MyISAM引擎的索引实现
在MyISAM里面,另外有两个文件,一个是.MYD文件,D代表Data,是MyISAM的数据文件,存放数据记录,比 如我们的user_myisam表的所有的表数据;
一个是.MYI文件,I代表Index,是MyISAM的索引文件,存放索引,比如我们在id字段上面创建了一个主键索引,那么主键索引就是在这个索引文件里面。一个索引就会有一棵B+Tree,所有的B+Tree都在这个MYI文件里面;
在MyISAM里面,索引和数据是两个独立的文件;
MyISAM引擎的索引实现如下图所示:
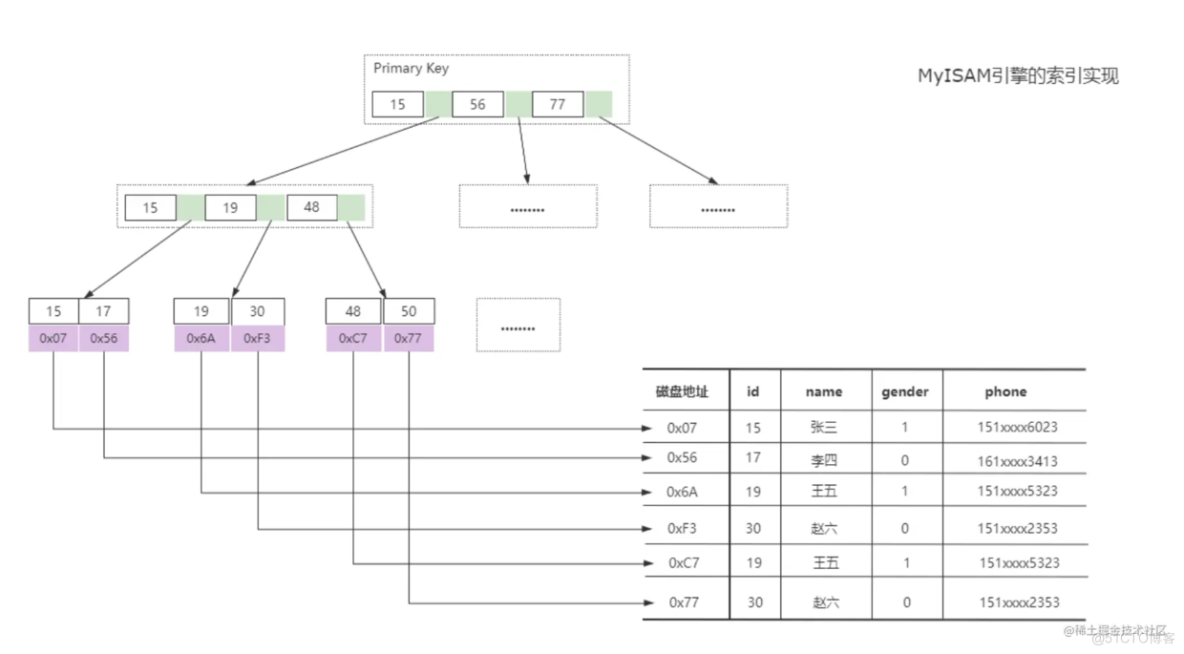
从MyISAM引擎中索引的实现来看,由于索引文件和数据文件是分离的,叶子节点存储的是数据文件对应的磁盘地址,从索引文件.MYI中找到键值后,会到数据文件.MYD中获取相应的数据记录。在MyISAM引擎中,主键索引和辅助索引在结构上没有任何区别,只是主键 索引要求key是唯一的,而辅助索引的key允许重复;
InnoDB索引实现
