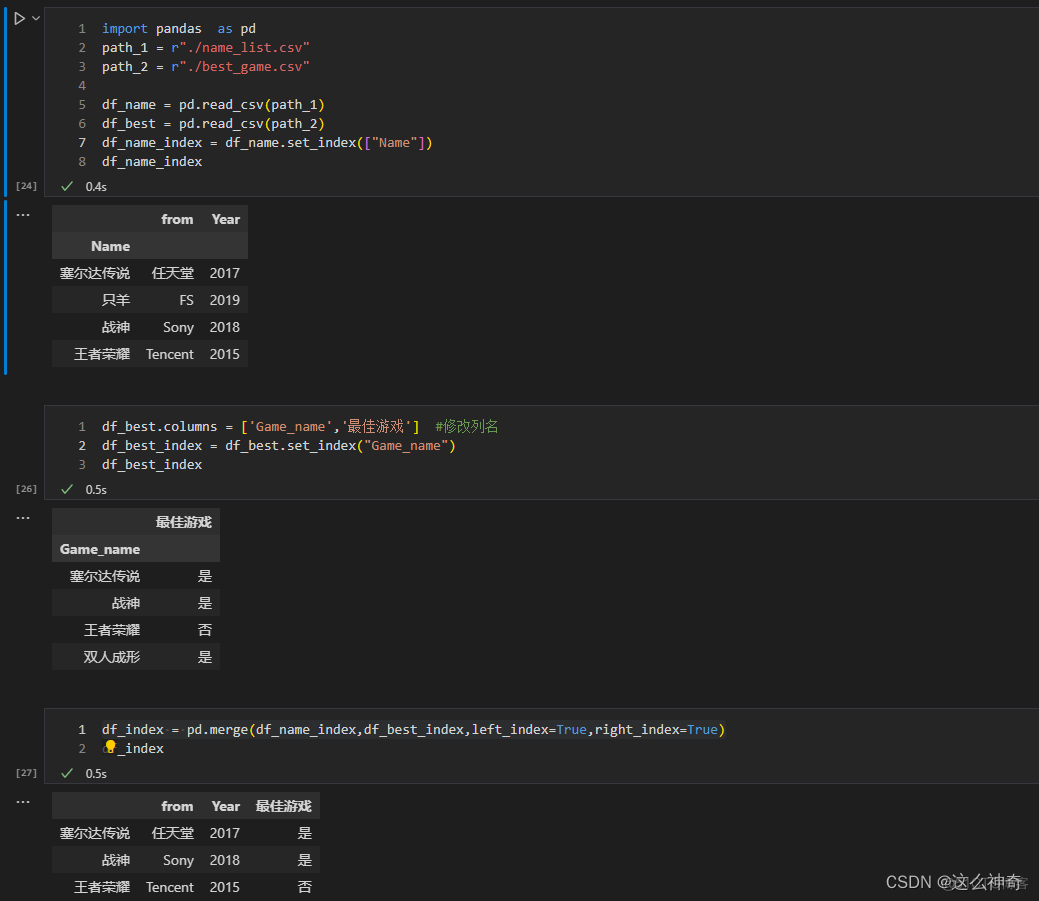
五、参数how
参数 how 是 Merge函数中最重要的参数,how 有四个可以传入的值,即: inner、outer、left或right ,分别解释如下:
参数 图示(红圈演示,虽然不太对,但是好理解) 说明 举例 left 左连接 ;返回包括左表中的所有记录和右表中连接字段相等的记录
左连接 ;返回包括左表中的所有记录和右表中连接字段相等的记录
 right
right
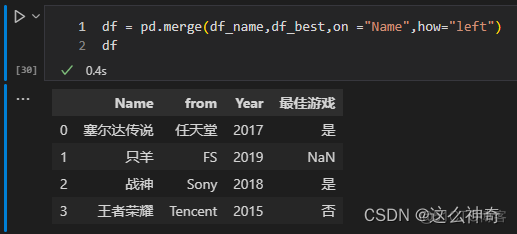
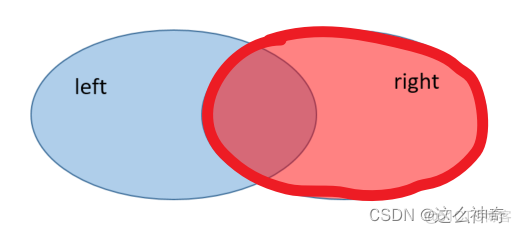 右连接; 返回包括右表中的所有记录和左表中连接字段相等的记录;
右连接; 返回包括右表中的所有记录和左表中连接字段相等的记录;
 inner
inner
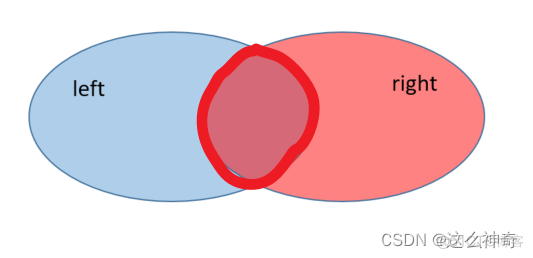 内连接; 只返回两个表中连接字段相等的行;
内连接; 只返回两个表中连接字段相等的行;
 outer
outer
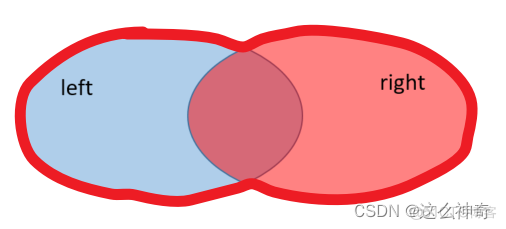 外连接;返回左右表中所有的记录和左右表中连接字段相等的记录;
外连接;返回左右表中所有的记录和左右表中连接字段相等的记录;
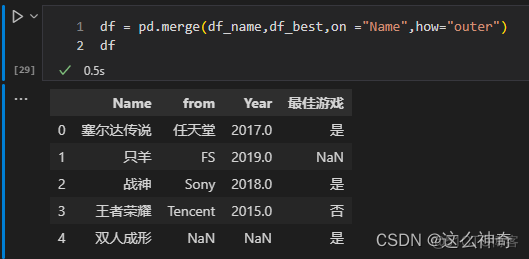
代码如下:
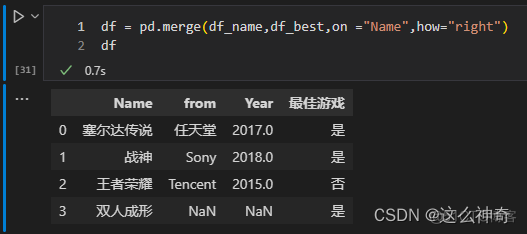
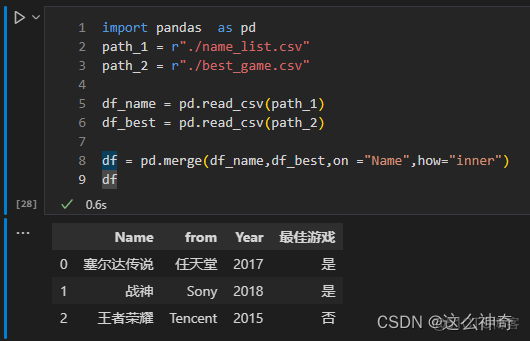
import pandas as pd path_1 = r"./name_list.csv" path_2 = r"./best_game.csv" df_name = pd.read_csv(path_1) df_best = pd.read_csv(path_2) df = pd.merge(df_name,df_best,on ="Name",how="inner") df = pd.merge(df_name,df_best,on ="Name",how="outer") df = pd.merge(df_name,df_best,on ="Name",how="left") df = pd.merge(df_name,df_best,on ="Name",how="right")六、参数indicator
