虽然现在分布式计算系统大行其道,但是我们依然不会忘记传统的超大型计算机架构,基于NUMA技术的超大型计算机服务器系统依然在数据中心计算范围中仍然发挥着重要作用。NUMA(Non Uniform Memory Access)技术具有可以使众多服务器像单一系统那样运转,同时保留小系统便于编程和管理的优点。
但事实上,这些NUMA系统的制造商越来越少。基本上只剩下IBM的基于Power10的16插槽Power E1080和未来基于Telum 处理器的16插槽System z16;使用Intel的Cooper Lake至强SP 8380H处理器的基于HP Superdome X和SGI NUMAlink 8技术的混合的Superdome Flex等。
IBM的最新服务器是基于Power10的 Denali Power E1080。新的 IBM 机器是以北美最高的山Denali(麦金利山)命名的,这座山位于阿拉斯加,海拔6193 米。因此有人预计,2024 年左右使用 Power11 芯片的 Power E1180 将被称为 Aconcagua(阿空加瓜山,南美最高峰,位于阿根廷,海拔6962米),而 2027 年左右到期的 Power 1280 将被称为珠穆朗玛峰。
在那之后,有了可能的 Power 1380,我们必须去火星寻找更高的山峰——奥林匹斯山,这是一座高达21171米的盾状火山。或者,也许到 2030 年左右,IBM 将完成 NUMA 处理器业务,命名将不再是问题。这很难说。但如果真的发生这种情况,Power11 和 Power12 可以在很长一段时间内为 IBM 的客户提供服务。HPE很乐意尽其所能地利用SGI/Superdome混合机--主要用于运行SAP HANA内存数据库和应用程序,偶尔作为超级计算机集群的大内存节点--而甲骨文自从让Sun Microsystems淡出后,就对超大型计算机显示出兴趣。
现在我们可以肯定的是,蓝色巨人仍然相信big-iron,并且在交付第一台 Power10 的机器时,它正在开发 Power11。
现在,让我们揭开这个机器怪兽的神秘面纱。
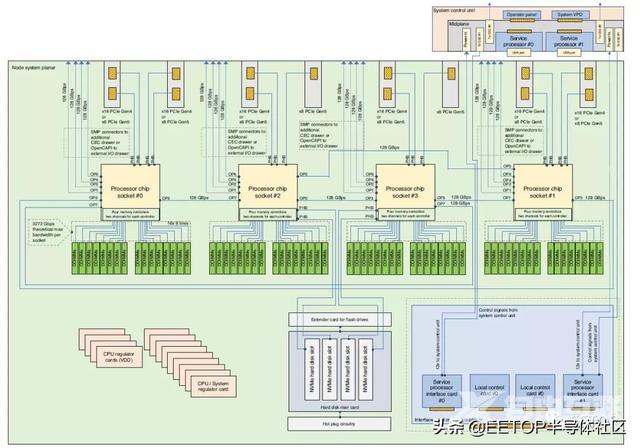
与之前基于 Power 处理器的 IBM 六代高端 NUMA 机器和其他大型 X86 机器一样,Power E1080 系统以四路服务器节点作为其基本构建块。
此基础机箱中的四个处理器使用片上 NUMA 电路紧密耦合,Power10 芯片还具有额外的 NUMA 电路,可将多达四个节点连接到一个 16 插槽的机器中。

以下是 Denali 系统的四插槽基础机箱的示意图:
下面是揭开盖子后 Denali 的内部照片:

