目录 1. 为什么 HashSet 中使用 PRESENT 而不是 null 作为 value 1.1. PRESENT 是个什么玩意 1.2. HashSet 的构造方法 1.3. PRESENT 何时会被用到 1. 为什么 HashSet 中使用 PRESENT 而不是 null 作为 value 无意之
目录
- 1. 为什么 HashSet 中使用 PRESENT 而不是 null 作为 value
- 1.1. PRESENT 是个什么玩意
- 1.2. HashSet 的构造方法
- 1.3. PRESENT 何时会被用到
1. 为什么 HashSet 中使用 PRESENT 而不是 null 作为 value
无意之中碰到了这个问题,在此记录一下
1.1. PRESENT 是个什么玩意
HashSet 的部分源码如下
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable {
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
}
1.2. HashSet 的构造方法
// 默认构造函数 底层创建一个HashMap
public HashSet() {
// 调用HashMap的默认构造函数,创建map
map = new HashMap<E,Object>();
}
// 带集合的构造函数
public HashSet(Collection<? extends E> c) {
// 创建map。
map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16));
// 将集合(c)中的全部元素添加到HashSet中
addAll(c);
}
// 指定HashSet初始容量和加载因子的构造函数
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
// 指定HashSet初始容量的构造函数
public HashSet(int initialCapacity) {
map = new HashMap<E,Object>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
}
1.3. PRESENT 何时会被用到
- add(E) 方法
- remove(Object) 方法

1.3.1. HashSet 中的 add(E) 方法
/**
* add(E) 方法返回 null 时,表示 HashSet 添加数据成功
*
* @return true 如果不包含该元素
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
直接调用的是 HashMap 的 put(K, V) 方法,此时传入的 value 值是 PRESENT
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// tab表示 Node<K,V>类型的数组,p表示某一个具体的单链表 Node<K,V> 节点
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判断 table[] 是否为空,如果是空的就创建一个 table[],并获取他的长度n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// tab[i = (n - 1) & hash] 表示数组中的某一个具体位置的数据
// 如果单链表 Node<K,V> p == tab[i = (n - 1) & hash]) == null,
// 就直接 put 进单链表中,说明此时并没有发生 Hash 冲突
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 说明索引位置已经放入过数据了,已经在单链表处产生了Hash冲突
