CPU的核心竞争力在于微架构等因素决定的性能先进性和生态丰富性。国内CPU厂商分别以X86/MIPS/ARM等指令集为起点,大力投入研发保持架构先进,推动产业开放构建自主生态,加速追赶全球头部企业。

一、CPU:计算机的大脑
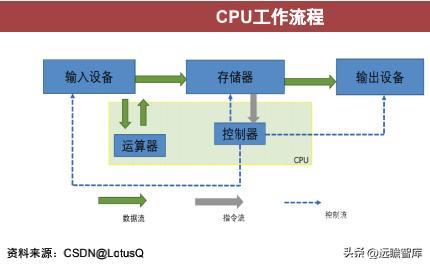
CPU本质是一块大规模的集成电路,主要由运算器和控制器组成。
CPU是计算机的运算和控制核心。
它的主要功能可以分为两点:1)解释计算机中的指令;2)对数据进行运算处理。
CPU性能决定计算机运行的快慢,其性能的提升带来计算机运算效率的提高。
CPU的工作流程主要分为三个阶段:取指、解码和执行。
控制器从计算机内存里读取指令(取指),经过翻译之后(解码),通知运算器加载/计算/保存(执行)。
CPU产业链:设计→制造→封装测试
CPU产业链主要包括芯片设计、芯片制造、封装测试三个主要环节。此外,在上游还包括设计技术授权、EDA软件等支持技术。
芯片设计:将芯片的逻辑、系统以及性能转化为具体实物芯片设计的过程。该环节具有知识密集型特点,有较高的附加值和利润率,奠定了产品性能的基调。
芯片制造:将图纸制作成刻好电路的晶圆,其生产过程包括流片(试生产)、晶棒制造、晶圆制造、完成电路及元件加工与制作。
封装测试:封装是将晶圆加工为芯片的过程,测试是对芯片质量进行检测的过程。这一过程的门槛和风险都相对较低,国产厂商具有相对优势。

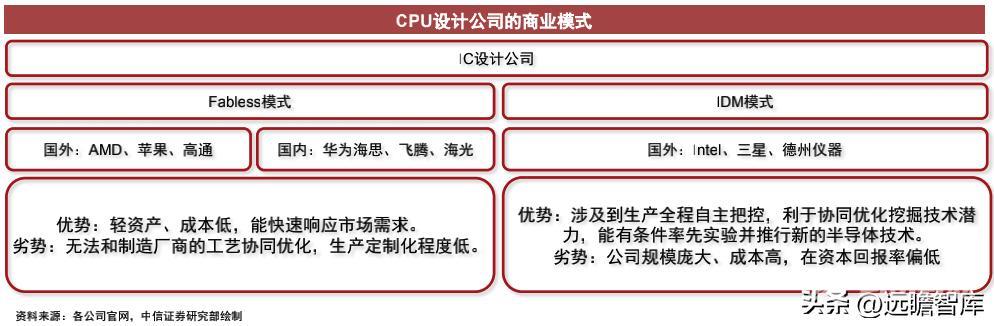
IC 设计公司的商业模式主要分为两类:IDM模式和 Fabless 模式。
IDM模式指的是Integrated Design and Manufacture,垂直整合制造模式,即一家公司包揽芯片的设计、制造、封测等,早期的集成电路企业大多使用这种模式,但是由于成本过高,只有少数企业,如Intel、三星、德州仪器等能够维持这种模式。
Fabless模式指的是专注芯片设计、研发和销售的模式,不包含芯片的制造、封测。而Foundry指的是专门负责芯片制造生产的厂家。

二、CPU性能:决定CPU是否“能用”
性能好坏决定CPU是否“能用”,是商业化落地的核心要素之一。运行程序的速度基本决定了CPU的性能。
CPU性能评价比较的通用公式为:性能=(IPC*主频)/指令数量。
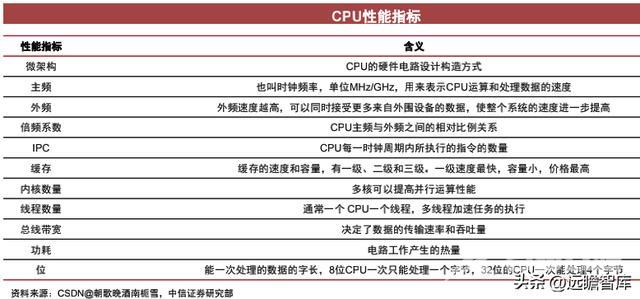
评估CPU性能的参数主要包括:微架构、主频、内核/线程、缓存大小、制程、功耗等,除主频为外参数通常都影响IPC值。CPU主频越高,IPC越高,CPU的性能越强。
我们认为,评估CPU性能的指标依次为:微架构、制程>核数/线程>互联>主频>缓存>其他。
CPU性能影响因素:制程、内核、线程
