
程序员必备接口测试调试工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api设计、调试、文档、自动化测试工具
后端、前端、测试,同时在线协作,内容实时同步
【相关推荐:Python3视频教程 】
一、BeautifulSoup4库介绍
1. 介绍
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。
BeautifulSoup4将网页转换为一颗DOM树: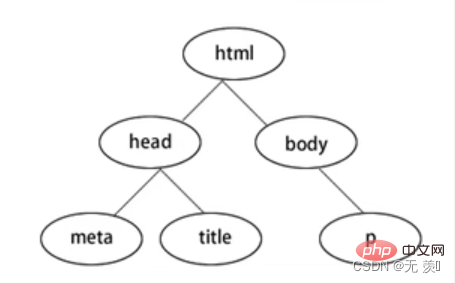
2. 下载模块
1. window电脑点击win键+ R,输入:cmd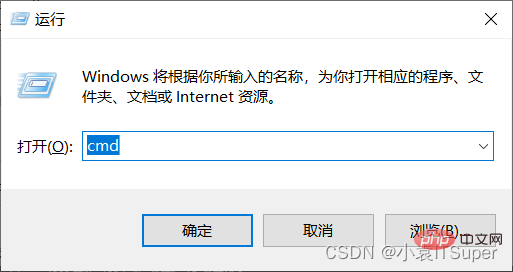
2. 安装beautifulsoup4,输入对应的pip命令:pip install beautifulsoup4 ,我已经安装过了出现版本就安装成功了

3. 导包
form bs4 import BeautifulSoup
登录后复制3. 解析库
BeautifulSoup在解析时实际上依赖解析器,它除了支持Python标准库中的HTML解析器外,还支持一 些第三方解析器(比如lxml):
BeautifulSoup(html,’html.parser’)Python的内置标准库、执行速度适中、文档容错能力强Python 2.7.3及Python3.2.2之前的版本文档容错能力差lxml HTML解析库BeautifulSoup(html,’lxml’)速度快、文档容错能力强需要安装C语言库lxml XML解析库BeautifulSoup(html,‘xml'速度快、唯一支持XML的解析器需要安装C语言库htm5lib解析库BeautifulSoup(html,’htm5llib’)最好的容错性、以浏览器的方式解析文档、生成HTMLS格式的文档速度慢、不依赖外部扩展对于我们来说,我们最常使用的解析器是lxml HTML解析器,其次是html5lib.
二、上手操作
1. 基础操作
1. 读取HTML字符串:
from bs4 import BeautifulSoup
html = '''
<p class="panel">
<p class="panel-heading">
<h4>Hello</h4>
</p>
<p class="panel_body">
<ul class="list" id="list-1" name="element">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<a href="https://www.baidu.com">百度官网</a>
<li class="element">Bar</li>
</ul>
</p>
</p>
'''# 创建对象soup = BeautifulSoup(html, 'lxml')登录后复制2. 读取HTML文件:
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('index.html'),'lxml')登录后复制3. 基本方法
from bs4 import BeautifulSoup
html = '''
<p class="panel">
<p class="panel-heading">
<h4>Hello</h4>
</p>
<p class="panel_body">
<ul class="list" id="list-1" name="element">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<a href="https://www.baidu.com">百度官网</a>
<li class="element">Bar</li>
</ul>
</p>
</p>
'''# 创建对象soup = BeautifulSoup(html, 'lxml')# 缩进格式print(soup.prettify())# 获取title标签的所有内容print(soup.title)# 获取title标签的名称print(soup.title.name)# 获取title标签的文本内容print(soup.title.string)# 获取head标签的所有内容print(soup.head)# 获取第一个p标签中的所有内容print(soup.p)# 获取第一个p标签的id的值print(soup.p["id"])# 获取第一个a标签中的所有内容print(soup.a)# 获取所有的a标签中的所有内容print(soup.find_all("a"))# 获取id="u1"print(soup.find(id="u1"))# 获取所有的a标签,并遍历打印a标签中的href的值for item in soup.find_all("a"):
print(item.get("href"))# 获取所有的a标签,并遍历打印a标签的文本值for item in soup.find_all("a"):
print(item.get_text())登录后复制2. 对象种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment .
(1)Tag:Tag通俗点讲就是HTML中的一个个标签,例如:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>','lxml')
tag = soup.b
print(tag)
print(type(tag))登录后复制输出结果:
<b class="boldest">Extremely bold</b>
<class 'bs4.element.Tag'>
登录后复制Tag有很多方法和属性,在 遍历文档树 和 搜索文档树 中有详细解释.现在介绍一下tag中最重要的属性: name和attributes:
name属性:
print(tag.name)
# 输出结果:b
# 如果改变了tag的name,那将影响所有通过当前Beautiful Soup对象生成的HTML文档:
tag.name = "b1"
print(tag)
# 输出结果:<b1 class="boldest">Extremely bold</b1>
登录后复制Attributes属性:
# 取clas属性
print(tag['class'])
# 直接”点”取属性, 比如: .attrs :
print(tag.attrs)
登录后复制tag 的属性可以被添加、修改和删除:
# 添加 id 属性
tag['id'] = 1
# 修改 class 属性
tag['class'] = 'tl1'
# 删除 class 属性
del tag['class']
登录后复制(2)NavigableString:用.string获取标签内部的文字:
print(soup.b.string)print(type(soup.b.string))
登录后复制(3)BeautifulSoup:表示的是一个文档的内容,可以获取它的类型,名称,以及属性:
print(type(soup.name))
# <type 'unicode'>
print(soup.name)
# [document]
print(soup.attrs)
# 文档本身的属性为空
登录后复制(4)Comment:是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号。
print(soup.b)
print(soup.b.string)
print(type(soup.b.string))
登录后复制3. 搜索文档树
1.find_all(name, attrs, recursive, text, **kwargs)
(1)name 参数:name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉
匹配字符串:查找与字符串完整匹配的内容,用于查找文档中所有的
<a>标签a_list = soup.find_all("a")print(a_list)登录后复制匹配正则表达式:如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容
# 返回所有表示<body>和<b>标签for tag in soup.find_all(re.compile("^b")): print(tag.name)登录后复制匹配列表:如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回
# 返回所有所有<p>标签和<a>标签:soup.find_all(["p", "a"])
登录后复制
(2)kwargs参数
soup.find_all(id='link2')
登录后复制(3)text参数:通过 text 参数可以搜搜文档中的字符串内容,与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表
# 匹配字符串
soup.find_all(text="a")
# 匹配正则
soup.find_all(text=re.compile("^b"))
# 匹配列表
soup.find_all(text=["p", "a"])登录后复制4. css选择器
我们在使用BeautifulSoup解析库时,经常会结合CSS选择器来提取数据。
注意:以下讲解CSS选择器只选择标签,至于获取属性值和文本内容我们后面再讲。
1. 根据标签名查找:比如写一个 li 就会选择所有li 标签, 不过我们一般不用,因为我们都是精确到标签再提取数据的
from bs4 import BeautifulSoup
html = '''
<p class="panel">
<p class="panel-heading">
<h4>Hello</h4>
</p>
<p class="panel_body">
<ul class="list" id="list-1" name="element">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<a href="https://www.baidu.com">百度官网</a>
<li class="element">Bar</li>
</ul>
</p>
</p>
'''# 创建对象soup = BeautifulSoup(html, 'lxml')# 1. 根据标签名查找:查找li标签print(soup.select("li"))登录后复制输出结果:
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
登录后复制2. 根据类名class查找。.1ine, 即一个点加line,这个表达式选的是class= "line "的所有标签,".”代表class
print(soup.select(".panel_body"))登录后复制输出结果:
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>]
登录后复制3. 根据id查找。#box,即一个#和box表示选取id-”box "的所有标签,“#”代表id
print(soup.select("#list-1"))登录后复制输出结果:
[<ul class="list" id="list-1" name="element">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
登录后复制4. 根据属性的名字查找。class属性和id属性较为特殊,故单独拿出来定义一个". "和“”来表示他们。
比如:input[ name=“username”]这个表达式查找name= "username "的标签,此处注意和xpath语法的区别
print(soup.select('ul[ name="element"]'))登录后复制输出结果:
[<ul class="list" id="list-1" name="element">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
登录后复制5. 标签+类名或id的形式。
# 查找id为list-1的ul标签
print(soup.select('ul#list-1'))
print("-"*20)
# 查找class为list的ul标签
print(soup.select('ul.list'))登录后复制输出结果:
[<ul class="list" id="list-1" name="element">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
--------------------
[<ul class="list" id="list-1" name="element">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>, <ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>]
登录后复制6. 查找直接子元素
# 查找id="list-1"的标签下的直接子标签liprint(soup.select('#list-1>li'))登录后复制输出结果:
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>]
登录后复制7. 查找子孙标签
# .panel_body和li之间是一个空格,这个表达式查找id=”.panel_body”的标签下的子或孙标签liprint(soup.select('.panel_body li'))登录后复制输出结果:
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
登录后复制8. 取某个标签的属性
# 1. 先取到<p class="panel_body">p = soup.select(".panel_body")[0]# 2. 再去下面的a标签下的href属性print(p.select('a')[0]["href"])登录后复制输出结果:
https://www.baidu.com
登录后复制9. 获取文本内容有四种方式:
(a) string:获得某个标签下的文本内容,强调-一个标签,不含嵌我。 返回-个字符串
# 1. 先取到<p class="panel_body">p = soup.select(".panel_body")[0]# 2. 再去下面的a标签下print(p.select('a')[0].string)登录后复制输出结果:
百度官网
登录后复制(b) strings:获得某个标签下的所有文本内容,可以嵌套。返回-一个生成器,可用list(生成器)转换为列表
print(p.strings)print(list(p.strings))
登录后复制输出结果:
<generator object Tag._all_strings at 0x000001AA58E525F0>['\n', '\n', 'Foo', '\n', 'Bar', '\n', 'Jay', '\n', '\n', '\n', 'Foo', '\n', '百度官网', '\n', 'Bar', '\n', '\n']
登录后复制(c)stripped.strings:跟(b)差不多,只不过它会去掉每个字符串头部和尾部的空格和换行符
print(p.stripped_strings)print(list(p.stripped_strings))
登录后复制输出结果:
<generator object PageElement.stripped_strings at 0x000001F9995525F0>['Foo', 'Bar', 'Jay', 'Foo', '百度官网', 'Bar']
登录后复制(d) get.text():获取所有字符串,含嵌套. 不过会把所有字符串拼接为一个,然后返回
注意2:
前3个都是属性,不加括号;最后一个是函数,加括号。
print(p.get_text())
登录后复制输出结果:
Foo
Bar
Jay
Foo
百度官网
Bar
登录后复制【相关推荐:Python3视频教程 】
以上就是一文搞懂Python爬虫解析器BeautifulSoup4的详细内容,更多请关注自由互联其它相关文章!
