
程序员必备接口测试调试工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api设计、调试、文档、自动化测试工具
后端、前端、测试,同时在线协作,内容实时同步
【相关推荐:Python3视频教程 】
1.返回函数
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。我们在操作函数的时候,如果不需要立刻求和,而是在后面的代码中,根据需要再计算
例如下面
# -*- coding: utf-8 -*-# python 全栈# author : a wei # 开发时间: 2022/6/23 22:41def sum_fun_a(*args):
a = 0
for n in args:
a = a + n
return a登录后复制这是我不需要立即计算我的结果sum_fun方法,不返回求和的结果,而是返回求和的函数,例如下方
# -*- coding: utf-8 -*-# python 全栈# author : a wei # 开发时间: 2022/6/23 22:41def sum_fun_b(*args):
def sum_a():
a = 0
for n in args:
a = a + n return a return sum_a登录后复制当我们调用 sum_fun_b() 时,返回的并不是求和结果,而是求和函数 sum_a , 当我们在调sum_fun_b函数时将他赋值给变量
f1 = sum_fun_b(1, 2, 3, 4, 5)# 此时f为一个对象实例化,并不会直接生成值print(f1()) # 15f2 = sum_fun_b(1, 2, 3, 4, 5)f3 = sum_fun_b(1, 2, 3, 4, 5)print(f2, f3)<function sum_fun_b.<locals>.sum_a at 0x0000016E1E1EFD30> <function sum_fun_b.<locals>.sum_a at 0x0000016E1E1EF700>print(id(f2), id(f3))1899067537152 1899067538880
登录后复制此时我们直接拿到的值就是15,那可以想一想,此时 f = sum_a,那这里存在一个疑问参数去哪里了?
而且我们看到创建的两个方法相互不影响的,地址及值是不相同的
在函数 sum_fun_b 中又定义了函数 sum_a ,并且,内部函数 sum_a 可以引用外部函数 sum_fun_b 的参数和局部变量,当 sum_fun_b 返回函数 sum_a 时,而对应的参数和变量都保存在返回的函数中,这里称为 闭包 。
2.闭包
什么是闭包?
先看一段代码
# 定义一个函数def fun_a(num_a):# 在函数内部再定义⼀个函数# 并且这个内部函数⽤到了外部的变量,这个函数以及⽤到外部函数的变量及参数叫 闭包
def fun_b(num_b):
print('内嵌函数fun_b的参数是:%s,外部函数fun_a的参数是:%s' % (num_b, num_a))
return num_a + num_b
# 这里返回的就是闭包的结果
return fun_b# 给fun_a函数赋值,这个10就是传参给fun_aret = fun_a(10)# 注意这里的10其实是赋值给fun_bprint(ret(10))# 注意这里的90其实是赋值给fun_bprint(ret(90))登录后复制运行结果:
内嵌函数fun_b的参数是:10,外部函数fun_a的参数是:1020内嵌函数fun_b的参数是:90,外部函数fun_a的参数是:10100
登录后复制此时,内部函数对外部函数作⽤域⾥变量的引⽤(⾮全局变量),则称内部函数为闭包。
这里闭包需要有三个条件
"""
三个条件,缺一不可:
1)必须有一个内嵌函数(函数里定义的函数)——这对应函数之间的嵌套
2)内嵌函数必须引用一个定义在闭合范围内(外部函数里)的变量——内部函数引用外部变量
3)外部函数必须返回内嵌函数——必须返回那个内部函数
"""
登录后复制"python# python交互环境编辑器 >>> def counter(start=0):
count = [start]
def incr():
count[0] += 1
return count[0]
return incr
>>> c1 = counter(5)>>> print(c1()) 6>>> print(c1()) 7>>> c2=counter(50) >>> print(c2()) 51>>> print(c2()) >52>>>
登录后复制当一个函数在本地作用域找不到变量申明时会向外层函数寻找,这在函数闭包中很常见但是在本地作用域中使用的变量后,还想对此变量进行更改赋值就会报错
def test():
count = 1
def add():
print(count)
count += 1
return add
a = test() a()
登录后复制报错信息:
Traceback (most recent call last): ...... UnboundLocalError: local variable 'count' referenced before assignment
登录后复制如果我在函数内加一行nonlocal count就可解决这个问题
代码
# -*- coding: UTF-8 -*- # def test():
# count不是局部变量,介于全局变量和局部变量之间的一种变量,nonlocal标识
count = 1
def add():
nonlocal count
print(count)
count += 1
return count return add
a = test() a() # 1 a() # 2
登录后复制nonlocal声明的变量不是局部变量,也不是全局变量,而是外部嵌套函数内的变量。
如果从另一个角度来看我们给此函数增加了记录函数状态的功能。当然,这也可以通过申明全局变量来实现增加函数状态的功能。当这样会出现以下问题:
1. 每次调用函数时,都得在全局作用域申明变量。别人调用函数时还得查看函数内部代码。
3. 当函数在多个地方被调用并且同时记录着很多状态时,会造成非常地混乱。
登录后复制使用nonlocal的好处是,在为函数添加状态时不用额外地添加全局变量,因此可以大量地调用此函数并同时记录着多个函数状态,每个函数都是独立、独特的。针对此项功能其实还个一个方法,就是使用类,通过定义__call__ 可实现在一个实例上直接像函数一样调用
代码如下:
def line_conf(a, b):
def line(x):
return a * x + b
return line
line1 = line_conf(1, 1) line2 = line_conf(4, 5) print(line1(5))
print(line2(5))
登录后复制运行结果为
625
登录后复制从这段代码中,函数line与变量a,b构成闭包。在创建闭包的时候,我们通过line_conf的参数a,b说明了这两个变量的取值,这样,我们就确定了函数的最终形式(y = x + 1和y = 4x + 5)。我们只需要变换参数a,b,就可以获得不同的
直线表达函数。由此,我们可以看到,闭包也具有提⾼代码可复⽤性的作⽤。如果没有闭包,我们需要每次创建函数的时候同时说明a,b,x。这样,我们就需要更多的参数传递,也减少了代码的可移植性。
1.闭包似优化了变量,原来需要类对象完成的⼯作,闭包也可以完成
2.由于闭包引⽤了外部函数的局部变量,则外部函数的局部变量没有及时释放,消耗内存
登录后复制但是还没有结束,我们知道,函数内部函数,引用外部函数参数或值,进行内部函数运算执行,并不是完全返回一个函数,也有可能是一个在外部函数的值,我们还需要知道返回的函数不会立刻执行,而是直到调用了函数才会执
行。
看代码:
def fun_a():
fun_list = []
for i in range(1, 4):
def fun_b():
return i * i
fun_list.append(fun_b)
return fun_list
f1, f2, f3 = fun_a() print(f1(), f2(), f3())# 结果:9,9,9
登录后复制这里创建了一个fun_a函数,外部函数的参数fun_list定义了一个列表,在进行遍历,循环函数fun_b,引用外部变量i 计算返回结果,加入列表,每次循环,都创建了一个新的函数,然后,把创建的3个函数都返回了
但是实际结果并不是我们想要的1,4,9,而是9,9,9,这是为什么呢?
这是因为,返回的函数引用了变量 i ,但不是立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,每一个独立的函数引用的对象是相同的变量,但是返回的值时候,3个函数都返回时,此时值已经完整了运算,并存储,当调用函数,产生值不会达成想要的,返回函数不要引用任何循环变量,或者将来会发生变化的变量,但是如果一定需要呢,如何修改这个函数呢?
我们把这里的i赋值给_就可以解决
def test3():
func_list = []
for i in range(1, 4):
def test4(i_= i):
return i_**2
func_list.append(test4)
return func_list
f1, f2, f3 = test3()print(f1(), f2(), f3())登录后复制可以再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变,那我们就可以完成下面的代码
# -*- coding: UTF-8 -*- # def fun_a():
def fun_c(i):
def fun_b():
return i * i
return fun_b
fun_list = []
for i in range(1, 4):
# f(i)立刻被执行,因此i的当前值被传入f()
fun_list.append(fun_c(i))
return fun_list
f1, f2, f3 = fun_a() print(f1(), f2(), f3()) # 1 4 9
登录后复制3.装饰器 wraps
什么是装饰器?
看一段代码:
# -*- coding: utf-8 -*-# python 全栈# author : a wei # 开发时间: 2022/6/24 17:03def eat():
print('吃饭')def test1(func):
def test2():
print('做饭')
func()
print('洗碗')
return test2
eat() # 调用eat函数# 吃饭test1(eat)()# 做饭# 吃饭# 洗碗登录后复制由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数。也可以将函数赋值变量,做参传入另一个函数。
1>什么是装饰器
"""
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值 也是一个函数对象。
它经常用于有以下场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。装饰器是解决这类问题的绝 佳设计
"""
登录后复制装饰器的作用就是为已经存在的对象添加额外的功能
先看代码:
# -*- coding: utf-8 -*-# python 全栈# author : a wei # 开发时间: 2022/6/24 17:03def test1(func):
def test2():
print('做饭')
func()
print('洗碗')
return test2@test1 # 装饰器def eat():
print('吃饭')eat()# 做饭# 吃饭# 洗碗登录后复制我们没有直接将eat函数作为参数传入test1中,只是将test1函数以@方式装饰在eat函数上。
也就是说,被装饰的函数,函数名作为参数,传入到装饰器函数上,不影响eat函数的功能,再此基础上可以根据业务或者功能增加条件或者信息。
(注意:@在装饰器这里是作为Python语法里面的语法糖写法,用来做修饰。)
但是我们这里就存在一个问题这里引入魔术方法 name 这是属于 python 中的内置类属性,就是它会天生就存在与一个 python 程序中,代表对应程序名称,一般一段程序作为主线运行程序时其内置名称就是 main ,当自己作为模块被调用时就是自己的名字
代码:
print(eat.__name__)# test2
登录后复制这并不是我们想要的!输出应该是" eat"。这里的函数被test2替代了。它重写了我们函数的名字和注释文档,那怎么阻止变化呢,Python提供functools模块里面的wraps函数解决了问题
代码:
-*- coding: utf-8 -*-
from functools import wrapsdef test1(func):
@wraps(func)
def test2():
print('做饭')
func()
print('洗碗')
return test2@test1 # 装饰器def eat():
print('吃饭')eat()# 做饭# 吃饭# 洗碗print(eat.__name__)# eat登录后复制我们在装饰器函数内,作用eat的test2函数上也增加了一个装饰器wraps还是带参数的。
这个装饰器的功能就是不改变使用装饰器原有函数的结构。
我们熟悉了操作,拿来熟悉一下具体的功能实现,我们可以写一个打印日志的功能
# -*- coding: utf-8 -*-# python 全栈# author : a wei # 开发时间: 2022/6/24 17:42import timefrom functools import wrapsdef logger(func):
@wraps(func)
def write_log():
print('[info]--时间:%s' % time.strftime('%Y-%m-%d %H:%M:%S'))
func()
return write_log@loggerdef work():
print('我在工作')work()# [info]--时间:2022-06-24 17:52:11# 我在工作print(work.__name__)#work登录后复制2>带参装饰器
我们也看到装饰器wraps也是带参数的,那我们是不是也可以定义带参数的装饰器呢,我们可以使用一个函数来包裹装饰器,调入这个参数。
# -*- coding: utf-8 -*-# python 全栈# author : a wei # 开发时间: 2022/6/24 17:42import timefrom functools import wrapsdef logs(func):
@wraps(func)
def write_log(*args, **kwargs):
print('[info]--时间:%s' % time.strftime('%Y-%m-%d %H:%M:%S'))
func(*args, **kwargs)
return write_log@logsdef work():
print('我在工作')@logsdef work2(name1, name2):
print('%s和%s在工作' % (name1, name2))work2('张三', '李四')# [info]--时间:2022-06-24 18:04:04# 张三和李四在工作登录后复制3>函数做装饰器
把日志写入文件
# -*- coding: utf-8 -*-# python 全栈# author : a wei# 开发时间: 2022/6/20 0:06import timefrom functools import wrapsdef logger(file):
def logs(fun):
@wraps(fun)
def write_log(*args, **kwargs):