我们认为各类参数中,微架构、制程、核数/线程、互联、主频等参数/维度对CPU的性能影响较大。
制程:CPU集成电路的密集度。同样数量晶体管,更小的制程意味着更低的功耗和发热。如今主流工艺制程为7纳米(AMD最新产品),先进制程可达3纳米。
内核:CPU核心的计算组成部分。
线程:CPU内核调度和分配的基本单位。使得一个核心内有多个逻辑CPU来分别执行功能,实现高效率的并行计算。
对于能够并行执行的场景来说,例如视频剪辑、虚拟机等专业应用,通常内核/线程越多,CPU的计算性能越强,但在超过一定数量范围后,核心之间的通讯也会拖累计算速度,最终抵消掉多内核/线程带来的性能提升。
对于顺序执行的场景,例如解压缩、视频编解码、图片编辑、办公应用、影音娱乐、游戏等场景,更为注重的是CPU单核的性能强度。

主频:CPU的时钟频率,处理器每秒工作次数。时钟频率的高低在很大程度上反映了CPU计算速度的快慢,常在电脑参数中里可以看到的3.3GHZ,4.0GHZ等就是CPU的主频参数。
功耗:CPU的发热量。功耗增加将导致芯片发热量的增大和可靠性的下降。
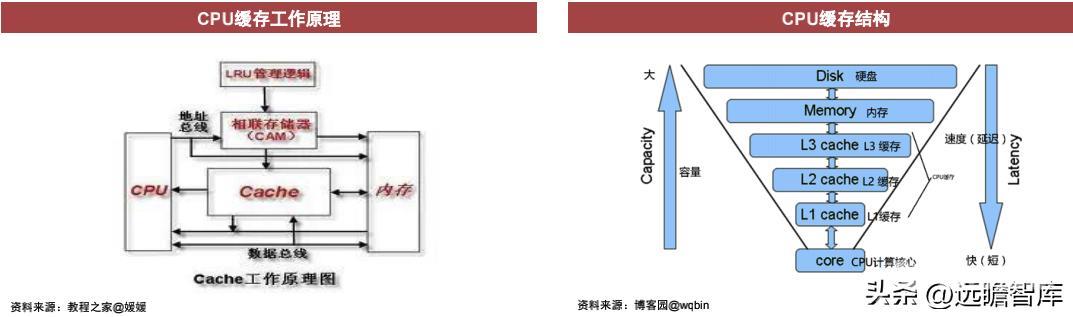
缓存:指可以进行高速数据交换的存储器,它先于内存与CPU交换数据。用于减少处理器访问内存所需平均时间。
缓存分为一级(L1)、二级(L2)、三级(L3)缓存,在读取速度上L1>L2>L3,容量大小上L1<L2<L3。缓存越大CPU运行越快,但成本越高。
微架构的先进性:保持CPU性能领先的关键
微架构(Micro Architecture):CPU的硬件电路设计构造方式。
微架构又称为微体系结构或者微处理器体系结构,是给定的指令集在处理其中的执行方法。某一给定指令集可以在不同微架构中执行,但在实施中可能因设计目的和技术效果有所不同。
微架构包括取址单元、译指单元、执行单元、计算单元、访存单元等部分。
CPU使用取址单元从内存中取出代码段,依次在各微架构中进行处理,最终将内存读写指令发给存访单元,完成内存读写。
不同微架构决定了CPU各方面性能的不同,Intel、AMD两大巨头纷纷将微架构视作提高产品性能的关键。

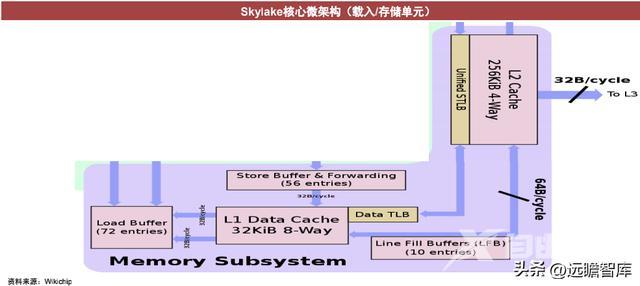
以Intel skylake典型架构为例
核心架构分为前端(黄色部分)、执行引擎(绿色部分)、载入/存储单元(紫色部分)三部分。其中执行引擎与载入/存储单元又并称为后端。
在微架构中要依次完成1)取指、2)解码(译码)、3)执行、4)写回,完成一次指令的执行。
取指:从内存中获取指令,明确CPU要执行的程序。
解码:将程序指令解码为计算机内部的微操作,需要将一个指令分解为多个操作。
