在对较大数据进行分析时,有一项最基本的工作就是:有效的数据累积,比如:求和(sum),平均值(mean),中位数(median),最小值(min),最大值(max)等;这每一项指标都是对原本大数据的
在对较大数据进行分析时,有一项最基本的工作就是:有效的数据累积,比如:求和(sum),平均值(mean),中位数(median),最小值(min),最大值(max)等;这每一项指标都是对原本大数据的一个展现,反映了原本大数据的特征。所以本节主要说明两个问题:1. 求累计值;2. 分组求累计值;
一、数据准备
我们以Titanic 数据为例,来进行说明; 所有数据,请参考《泰坦尼克数据集》
import pandas as pd path = r'./titanic.csv' df = pd.read_csv(path)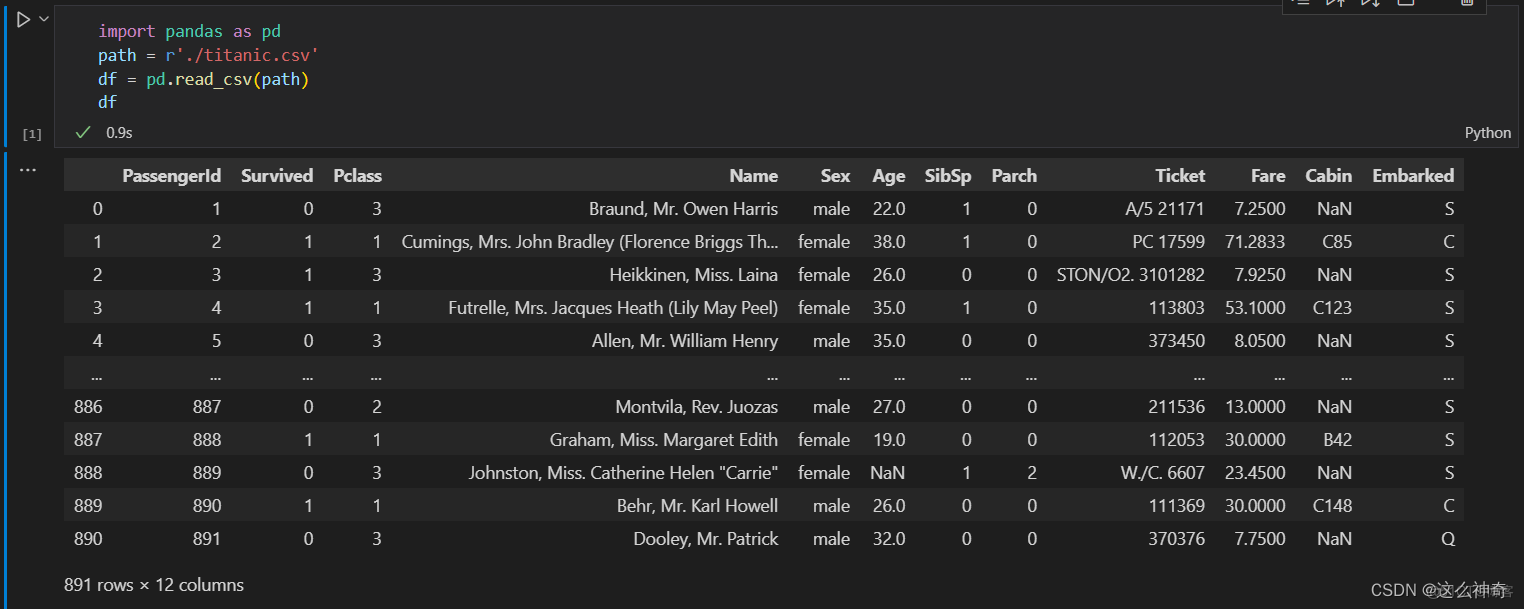
二、累计值计算
2.1 df.describe()
pandas中提供了一个非常方便的方法df.describe(),来列出常用的统计值,包括:计数值(count),平均值(mean),标准差(std),最小值(min),最大值(max)等,举例如下:
df.describe()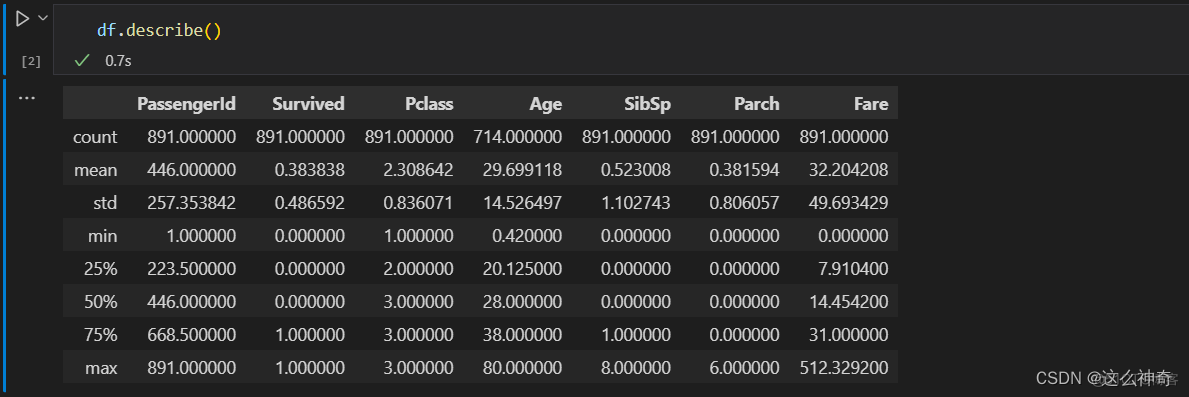
2.2 常用统计值
常用统计值包括计数值,计数值(count),平均值(mean),标准差(std),最小值(min),最大值(max)等,举例如下:
若不指定具体的列,则Pandas会默认计算所有的可计算的列:
df.mean() #平均值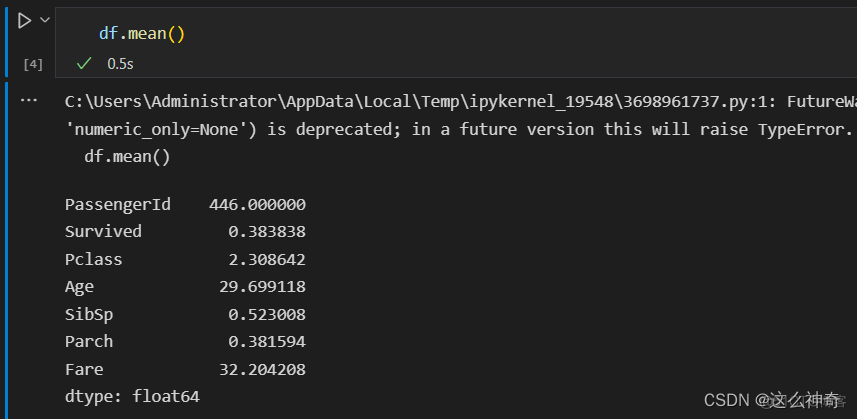 我们详细讲解指定列的情况:
我们详细讲解指定列的情况:
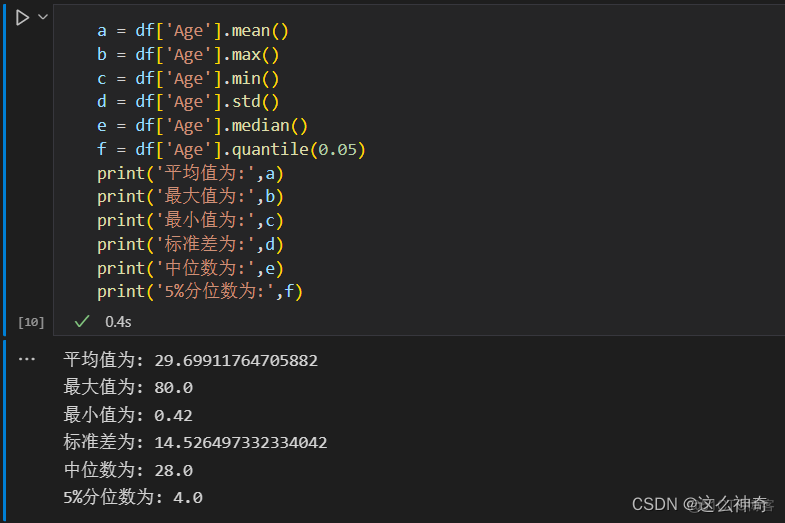
常用的统计值有以下:
函数 描述 count() 计数值 first() 第一项的值 last() 最后一项的值 mean() 平均值 median() 中位数 min() 最小值 max() 最大值 std() 标准差 var() 方差 mad 均值绝对偏差 prod() 所有项的乘积 sum() 所有项的和三、分组 pd.groupby()
当我们直接使用统计值时,可以知道整体状况,比如所有人的年龄的平均值,但是比如我们想要知道:男性和女性的年龄分别是多少。这时我们就需要使用 pd.groupby().