log = '[info] 时间是:%s' % time.strftime('%Y-%m-%d %H:%M:%S')
print(log)
with open(file, 'a+') as f:
f.write(log)
fun(*args, **kwargs)
return write_log return logs@logger('work.log') # 使用装饰器来给 work函数增加记录日志的功能def work(name, name2): # 1.当前 work可能有多个参数 2.自定义日志文件的名字和位置,记录日志级别
print(f'{name}和{name2}在工作')work('张三', '李四')登录后复制终端输出: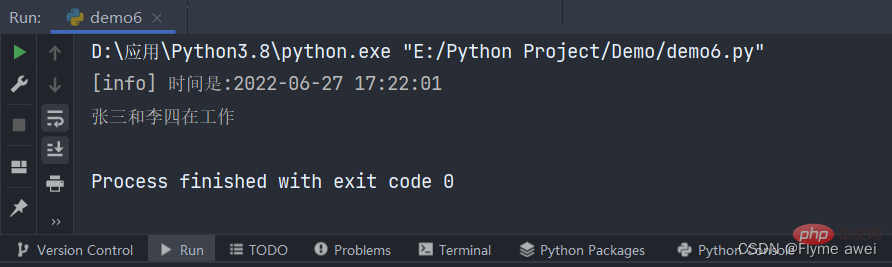
这里生成里work.log日志文件
里面记录日志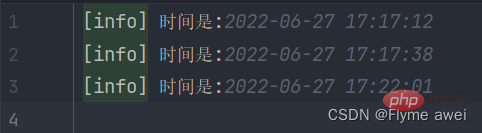
这里我们将带参数的带入进去根据代码流程执行生成了文件并将文件打印进去现在我们有了能用于正式环境的logs装饰器,但当我们的应用的某些部分还比较脆弱时,异常也许是需要更紧急关注的事情。
比方说有时你只想打日志到一个文件。而有时你想把引起你注意的问题发送到一个email,同时也保留
日志,留个记录。
这是一个使用继承的场景,但目前为止我们只看到过用来构建装饰器的函数。
4>类做装饰器
# -*- coding: utf-8 -*-# python 全栈# author : a wei# 开发时间: 2022/6/20 0:06import timefrom functools import wraps# 不使用函数做装饰器,使用类做装饰器class Logs(object):
def __init__(self, log_file='out.log', level='info'):
# 初始化一个默认文件和默认日志级别
self.log_file = log_file
self.level = level def __call__(self, fun): # 定义装饰器,需要一个接受函数
@wraps(fun)
def write_log(name, name2):
log = '[%s] 时间是:%s' % (self.level, time.strftime('%Y-%m-%d %H:%M:%S'))
print(log)
with open(self.log_file, 'a+') as f:
f.write(log)
fun(name, name2)
return write_log@Logs() # 使用装饰器来给 work函数增加记录日志的功能def work(name, name2): # 1.当前 work可能有多个参数 2.自定义日志文件的名字和位置,记录日志级别
print(f'{name}和{name2}在工作')work('张三', '李四') # 调用work函数登录后复制这个实现有一个优势,在于比嵌套函数的方式更加整洁,而且包裹一个函数还是使用跟以前一样的语法
4.偏函数 partial
Python的 functools 模块提供了很多有用的功能,其中一个就是偏函(Partial function)。要注意,这里的偏函数和数学意义上的偏函数不一样。
在介绍函数参数的时候,我们讲到,通过设定参数的默认值,可以降低函数调用的难度。而偏函数也可以做到这一点。
例如:int() 函数可以把字符串转换为整数,当仅传入字符串时, int() 函数默认按十进制转换
>>> int('123') 123登录后复制但 int() 函数还提供额外的 base 参数,默认值为 10 。如果传入 base 参数,就可以做进制的转换
>>> int('12345', base=8) 5349 >>> int('12345', 16) 74565登录后复制如果要转换大量的二进制字符串,每次都传入 int(x, base=2) 非常麻烦,于是,我们想到,可以定义一个int2() 的函数,默认把 base=2 传进去:
代码:
# 定一个转换义函数 >>> def int_1(num, base=2):
return int(num, base)
>>> int_1('1000000') 64>>> int_1('1010101') 85登录后复制把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单
继续优化,functools.partial 就是帮助我们创建一个偏函数的,不需要我们自己定义 int_1() ,可以直接使用下面的代码创 建一个新的函数 int_1
# 导入 >>> import functools
# 偏函数处理 >>> int_2 = functools.partial(int, base=2) >>> int_2('1000000') 64>>> int_2('1010101') 85登录后复制理清了 functools.partial 的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
注意到上面的新的 int_2 函数,仅仅是把 base 参数重新设定默认值为 2 ,但也可以在函数调用时传入其他值实际上固定了int()函数的关键字参数 base
int2('10010')登录后复制相当于是:
kw = { base: 2 } int('10010', **kw)登录后复制当函数的参数个数太多,需要简化时,使用 functools.partial 可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单
【相关推荐:Python3视频教程 】
以上就是一文掌握Python返回函数、闭包、装饰器、偏函数的详细内容,更多请关注自由互联其它相关文章!
