目录 一、题目描述 二、解题思路 三、代码详解 一、题目描述 题目实现:做一个解析指定网址的网页内容小应用。 二、解题思路 创建一个类:InternetContentFrame,继承JFrame窗体类。 定义
目录
- 一、题目描述
- 二、解题思路
- 三、代码详解
一、题目描述
题目实现:做一个解析指定网址的网页内容小应用。
二、解题思路
创建一个类:InternetContentFrame,继承JFrame窗体类。
定义一个getURLCollection()方法:用于解析网页内容
使用URLConnection类的getInputStream()方法 获取网页资源的输入流对象。
三、代码详解
InternetContentFrame
package com.xiaoxuzhu;
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.EventQueue;
import java.awt.Font;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
/**
* Description:
*
* @author xiaoxuzhu
* @version 1.0
*
* <pre>
* 修改记录:
* 修改后版本 修改人 修改日期 修改内容
* 2022/5/23.1 xiaoxuzhu 2022/5/23 Create
* </pre>
* @date 2022/5/23
*/
public class InternetContentFrame extends JFrame {
private JTextArea ta_content;
private JTextField tf_address;
/**
* Launch the application
* @param args
*/
public static void main(String args[]) {
EventQueue.invokeLater(new Runnable() {
public void run() {
try {
InternetContentFrame frame = new InternetContentFrame();
frame.setVisible(true);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* Create the frame
*/
public InternetContentFrame() {
super();
setTitle("解析网页中的内容");
setBounds(100, 100, 484, 375);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
final JPanel panel = new JPanel();
getContentPane().add(panel, BorderLayout.NORTH);
final JLabel label = new JLabel();
label.setText("输入网址:");
panel.add(label);
tf_address = new JTextField();
tf_address.setPreferredSize(new Dimension(260,25));
panel.add(tf_address);
final JButton button = new JButton();
button.addActionListener(new ActionListener() {
public void actionPerformed(final ActionEvent e) {
String address = tf_address.getText().trim();// 获得输入的网址
Collection urlCollection = getURLCollection(address);// 调用方法,获得网页内容的集合对象
Iterator it = urlCollection.iterator(); // 获得集合的迭代器对象
while(it.hasNext()){
ta_content.append((String)it.next()+"\n"); // 在文本域中显示解析的内容
}
}
});
button.setText("解析网页");
panel.add(button);
final JScrollPane scrollPane = new JScrollPane();
getContentPane().add(scrollPane, BorderLayout.CENTER);
ta_content = new JTextArea();
ta_content.setFont(new Font("", Font.BOLD, 14));
scrollPane.setViewportView(ta_content);
//
}
public Collection<String> getURLCollection(String urlString){
URL url = null; // 声明URL
URLConnection conn = null; // 声明URLConnection
Collection<String> urlCollection = new ArrayList<String>(); // 创建集合对象
try{
url = new URL(urlString); // 创建URL对象
conn = url.openConnection(); // 获得连接对象
conn.connect(); // 打开到url引用资源的通信链接
InputStream is = conn.getInputStream(); // 获取流对象
InputStreamReader in = new InputStreamReader(is,"UTF-8"); // 转换为字符流
BufferedReader br = new BufferedReader(in); // 创建缓冲流对象
String nextLine = br.readLine(); // 读取信息,解析网页
while (nextLine !=null){
urlCollection.add(nextLine); // 解析网页的全部内容,添加到集合中
nextLine = br.readLine(); // 读取信息,解析网页
}
}catch(Exception ex){
ex.printStackTrace();
}
return urlCollection;
}
}
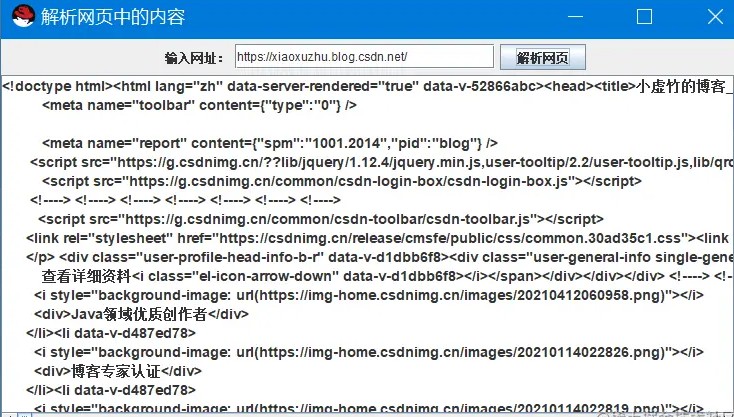
解析结果:
到此这篇关于利用Java实现解析网页中的内容的文章就介绍到这了,更多相关Java解析网页内容内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!