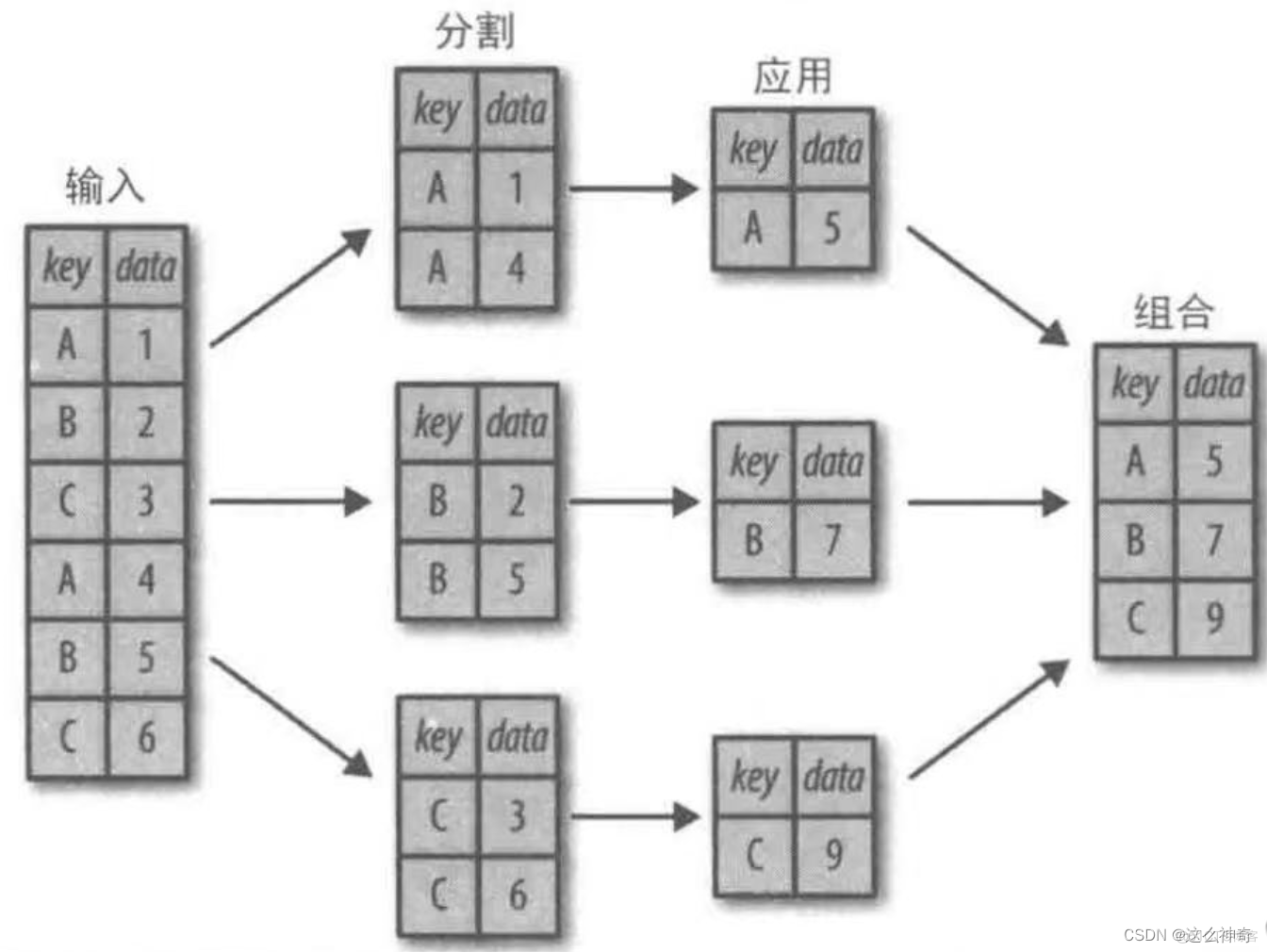
pd.groupby() 的工作原理就是:分割,应用,组合,如下图所示:
备注:这张图来自《Python 数据科学手册》,是很经典的一张图。
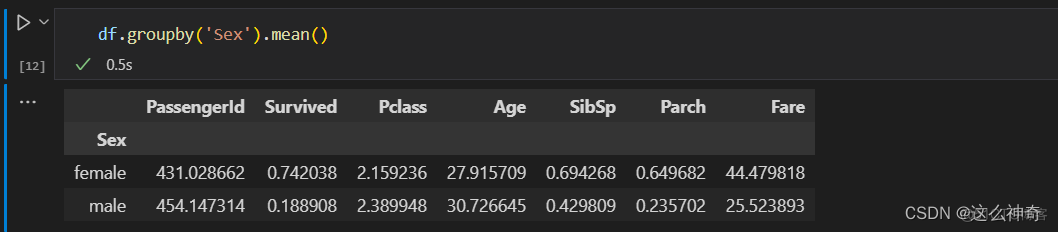
- 我们统计所有列的平均值,要求:按性别进行区分;代码如下:
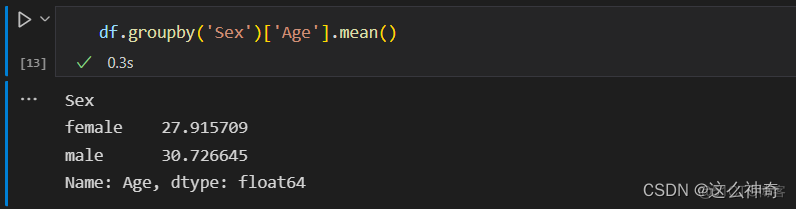
- 如果我们只关注男性与女性的平均年龄,代码如下:
- 如果我们关注男女年龄的更多统计信息,代码如下:
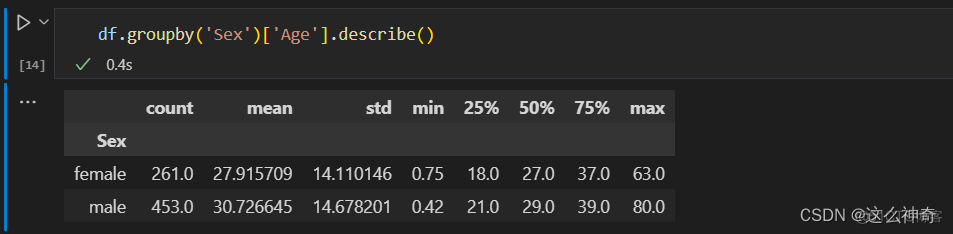
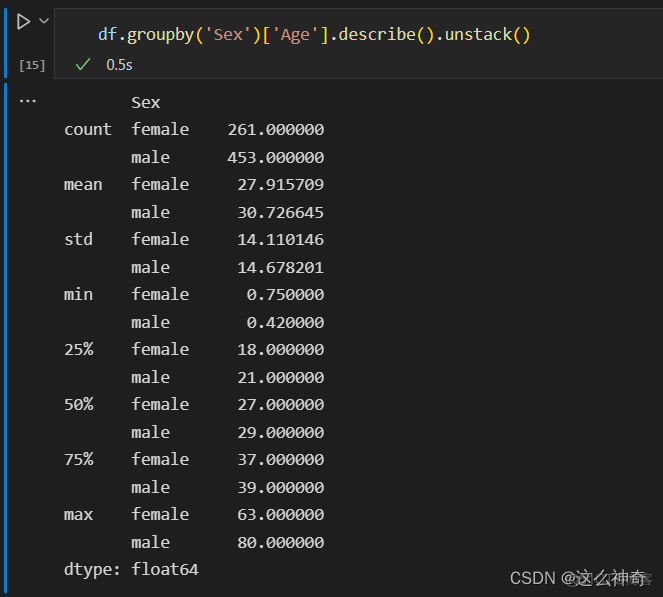
- 还可以通过.unstack(),变换输出的形状;
四、更多的使用方法aggregate(),filter(),transform(),apply()
4.1 aggregate()
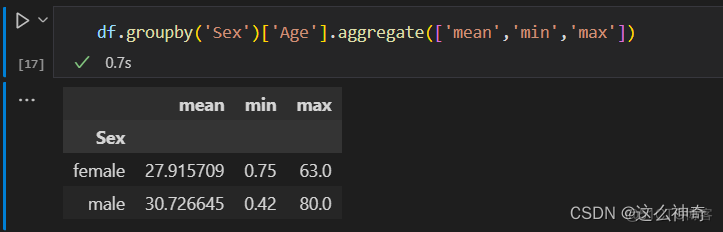