上图中从左到右依次是左边的I/O和系统互连,接着是四组Power10处理器,然后是64个DDR4内存插槽,最右边是风扇和闪存驱动器。
这是一个非常令人满意的base-2架构,因为本地节点中的计算和内存是紧密耦合的,节点中任何两个处理器缓存和内存之间只有一个fast hop。它与特定节点外部的任何Power10芯片只有一到两个hops的距离。有一个与应用相匹配的延迟层次,特别是那些适合相对较小的虚拟机的应用。
重要的是,NUMA拓扑结构随着每一代处理器内核的增加而变得越来越扁平,这就是为什么IBM不需要像2004年基于双核Power5芯片的Power 595系统那样将插座推到32个。那时需要8个处理器卡,每个卡有4个双核芯片,才能达到64个核心,而现在只需要4个处理器卡就能做到240个核心。同样重要的是,任何在一个核心上工作的应用程序或数据库都能以合理的线性性能扩展到所有240个核心。并具有合理的线性性能。扁平的 SMP 系统无法扩展到这个地步。大多数 NUMA 系统也不能,当它们这样做时,在四个或八个插槽后性能下降得非常快。
IBM还在开发一款非常出色的四插座机器,它将使用Power10双芯片模块(DCM),在非常狭小的空间中塞进四个物理插座。到目前为止,我们看到的所有设计都是基于16核的Power10芯片,每个核心有8个线程,也就是IBM所说的SMT8。IBM可以对Power10芯片进行不同的分区(就像它对Power9芯片所做的那样),以一半的线程数产生两倍的内核。(所以每个芯片 30 个内核作为单芯片模块或 SCM,每个插槽最多 60 个内核作为 DCM。)到目前为止,IBM 还没有这样做,但它可能会在明年某个时候推出入门机器。
在 Denali 系统中交付的 Power10 芯片具有三种规格:
- 10 核版本,基本速度为 2.65GHz,睿频高达 3.9GHz;
- 12 核版本,基本速度为 3.6GHz,睿频高达 4.15GHz;
- 15 核版本,基本速度为 3.55GHz,睿频高达 4GHz。
这些是我们在 Power8 和 Power9 处理器的 SMT8 版本中看到的时钟速度范围。这意味着 Power E1080 节点可以有 40、48 或 60 个核心,而具有四个节点的成熟机器可以有 160、192 或 240 个核心。
IBM 尚未发布 Power E1080 系统的完整基准测试结果,但它在今天的发布活动中确实表示 Power10 E1080 的性能是 2004 年 Power 595 的 6.9 倍:
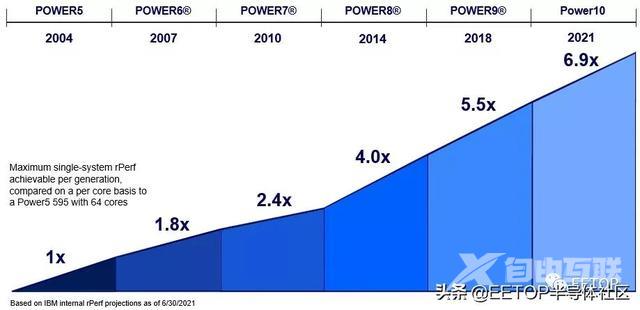
从2004年到2021年,高端系统性能增长的一半来自核心的增加,另一半来自让每个内核做更多的工作。Power10指令集已经在一个新的微体系结构中扩展并完全重新实现,该微体系结构将现有整数、浮点数和小数点(货币数学)的数据类型扩展为新的矩阵数学,该矩阵数学适用于机器学习推断和其他可能的HPC工作负载。Power E1080的推理性能是运行在Power9矢量引擎上的混合精度数学的10倍,当矩阵数学加速器或 MMA 支持 32 位精度时,那么在今年晚些时候或明年年初,这一性能将提高到20倍。(每个核心有四个MMA)
在谈到性能时,IBM 表示 Power E1080 每个插槽的吞吐量性能比它所取代的 Power E980 高出 50%,并且两台机器上的插槽数都达到了 16 个插槽,这意味着系统性能也提高了高出 50%。
Power E1080 服务器对 IBM 及其客户很重要,因为它是第一台实现 OpenCAPI 内存接口(简称 OMI)的机器。借助OMI,IBM正在使用它创建的32Gb/sec SerDes来做NVLink、OpenCAPI和NUMA互连等I/O,将核心与主存储器连接起来。这种接口比DDR4内存控制器慢一点,但它占用的面积更小,消耗的能量也更少,这使得IBM在Power9和Power10机器之间把内存控制器和内存插槽的数量增加了两倍。通过将内存控制器和插槽增加一倍,IBM可以将每个插座的带宽增加一倍,同时使用更便宜、更薄的内存卡来获得一定的容量。
对于企业级Power8和Power9机器—对应的是Power E880C、Power E980和Power E1080, IBM使用了其 "Centaur"内存缓冲器,它实现了L4缓存,并充当了缓冲内存控制器。在Denali系统中,有16个OMI链接从处理器出来(每个链接由8个OMI通道组成,运行速度为32Gb/sec),每个通道可以驱动自己的差分DIMM(DDIMM)。Power E1080内存卡各有四个DDIMM,DDIMM上有32GB和64GB容量的内存卡(因此总容量为128GB或256GB)以3.2GHz运行,而使用更厚的128GB和256GB DDIMM的内存卡(因此提供512GB和1024GB的容量)以较慢的2.93GHz运行。这意味着使用较薄内存的Power10插座可以提供409.6GB/秒的带宽,而使用较厚内存的Power10插座可以提供375.4GB/秒的带宽。
OMI 存储卡:

以下是基于 Power8 的 Power E880C、基于 Power9 的 Power E980 和基于 Power10 的 Power E1080 的对比:
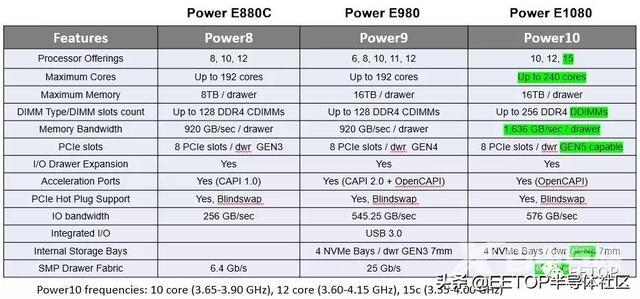
Power E1080 的核心数增加了 25%,从而提高了吞吐量性能。最大内存保持不变,但 IBM 可以使用更便宜的 DIMM,由于每个插槽的内存控制器和插槽增加了一倍,带宽增加了 1.79 倍。每个节点的内存带宽与 GPU 加速器相当。I/O 子系统的带宽与转向 PCI-Express 5.0外围控制器的带宽大致相同,但 IBM 只需要一半的通道就可以在 Power E1080 系统中为每个节点提供 576GB/秒的带宽。
IBM 现在正在接受 Power E1080 系统的订单,预计从 9 月 17 日开始发货单节点或双节点配置。这些早期机器仅支持每个节点最多 4TB。IBM 将从 10 月开始抢先体验三节点和四节点配置,并计划在 12 月提供这些更丰富的设置以及更丰富的 OMI 内存。
样子服务器架构