目录 1. 数据介绍 2. 案例演示 2.1 获取数据 2.2 查看数据基本信息 2.3 数据分析 2.3.1 效率值相关性分析 本案例使用 Jupyter Notebook进行案例演示,数据集为NBA球员信息数据集。本项目将进行
目录
- 1. 数据介绍
- 2. 案例演示
- 2.1 获取数据
- 2.2 查看数据基本信息
- 2.3 数据分析
- 2.3.1 效率值相关性分析
本案例使用 Jupyter Notebook进行案例演示,数据集为NBA球员信息数据集。本项目将进行完整的数据分析演示。
1. 数据介绍
- 数据集共有342个球员样本,38个特征,即342行×38列。
- 数据集主要信息如下表所示:
- 本数据集主要可以用来做数据处理以及数据挖掘,进行数据可视化。
- 本小结,我们将对NBA球员数据集进行初步统计学分析,并且绘制出相关性热力图。
2. 案例演示
2.1 获取数据
导入相关库,并使用如下代码进行本地数据集获取。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 获取数据集
NBA = pd.read_csv("nba_2017_nba_players_with_salary.csv")
NBA.head()
运行结果:
2.2 查看数据基本信息
先进行简单的统计学分析,查看标准差、中位数、方差等等信息。
# 看一下数据有多少 NBA.shape # 查看基本统计信息 NBA.describe()
部分运行结果:
2.3 数据分析
2.3.1 效率值相关性分析
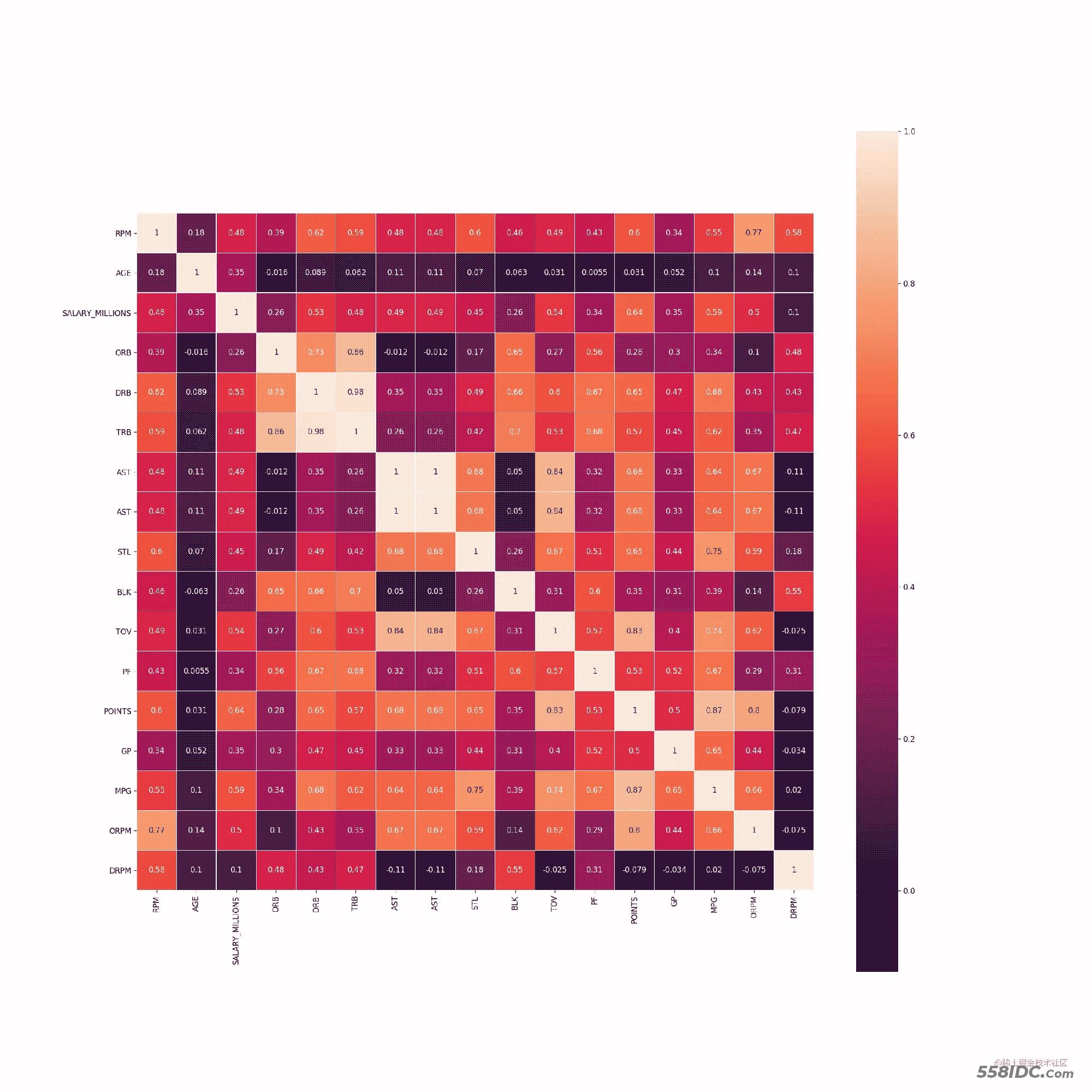
在众多数据中,有一项名为RPM,表示球员的效率值。该数据反映球员在场时对球队比赛获胜的贡献大小,最能反映球员的综合实力。我们可以看一下它与其他数据的相关性。
首先,我们取出几个有用的特征分析相关性,并绘制热力图。
# 2. 数据分析 ## 2.1 效率值相关性分析 NBA_1 = NBA.loc[:, ['RPM','AGE','SALARY_MILLIONS','ORB','DRB','TRB','AST','AST','STL','BLK','TOV','PF','POINTS','GP','MPG','ORPM','DRPM']] NBA_1.head()
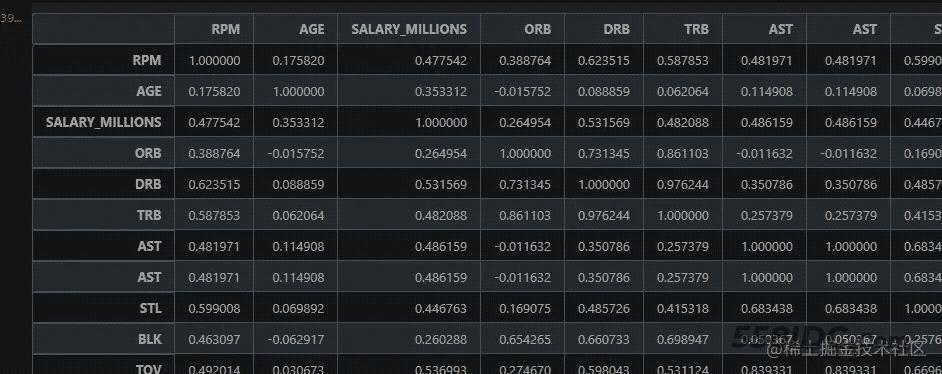
然后,使用如下代码计算出相关性表。
# 计算相关性 # 获取两列之间的相关性 corr = NBA_1.corr() corr
部分运行结果如下图所示:
最后,使用刚才的相关性表,绘制出相关性关系热力图
# 调用热力图绘制相关性关系
plt.figure(figsize=(20,20),dpi=120)
sns.heatmap(corr, square=True, linewidths=0.1, annot=True)
# 保存图像
plt.savefig("./test.png")
# 颜色越深:相关性越弱
# 颜色越浅:相关性越强
运行结果如下图所示:
以上就是Seaborn数据分析NBA球员信息数据集的详细内容,更多关于Seaborn数据分析的资料请关注自由互联其它相关文章!