- 多个统计值,比如我们需要同时看男女的平均年龄与最大年龄、最小年龄,举例如下:
4.2 filter()
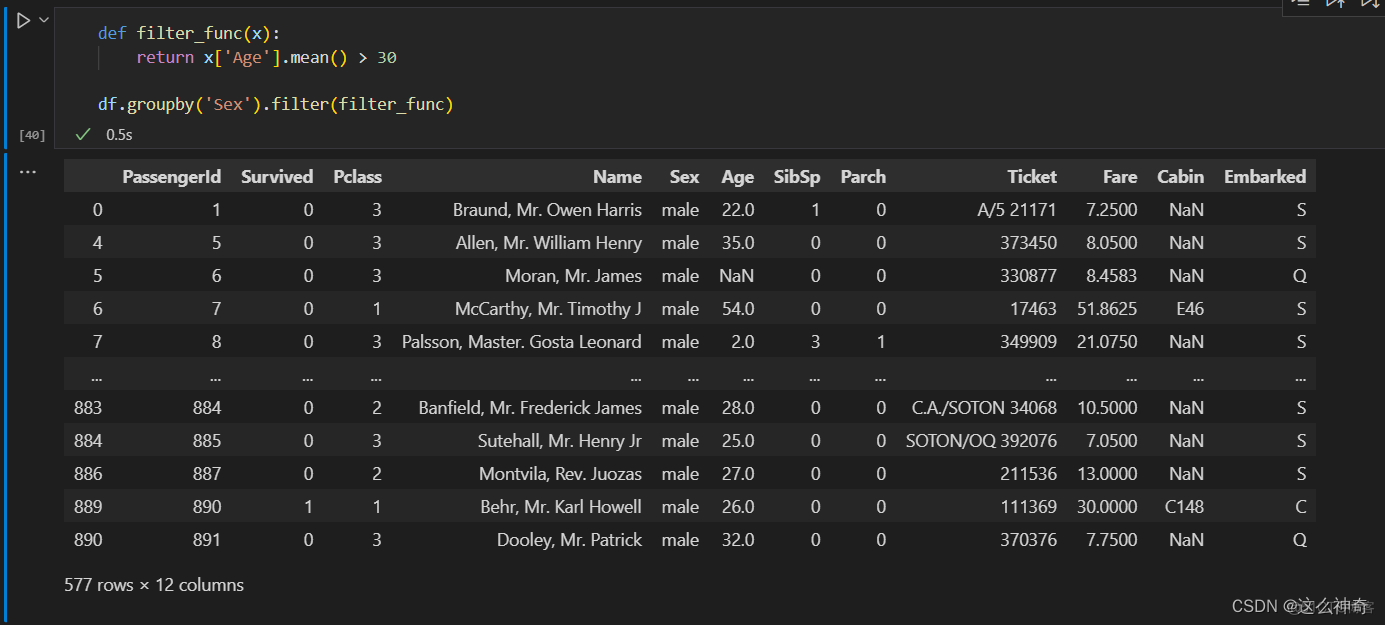
- 过滤的使用,可以过滤掉统计值满足一定条件的所有数据,例如:我们将数据按照性别分成两大类(即:男女),然后这两组数据里,我们只取年龄平均值大于30的数据,我们可以看到:所有的男性被选中,所有的女性都被过滤掉了;举例如下:
从下面的截图可以看到,性别里只剩下男性了;说明女性的年龄平均值不到30;
4.3 transform()
df.groupby('Sex')['Age'].transform(lambda x:x-x.mean())
4.4 apply()
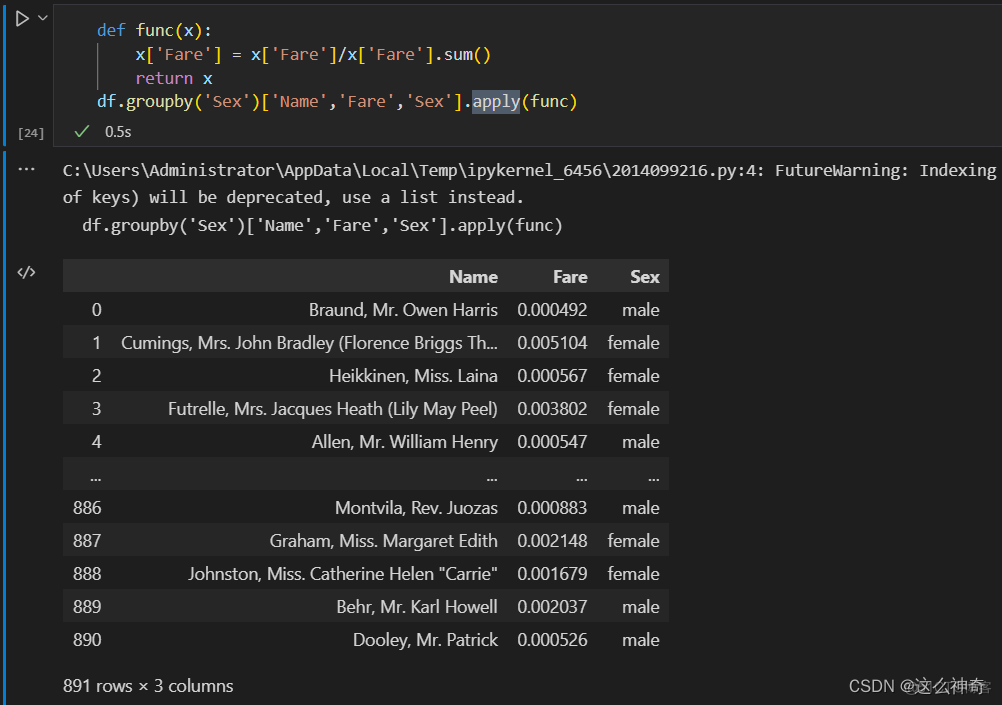
这里举例为:我们看一下每个人的票价占总票价的比例,代码如下:
def func(x): x['Fare'] = x['Fare']/x['Fare'].sum() return x df.groupby('Sex')['Name','Fare','Sex'].apply(func)