目录
- 背景
- 问题
- 原因
- 总结
事情是这样的,最近在写一个Node功能的时候,遇到了一个正则的问题,觉得挺有意思的,就记录一下经历和最终问题原因,希望也能帮助到同样遇到的同学。
背景
我有一个Node服务,希望对访问进来的请求进行标记,如果请求进来的path是我定义的路由,那么将标记一个REQ,否则标记一个IVL,用于对于整个服务的日志记录进行输出。那么我通过服务启动时,根据定义的路由,生成一个RouterMap,通过访问进入时,判断path是否命中RouterMap来判断是否预期访问。
大概的代码如下:
export function getSourceMak(
routerMap: AppRouterMap[],
req: http.IncomingMessage,
): SourceMark.REQ | SourceMark.IVL | SourceMark.TST {
const { url, method, headers } = req;
const pathname = url.split('?')[0];
const userAgent = headers['user-agent'];
// 安全扫描
if (userAgent?.includes('TST(Tencent') && userAgent.includes('Team)')) {
return SourceMark.TST;
}
for (const item of routerMap) {
const { reg } = item;
if (reg.test(pathname) && item.method === method.toLocaleLowerCase()) {
return SourceMark.REQ;
}
}
return SourceMark.IVL;
}
因为涉及到一些动态路由的原因,不能直接通过path进行相等判断,需要对相应的路由规则生成一个对应的正则表达式,并且在服务启动时生成,保存在内存中进行复用。
生成正常代码如下:
export function createRouterRegexp(url) {
const urlBlock = url.split('/');
const regBlock = urlBlock.map((block) => {
if (block[0] === ':') {
return '((?!/).)*';
}
return block;
});
return new RegExp(`^${regBlock.join('/')}$`, 'ig');
}
问题
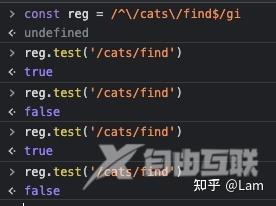
然后在进行调试的时候发现一个奇怪的现象,假设我有一个路由为GET /cats/find的路由,通过打点发现对应的正则表达式,/^\/cats\/find$/gi对/cats/find进行匹配的时候,第一次为true,第二次为false,第三次为true,第四次为false,以此类推。
经过反复验证,node代码并没有存在问题,正则表达式也没有问题,那么我在浏览器中尝试复现一下,也是得出同样的问题。至此我很确定,一定是有一些正则相关的坑是我以前没有注意到。于是我反查了一下JavaScript的文档,终于被我找到原因。
原因
通过查找MDN正则相关的文档,被查到以下说明
"nolink">当设置全局标志的正则使用test()
如果正则表达式设置了全局标志,test() 的执行会改变正则表达式 lastIndex属性。连续的执行test()方法,后续的执行将会从 lastIndex 处开始匹配字符串,(exec() 同样改变正则本身的 lastIndex属性值).
下面的实例表现了这种行为:
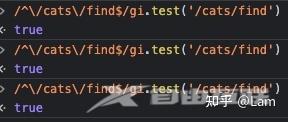
var regex = /foo/g;
// regex.lastIndex is at 0
regex.test('foo'); // true
// regex.lastIndex is now at 3
regex.test('foo'); // false
RegExp.prototype.test() - JavaScript | MDN
这不就是我遇到的问题吗?
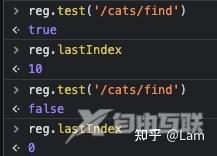
通过文档说明得知,当我们正则表达式带有g标识进行全局匹配时,匹配成功后,regex实例中会有一个lastIndex属性去记录本次命中正则的最后一位的下标+1,用于在下一次调用test的时候,从lastIndex开始进行匹配。 以前我没有遇到过大概率是因为以下原因:
每次进行正则校验时,都重新生成正则实例:/^\/cats\/find$/gi.test('/cats/find') 。
但是因为这次我将正则实例保存,并反复使用。从而导致问题。
并且通过验证得出,当匹配成功后,lastIndex会记录下一次开始的位置,但是当匹配失败,lastIndex会归零从头开始。
至此这一次被坑经历耗时60分钟左右,耽误了吃饭最佳时间,导致饭堂菜都快没有。但是同时也收获到JavaScript在正则上一个容易被忽略的坑。好像也不亏。
总结
到此这篇关于一次JavaScript正则的诡异经历记录的文章就介绍到这了,更多相关JavaScript正则经历内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!