Node<K,V> e; K k;
// 判断 put 的数据和之前的数据是否重复
if (p.hash == hash &&
// 进行 key 的 hash 值和 key 的 equals() 和 == 比较,如果都相等,则初始化数组 Node<K,V> e
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 判断是否是红黑树,如果是红黑树就直接插入树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 如果不是红黑树,就遍历每个节点,判断单链表长度是否大于等于 7,
// 如果单链表长度大于等于 7,数组的长度小于 64 时,会优先选择扩容
// 如果单链表长度大于等于 7,数组的长度大于 64 时,才会选择单链表--->红黑树
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 采用尾插法,在单链表中插入数据
p.next = newNode(hash, key, value, null);
// 如果 binCount >= 8 - 1
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 判断索引每个元素的key是否可要插入的key相同,如果相同就直接覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
// 此时说明 key 的 hash 值和 key 的 equals() 和 == 比较结果都相等
// 说明数组或者单链表中有完全相同的 key
// 因此只需要将value覆盖,并将oldValue返回即可
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 说明没有key相同,因此要插入一个key-value,并记录内部结构变化次数
++modCount;
// 判断是否扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
关于 HashMap 的 put(K, V) 方法的 详细解析请看这里
- 如果 return oldValue 说明发生了 value 覆盖,也就是说此时返回了 PRESENT,自然而然 HashMap 添加数据失败
- 如果 return null 说明 HashMap 添加数据成功
而如果将 PRESENT 替换为 null 作为 value 值,那么 HashSet 的 add(E) 方法将无法判断添加元素的成功与失败;因为不管是成功与失败都会返回结果 null
1.3.2. HashMap 进行 put 元素示例
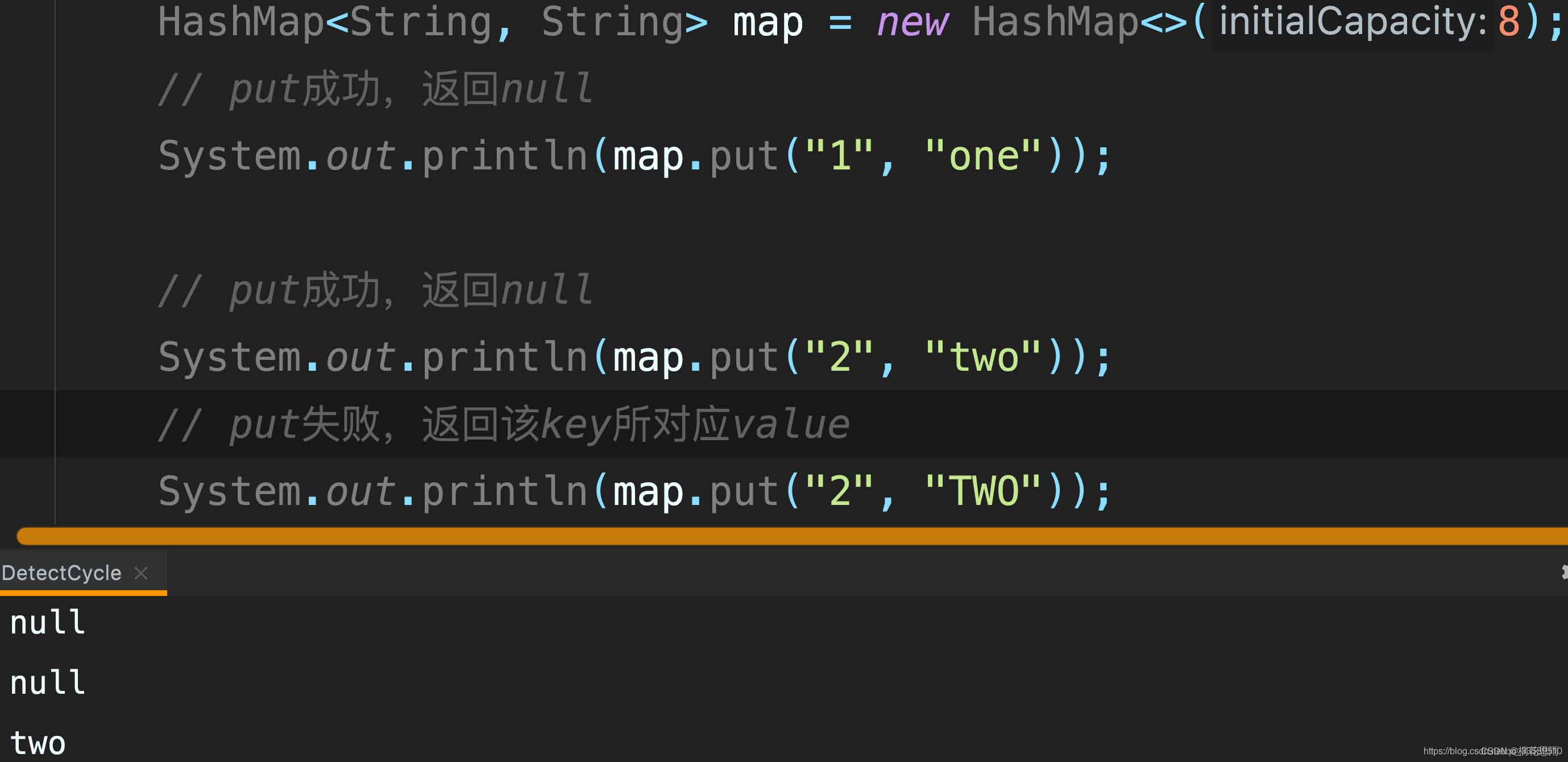
1.3.3. HashSet 中的 remove(Object) 方法
HashSet 的 remove(Object) 方法源码
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
HashSet 的 remove(Object) 依旧直接使用 HashMap 的 remove(Object) 方法
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
HashMap 的 remove(Object) 方法会返回 null 或 value
- 有该值,返回 value 也就是 PRESENT,表示 remove 成功
- 无该值,返回 null,自然而然 remove 失败
而如果将 PRESENT 替换为 null 作为 value 值,那么 HashSet 的 remove(Object) 方法将无法判断移除元素的成功与失败;因为不管是成功与失败都会返回结果 null
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自由互联。