执行:执行解码后的指令,如加、减、乘、除、与、或、非;还会进行分支预测。
写回:CPU将执行结果储存在执行储存器或内存中。
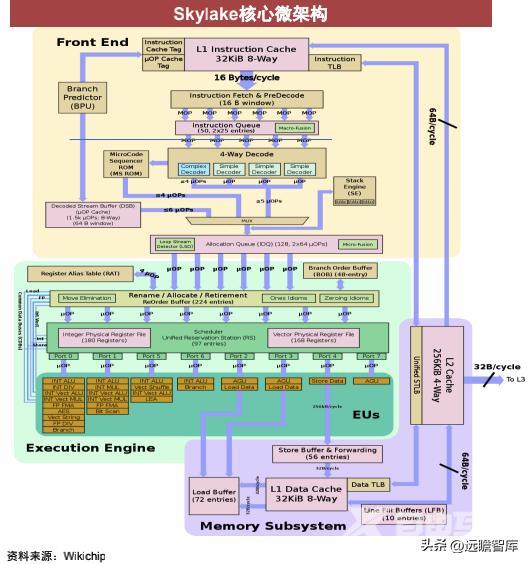
前端:取指、译码
Decode(译码):把IQ中的指令译码成μop,skylake为四路译码,包括3个简单译码器和1个复杂译码器。
Branch Predictor(分支预测):预测指令分支的方向。
Skylake译码流水线每周期译码出5条微指令,上代只有4条;增强了分支预测能力;增大前端容量,提高取指、译码效率。
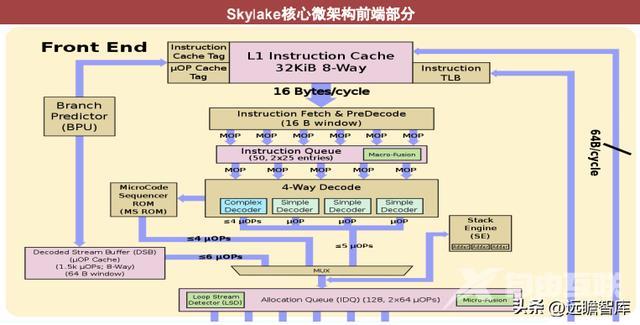
执行引擎:这一部分有大量的执行单元、调度器、寄存器等部件。包括浮点执行与整数执行两部分,分别执行不同的运算。
Scheduler:乱序执行时,进行μop的调度分配。
ALU:算数逻辑单元,不同ALU执行不同运算,包括整数计算、浮点计算、矢量计算等。
Skylake与上一代相比,增加了更多的执行单元、缩短延迟、提高指令执行速度。
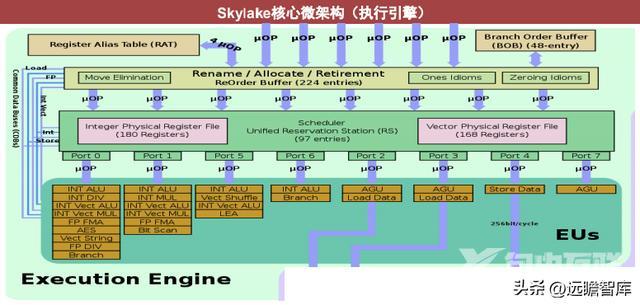
载入/存储单元:将结果存储在寄存器或者内存。
L1、L2 cache:位于CPU与内存之间的临时存储器,容量小于内存,但速度更快,从缓存中调用数据可以极大提高CPU运行速度。
Skylake在这部分比上一代实现带宽提高,改进预取器,提高了存储速度,加深存储、写回缓冲。
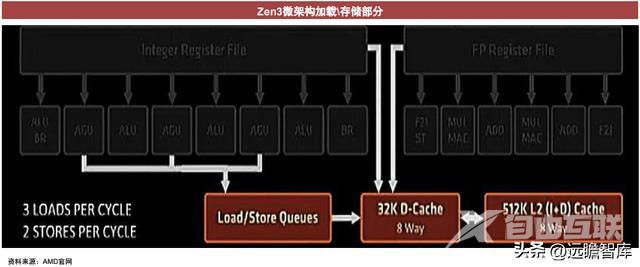
架构的先进性:以Zen3先进架构为例
微架构的设计影响CPU可以达到的最高主频、最高IPC次数、CPU的能耗水平等。
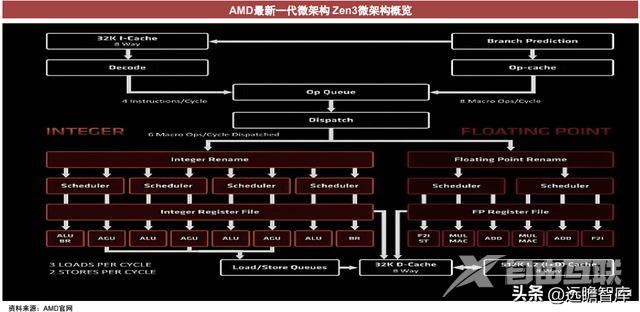
Zen3、Zen2微架构对比
2021年Hot Chips会上,AMD提到Zen3微架构层面的改进提升了单线程性能,扩大了缓存,IPC提升19%,同时降低了能耗。
Zen 3架构相比于Zen 2的升级:1)更高的时钟周期指令数:Zen 3架构可以从每MHz频率中平均实现19%的额外性能。2)更低的延迟:Zen 3通过在芯片上实现各资源相邻以充分减少通信时间。3)架构设计的升级:更全面的执行资源、更高的加载/存储带宽等。
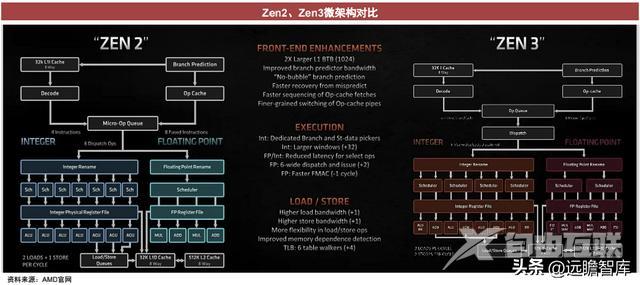
以Zen3先进架构为例
前端分为预解码、解码、指令融合、分支预测、指令融合等部分,主要功能为从内存中获取指令和将指令解码为计算机的操作。
Zen3升级了更快的分支预测,“Zen 3”架构可以从每MHz频率中平均提高19%的性能。在分支预测出现错误之后,AMD更优化的前端能够加快回到正确路径的速度,从而提高了分支预测的精度和CPU整体的性能。