在InnoDB中,只有一个ibd文件,里面包含索引和数据;
同时,在B+Tree中的叶子节点存储了索引对应的数据行,所以我们称InnoDB中索引即数据、数据即索引,它的整体结构如下图所示:
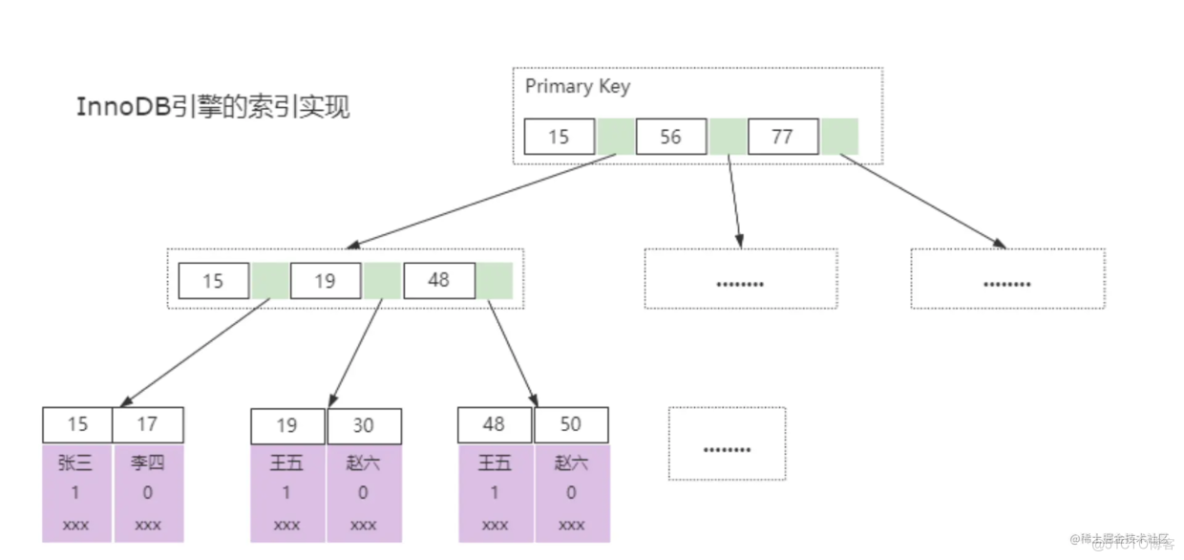
上图中,叶子节点的数据区保存的就是真实的数据,再通过索引进行检索的时候,命中叶子节点,就可以直接从叶子节点中取出行数据;
聚簇索引和非聚簇索引
在一个表中,我们可以建立很多中索引,如唯一索引、主键索引、辅助索引等;
如果是一个表中存在多个索引的情况下? 数据表应该保存到哪个索引的叶子节点呢?,InnDB中,引入了聚集索引(聚簇索引)和非聚集索引的概念。
聚簇索引
聚簇索引,就是指索引键值的逻辑顺序和表数据行的物理存储顺序一致。只有聚簇索引才会在叶子节点缓存表中的数据;
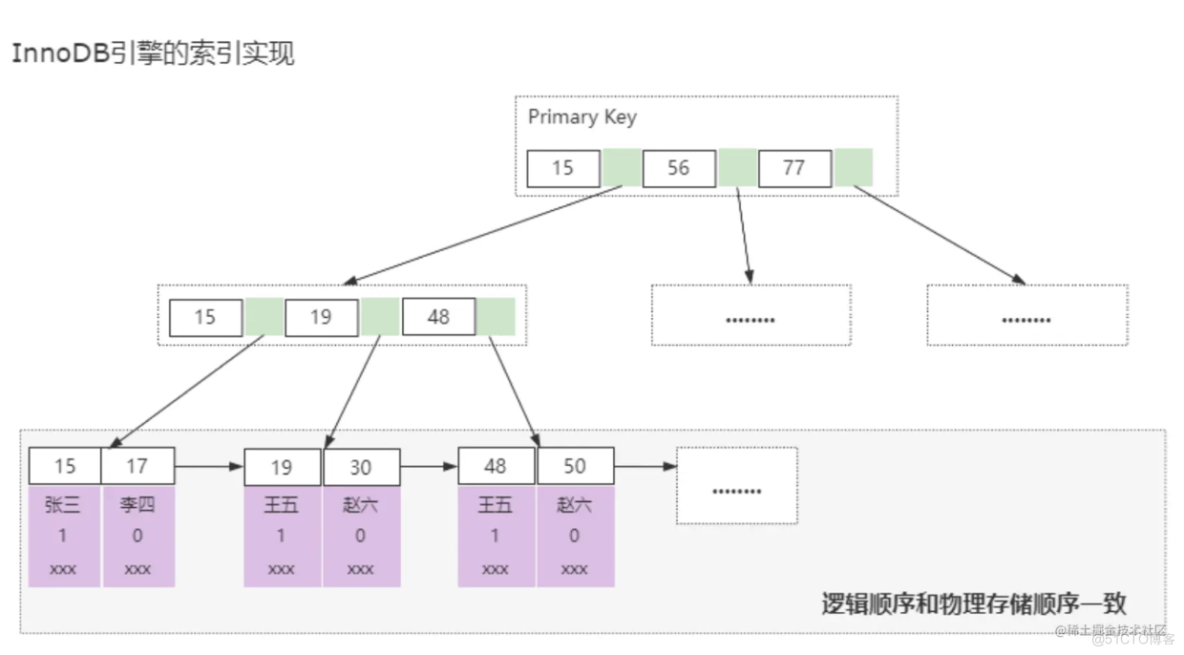
在InnoDB中,组织数据的方式就是用聚簇索引组织表,所以一张表创建了主键索引,那么这个主键索引就是聚 集索引;