默认是False不显示数据来源,把参数设置为True就可以了。举一个例子大家就明白了; 如下面的例子,both代表数据来源于两个表,left_only 代表数据来源于左表, right_only 代表数据来源于右边。
pd.merge(df_name,df_best,on ="Name",how="outer",indicator=True)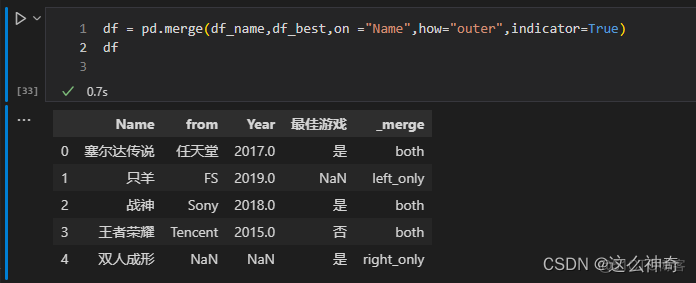
七、参数suffixes
参数suffixes可以将原来数据集中相同的列名进行标注(出去on后面指定的列),默认为 x和y; 举一个例子大家就明白了; 为了两个表有相同的列,我们将原始数据修改如下:
左表:
Name,from,Year 塞尔达传说,任天堂,2017 只羊,FS,2019 战神,Sony,2018 王者荣耀,Tencent,2015右表:
Name,最佳游戏,Year 塞尔达传说,是,2017 战神,是,2018 王者荣耀,否,2015 双人成形,是,2021代码:
import pandas as pd path_1 = r"./name_list.csv" path_2 = r"./best_game.csv" df_name = pd.read_csv(path_1) df_best = pd.read_csv(path_2) df = pd.merge(df_name,df_best,on ="Name",how="outer",suffixes=("_left","_right"))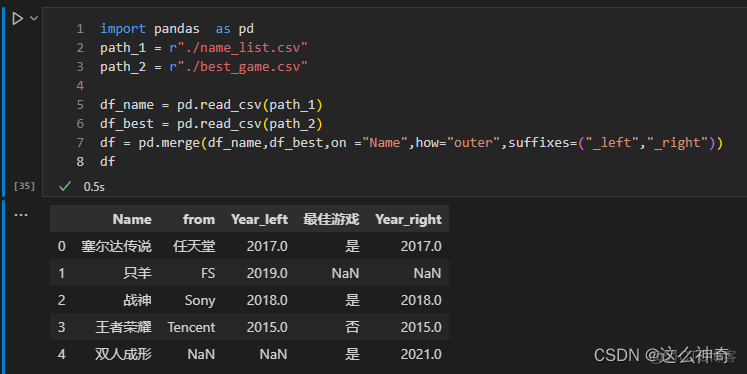
写在后面
上面写了挺多参数,但实际上大家只要会使用 on, how 就够了,不用浪费太多的时间去研究每一个参数,需要使用的时候再来查就好啦~ 因为现在研究了,长时间不用,也会忘记的~
【文章转自国外服务器 http://www.558idc.com处的文章,转载请说明出处】