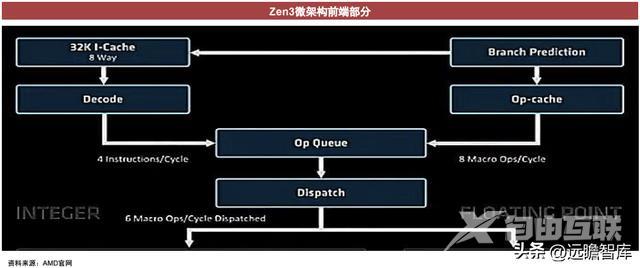
执行引擎:执行解码后的指令,分为整数执行、浮点执行、矩阵执行等部分,执行不同类型的运算。
整数重排缓冲区与浮点重排缓冲区分开,分别进行分配和执行。
Zen 3架构提高了浮点和整数执行单元的宽度和灵活性,来提高执行能力。
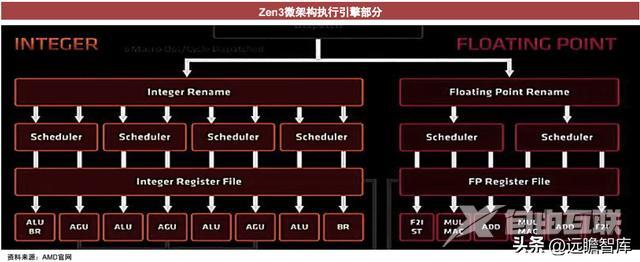
加载/存储单元:将结果存储在寄存器或者内存。
缓存cache:暂存μop,以便后续使用,加快指令执行效率。
更高的载入带宽(2个增加到3个)、更高的存储带宽(1个增加到2个)、更灵活的载入/存储指令、更好的内存依赖检测。
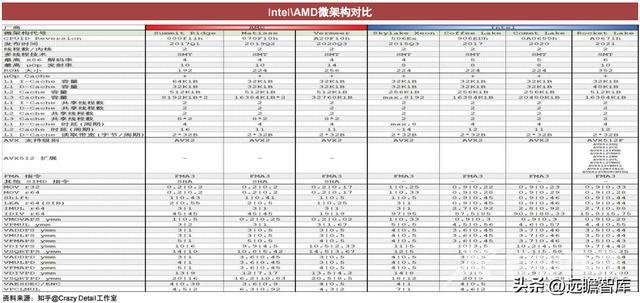
Intel\AMD微架构对比
在公开的测评数据中,采用Zen 3架构的AMD锐龙芯片性能居于榜首。Rocket Lake与AMD的Zen 3性能相近,但Rocket Lake仍采用14纳米制程,功耗和散热较高。
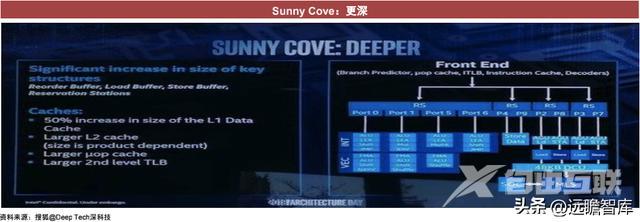
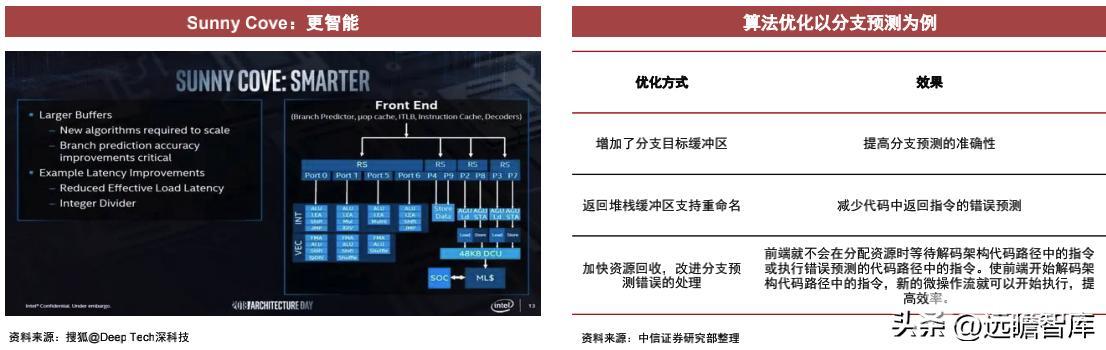
微架构未来方向:更深、更宽、更智能
更深:在并行计算中执行更多的操作。在并行计算中执行更多操作本质是加快计算的速度,提高单一计算的效率。采用分支预测、乱序执行来提高流水线上执行的效率来实现这一目的。当执行任务时遇到条件分支的跳转或者指令逻辑的混乱会降低指令执行的效率,分支预测后根据预测结果选择下一个指令,乱序计算可以自行纠正指令执行的逻辑,提高效率。Sunny Cove在关键架构上的提升包括重新排序缓冲区,加载缓冲区等,在内存方面,L1扩大50%,更大的L2,更大的微指令(μop)缓存等。
更宽:同时进行更多的并行计算。并行计算是相对于串行计算的概念。并行计算能够在同一时间处理更多问题,从而提高计算速度,有利于解决更复杂、规模更大的问题。执行更多的并行计算的方法有超标量执行(运算时增加寄存器暂存结果)、使用多核CPU(多核同时工作处理更多信息)等。
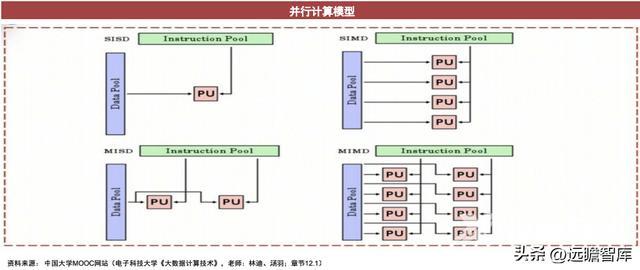
Sunny Cove架构中,宽度分配由4组提升到5组,执行端口由8个增至10个,存储带宽增加。

更智能:优化算法提高运行效率
优化微架构中运行单元的算法,如流水线和分支预测的具体实现方式等,提高处理同一指令的效率。运行单元的数量、延迟、吞吐量(将资料存到或是读取出存储器的速度)都会影响微架构的性能。Sunny Cove微架构与前一代相比,提高了分支预测精度,并有效降低负载延迟,增加整数分频器。
CPU性能测试
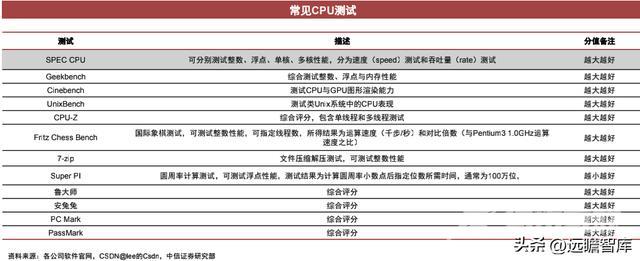
我们可以用CPU核心数量、缓存大小、工作主频、制程节点来粗略衡量CPU的性能,但这些指标无法很好地反映CPU架构设计带来的性能差别,所以往往需要通过各种测试来全面反映CPU性能。
下表为常见CPU测试,但学术界使用最多的还是SPEC测试,SPEC测试共有六版,分别为SPEC 2017、SPEC 2006、SPEC 2000、SPEC 1995、SPEC 1992、SPEC 1989,SPEC 2017为最新版。
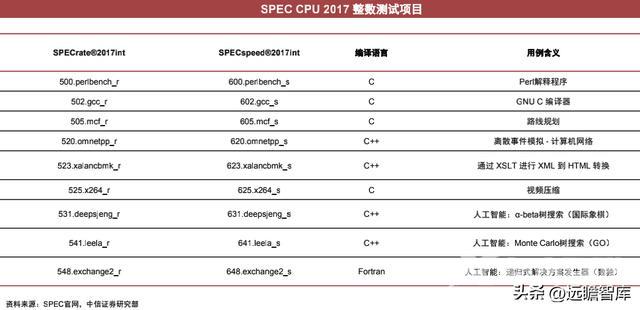
CPU性能测试:SPEC CPU 2017测试
SPEC CPU 2017测试包含4大种类套件、共43个测试。分为浮点型和整型测试,其中又分为速度(speed单个事务处理时长)和速率(rate并发事务处理能力)两种测试方式,测试结果得分越高越好。
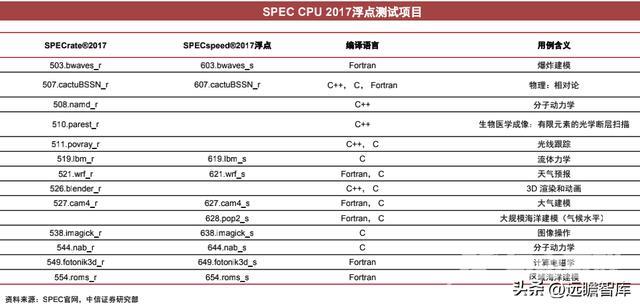
SPEC CPU 2017是在SPEC CPU 2006的基础上针对CPU性能的发展进行的一些改动和升级。
SPEC 2006时期,基本上CPU都没有L3或者L3容量很小,随着技术的发展,CPU L3不断变大,整个测试甚至都无需再次访存工作集,针对这一点SPEC进行了改进。此外SPEC删减了一些有争议的项目,并与时俱进地调整、删减了部分过时的项目,增加新的项目。
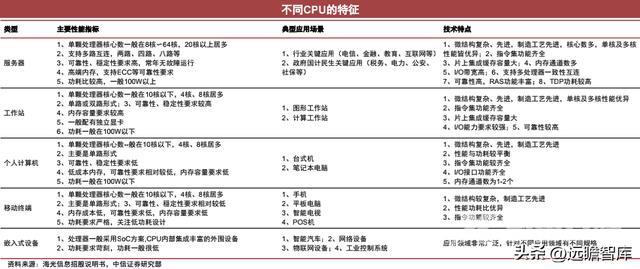
应用场景:服务器/PC/嵌入式等领域对CPU性能侧重不同
高性能、低功耗、低成本构成了CPU的不可能三角。
不同应用场景的CPU对性能的侧重各有不同,选择CPU时,依据不可能三角进行取舍。
服务器CPU需要高性能,多核多路高可靠、大内存、大IO带宽;PC需要性能功耗平衡、IO接口齐全;移动端要求低功耗、高能效;嵌入式要求超低功耗超低成本等。

三、CPU指令集:决定CPU运行的底层逻辑
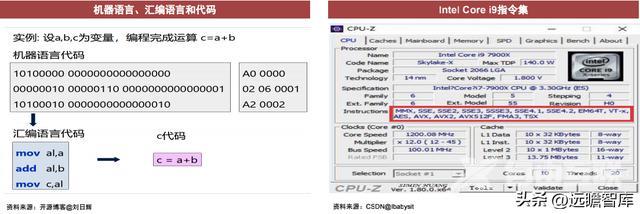
CPU指令集:指挥机器工作的指示和命令。
系统发出的每一个命令,都需要CPU(硬件)根据预设好的指令来完成,预设的很多指令集中在一起就是“指令集”。
例如,英特尔X86指令集中的单指令多数据流指令集可以实现数据级并行,包括MMX、SSE、AVX。其中,MMX指令集指的是多媒体扩展指令集。SSE是单指令多数据流扩展指令集。AVX是高级矢量拓展指令集。
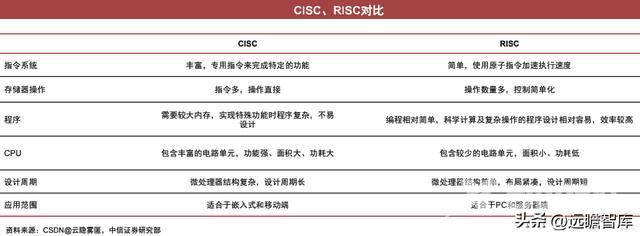
CPU指令集:可分为CISC复杂和RISC简单指令集
目前,指令集可以分为复杂指令集(CISC)和简单指令集(RISC)。