非聚簇索引
除了主键索引以外,其他索引均属于非聚簇索引,非聚簇索引的叶子节点不会存储表数据,下非聚簇索引的存储结构如下图所示:
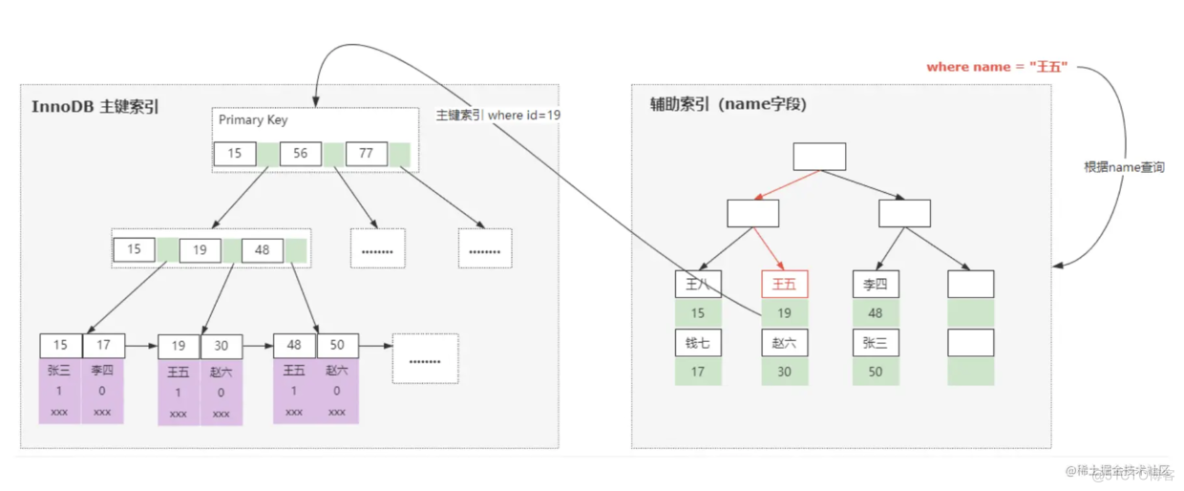
从上面这个图可以看到,真正的数据仍然是保存到主键索引的叶子节点,而辅助索引的叶子节点的数据区保存的是主键索引的关键字的值;
非主键索引叶子节点的逻辑顺序和磁盘顺序不一致;
当我们要查询where name = '王五'时:
- 先通过二级索引去B+Tree中找到王五的叶子节点,拿到对应的主键值,也就是id=15;
- 接着在根据这个条件去主键索引中查找到叶子节点拿到数据(这里不能存储磁盘地址,因为在数据insert和delete时,B+Tree的结构会发生变化);
- 因为主键索引比二级索引少扫描了一棵B+Tree,它的速度相对会快一些
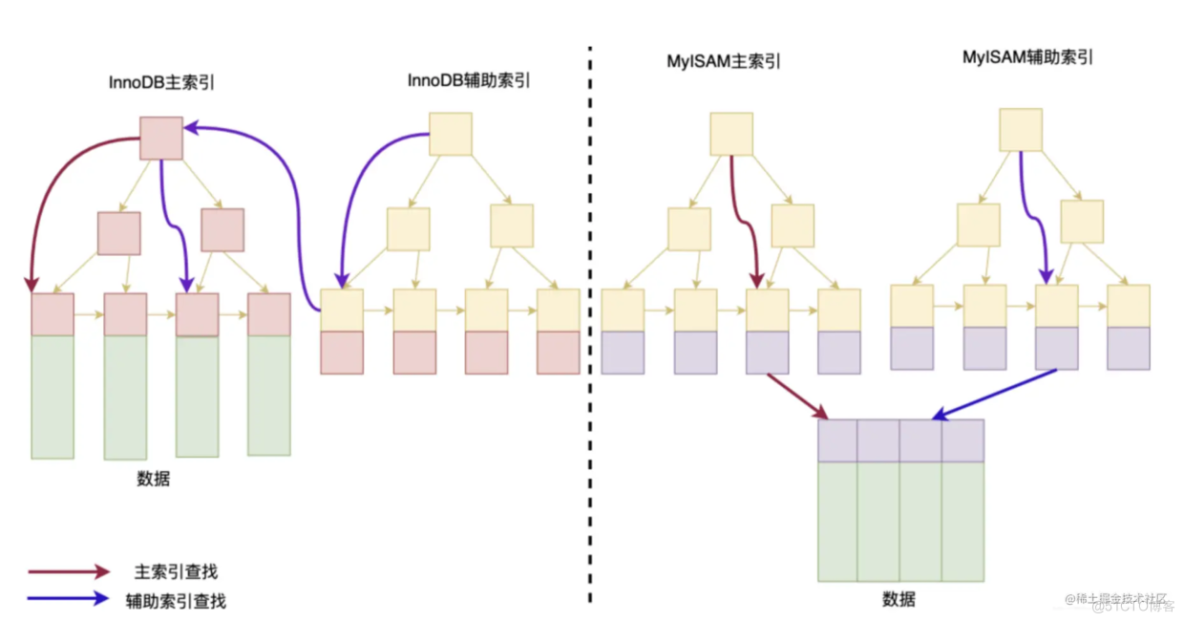
MyISAM和InnoDB两种引擎索引区别
两者区别如下图所示: