目录 用python读取excel表中的数据 这里再多说一下,np.hstack()函数和 np.vstack()函数: 总结 用python读取excel表中的数据 假如说有如下一张存储了数据的excel表,其中x1-x6是特征,y_la
目录
- 用python读取excel表中的数据
- 这里再多说一下,np.hstack()函数和 np.vstack()函数:
- 总结
用python读取excel表中的数据
假如说有如下一张存储了数据的excel表,其中x1-x6是特征,y_label是特征对应的类别标签。我们想要使用python对以下数据进行数据分析,那么第一步就要先把excel表中的数据读取出来才行。这里我们主要使用到了python中的pandas库。
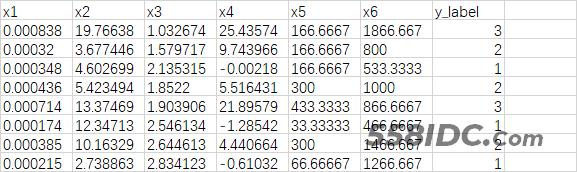
首先确定excel表存放的路径所在,比如我的路径是 ‘E:\relate_code\svm\dataset\data.xlsx’.
import pandas as pd file_path = r'E:\relate_code\svm\dataset\data.xlsx' # r对路径进行转义,windows需要 raw_data = pd.read_excel(file_path, header=0) # header=0表示第一行是表头,就自动去除了 print(raw_data)
这样就可以取出数据了,输出见下图。可以看出,这里就没有表中的x1等表头信息了。
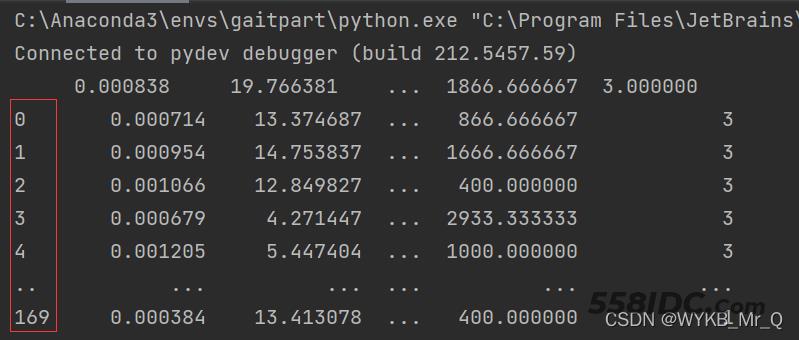
但是,最左边这里还有0-169这些行号额外信息,咱们可以用以下命令只要里面的有用信息,并保存到数组中。
data = raw_data.values # 只提取表中信息 print(data)
输出结果:
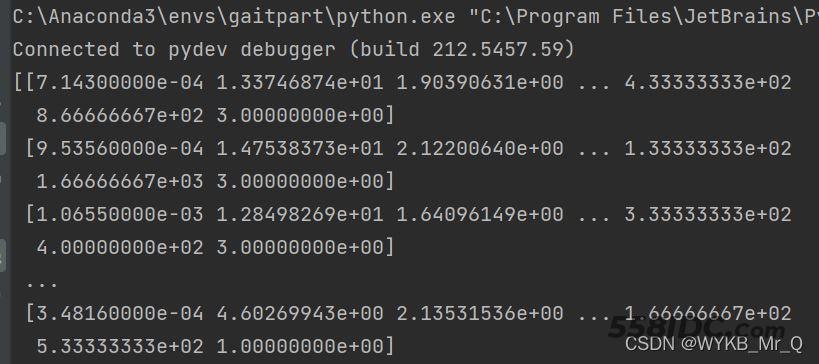
这时候数据就都读进来了,并且存储为了数组形式。咱们可以选择想要的数据,比如想把x和y分开,毕竟一个是特征,另一个是标签,这时候可以使用以下代码。
features = data[:, 0:6] # 由于是二维数组,所以第一个冒号表示选择所有行,之后0:6表示只要前六列的数据 labels = data[:, -1] # 标签只要最后一列
1、还可以对特征进行选择,假如只要第四列的特征也可以使用:
feature_4 = data[: 3:4] # 这样得出的数组依然是二维数组,便于后续特征操作
2、如果不想要第四个特征,其它都想要,也可以这样使用,需要用到numpy库:
import numpy as np feature1_3 = data[:, 0:3] # 取前三列特征 feature5_6 = data[:, 4:6] # 取第5,第6列特征 feature_choose = np.hstack(feature1_3, feature5_6) # 对两份特征进行特征拼接
这里再多说一下,np.hstack()函数和 np.vstack()函数:
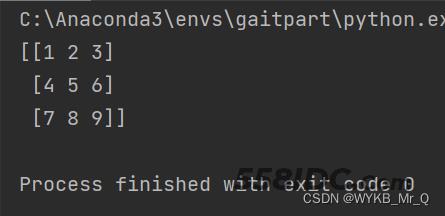
这里是np.vstack()函数。主要是进行竖直堆叠,使用这个函数的时候要保证两个数组列数是一致的(都是三列),得出的结果如下。
import numpy as np arr1 = np.array([[1, 2, 3], [4, 5, 6]]) arr2 = np.array([7, 8, 9]) print(np.vstack((arr1, arr2)))
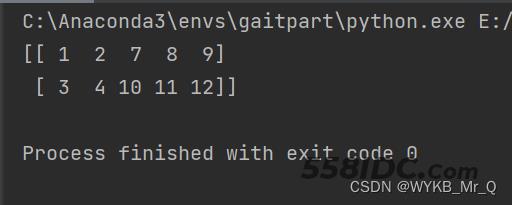
下面是np.hstack()函数,主要是进行水平堆叠,使用这个函数的时候要保证行数是一致的(都是两行)。
import numpy as np arr1 = np.array([[1, 2], [3, 4]]) arr2 = np.array([[7, 8, 9], [10, 11, 12]]) print(np.hstack((arr1, arr2)))
就先介绍到这里吧,下一篇文章介绍机器学习的代码使用!
总结
到此这篇关于利用Python读取Excel表内容的文章就介绍到这了,更多相关Python读取Excel表内容内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!