Reduced Instruction Set Computing (RISC) :精简指令集,它由最简单的指令组成,以提高指令执行速度。如完成喝水的动作,大脑中储存的动作为拿起杯子,吞咽等。当执行时需要执行细分步骤。
Complex Instruction Set Computing (CISC) :复杂指令集,其包含丰富的复杂指令集来节约内存。将更多功能步骤集成在了CPU中,如将喝水的完整步骤储存在大脑中,执行时直接执行完整的喝水过程。
CPU指令集:CISC和RISC逐步融合
CISC的出现更早,随着计算机指令发展得越来越复杂,为了简化指令集而诞生的RISC出现较晚。
如今指令集升级的方向是“更多”、“更全”。
指令集的迭代更多侧重于对于原有的指令集进行增量性的扩充升级,而非将原有的指令集完全替换。目前的新CPU普遍支持更全面、更多的指令集子类。
复杂指令集与简单指令集的融合趋势自上世纪后期一直保持至今。
比如,Intel在1989年推出的80486处理器就吸收了RISC所擅长的流水线技术,为了采用流水线,Intel在CPU中添加了解码器,将原始的X86指令解码成简短的微指令(μ-ops),经过解码后,X86CPU的运行与RISC差异或正在缩小。

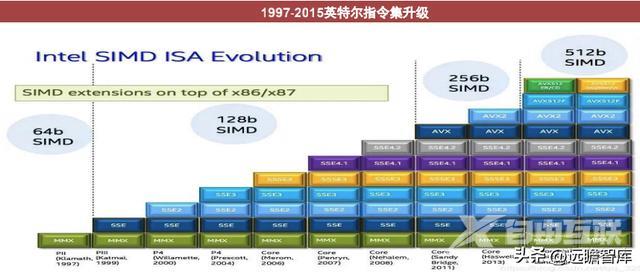
CPU指令集:以Intel指令集升级为例
Intel沿用的指令集包括MMX > SSE > SSE2 > SSE3 > SSSE3 > SSE4.1 > SSE4.2 > AVX > AVX2 > AVX-512,指令集的升级采用增量升级的方式。
例如:MMX是Intel推出较早的一项指令集,包括57条多媒体指令,作用是一次处理多个数据,在处理结果超过实际能力的时候也能正常处理;SSE对图像处理、浮点运算、3D运算、视频音频处理等多媒体运算起到全面增强的作用。
Intel指令集还包括扩展指令集,以适应不同使用场景需求,如EM64T为服务器和工作站平台提供扩充的内存寻址能力。
CISC和RISC逐步融合:以ARM为例
ARM通过指令集的升级实现CPU性能跃升,在原有指令集中增添新的指令实现升级。
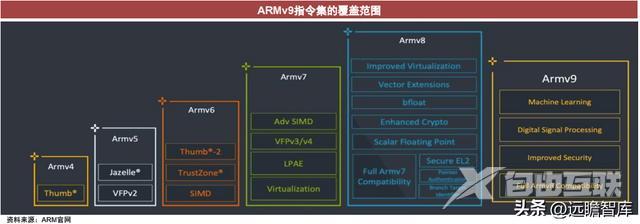
ARMv4增加了16位Thumb指令集,作用是减少指令的存储空间。
ARMv5引入SIMD指令,将语音及图像的处理功能提升至原来的4倍。
ARMv6引入了混合16位/32位的Thumb-2指令集,与Thumb相比减少使用31%的内存,性能提高40%。
ARMv8引入A64指令集,使架构可以在AArch64(针对64位处理技术)下运行,同时原有指令集可在AArch32状态运行。
ARMv9可以完全兼容ARMv8,同时提高了安全性、机器学习能力、向量处理能力和数字信号处理能力。
CPU指令集:特性决定应用领域
早期指令集的特性决定应用领域。
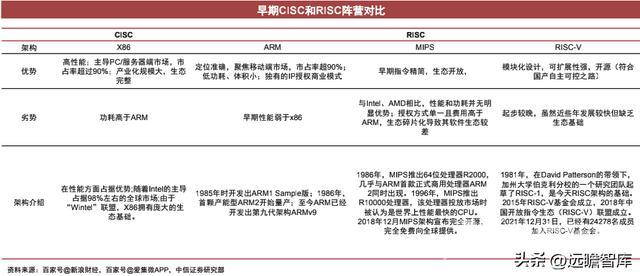
根据不同的指令集和架构特点,适用于不同的领域。其中RISC指令集具有低功耗的特点,衍生出ARM、MIPS和RISC-V等指令架构,广泛应用于嵌入式和移动领域;CISC以高性能著称,代表是X86指令架构,广泛应用于PC端和服务器端。
CPU指令集:生态的源头
指令集是生态的源头,生态要针对相应的指令集架构进行兼容优化,才能最大限度和稳定的发挥软件性能。
CPU的生态包括相应操作系统,工具链以及应用软件,一定规模的生态将构筑起CPU行业的进入壁垒。
Wintel、AA体系高筑生态壁垒,形成主导。
两大主导生态体系:1)基于X86指令系统和Windows操作系统的Wintel体系;2)基于 ARM 指令系统和 Android 操作系统的 AA 体系。
Wintel凭借高性能X86架构与先发优势占领桌面 CPU 市场;AA依靠开源、可二次开发指令结构的优势立足于低功耗、性能需求较低的移动市场。
生态决定进入壁垒的高低
X86高性能利于进入PC和服务器市场,高生态壁垒造就主导。
在PC端和服务器市场,X86系列以极高的性能与Windows绑定形成“Wintel”主导联盟,主流的厂商都是基于X86系列对软件进行兼容优化,从而在PC和服务器市场上建立起了庞大的生态体系。重构生态环境的高成本形成进入壁垒。
ARM低功耗利于进入移动端,生态闭环实现主导。
凭借独特的IP授权的商业模式,成功在移动终端、嵌入式设备的某些细分领域占据90%以上份额,形成完整生态闭环。桌面PC市场,ARM份额逐渐变大,苹果MacOS、新版windows均采用ARM。国内企业中,华为鲲鹏也采用ARM服务器。
MIPS指令集在工控机、网络设备中应用广泛,国内某L厂商为重要玩家。
RISC-V指令集具有开源、精简、可扩展性强、可定制化特点,十分契合物联网、5G、AI等新兴领域的应用,国内外企业纷纷布局,或将成为中国芯片自主化的关键突破口。

我们认为,从性能和成本出发,ARM在服务器和PC端市场替代X86存在可能性。
性能:随着技术的不断迭代,现阶段CISC与RISC已逐步走向融合;同时ARM架构性能方面不输于X86,且功耗低、性能设计自由度高、自主化程度强。
成本:在云端采用ARM平台服务器,可以做到端云同构,大幅节省原先云端x86+边缘端ARM开发调试成本,使各大企业有充足动力更换服务器端指令架构。
如今ARM凭借性能、成本等优势,在低端市场实力较强,但Arm发布的Neoverse V1和N2在性能上有很大提升,有望进一步挑战x86架构。

指令集发展趋势1:ARM在服务器端有望打破生态壁垒逐步替代X86
在服务器和PC端市场,巨头开始拥抱Arm生态。
2020年,苹果新一代Mac book Air发布,使用了基于ARM架构的M1处理器,跑分结果超过Intel i9处理器。华为云、微软Azure、Google也一直计划部署ARM服务器。
我们认为:1)短期内,X86架构的生态护城河极为宽阔。ARM架构突破需要一定的积累。2)中长期来看,ARM系若大力投入打造完整的产业生态,打通在服务器端稳定性和生态壁垒,有望占据更多市场份额。

指令集发展趋势2:RISC-V新型的开源架构
RISC-V被业内寄予厚望,可能挑战ARM的地位。
从特性来说,RISC-V是一种开源、开放的架构,应用更加灵活,指令简单,开发成本低于ARM。
在IoT、AI、边缘计算等新兴领域,RISC-V有很强的竞争力,比ARM更有优势。
RISC-V发展在中国获得政策支持。
2018年7月,上海将 RISC-V 列入政府扶持对象,为国内首例。
2018年11月8日,中国开放指令生态(RISC-V)联盟(简称 CRVA)成立,中国科学院院士倪光南为理事长,副理事长包括学术界与业界成员,旨在促进产学结合推动RISC发展。
中国企业纷纷入局RISC-V。
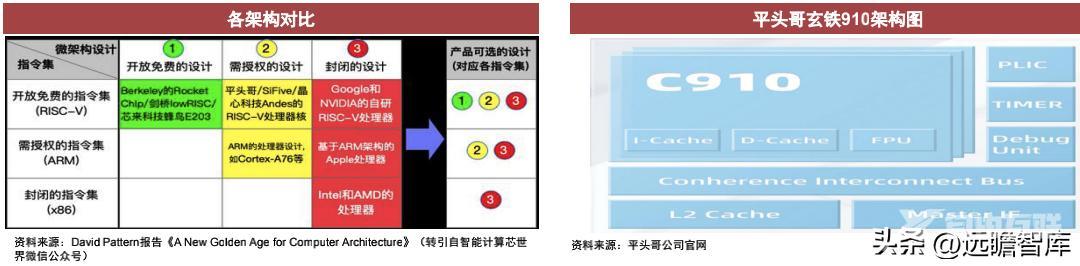
平头哥、芯来科技、兆易创新、华米科技等新创立企业纷纷瞄准RISC-V架构。2019年7月,平头哥发布玄铁910,性能超过当时最好的RISC-V处理器,可以应用于智能驾驶等领域。
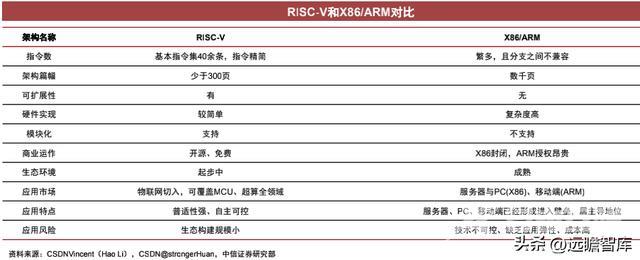
RISC-V:设计简单、模块化、可拓展性强
RISC-V架构具有免费、开源的特征,其不仅允许使用者修改架构相关源代码,更直接给出基于此的商业授权。
RISC-V具有以下三个基本特征:
1)设计简单。RISC-V架构指令集文档的篇幅相对X86和ARM架构大幅减少。2)模块化。在模块化的实现方式下,RISC-V便于用户将各模块进行组合来满足不同需求。3)可扩展性。RISC-V支持第三方的扩展,用户可以扩展自己的指令子集,实现定制化。
RISC-V:借助AIoT和边缘计算的浪潮,国内外RISC-V生态建设加速推动
指令简单、可扩展性强的RISC-V架构,适应物联网、边缘计算时代灵活性和要求低成本的特点,受到了全球厂商们的关注和使用。
国内外RISC-V生态建设加速推动。
加州大学伯克利分校在2015年成立非盈利组织RISC-V基金会,截止2021年12月已经有来自七十多个国家、超过两千名成员加入。
国产RISC-V架构相关产品加快商业化进程,平头哥、华米、兆易创新等企业已发布了RISC-V架构可商用化产品。
