目录 前言 微博功能布局 创建微博 Widget 创建微博查询 词云制作 结果展示 前言 在前面的分享中,我们制作了一个天眼查 GUI 程序,今天我们在这个的基础上,继续开发新的功能,微博
目录
- 前言
- 微博功能布局
- 创建微博 Widget
- 创建微博查询
- 词云制作
- 结果展示
前言
在前面的分享中,我们制作了一个天眼查 GUI 程序,今天我们在这个的基础上,继续开发新的功能,微博抓取工具,先来看下最终的效果
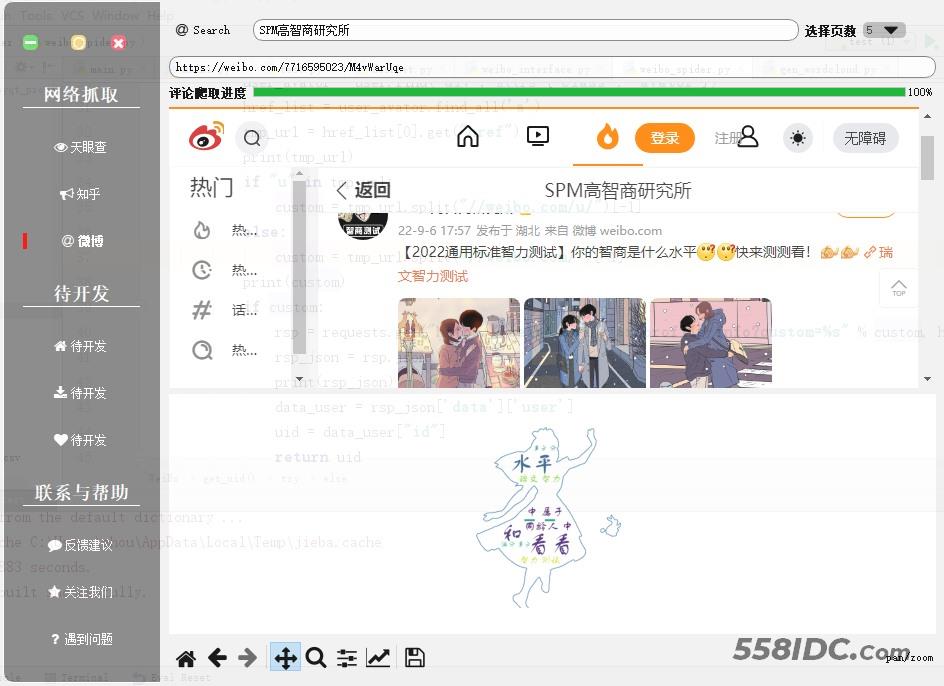
整体的界面还是继承自上次的天眼查界面,我们直接来看相关功能
微博功能布局
我们整体的界面布局就是左侧可以选择不同功能,然后右侧的界面会对应改变
创建微博 Widget
对于右侧界面的切换,我们可以为不同的功能创建不同的 Widget,当点击左侧不同功能按钮后,对应切换 Widget 即可
我们新建一个 weibo 相关的函数,主要用来界面布局
def weiboWidget(self): self.left_button_widget_3 = QtWidgets.QWidget() self.weiboWebEngine = QWebEngineView() self.weiboWebEngine2 = QWebEngineView() self.progressWidget = QtWidgets.QWidget() self.ciyunWidget = QtWidgets.QWidget()
我们还看到整体界面有一个词云,该词云是通过 matplotlib 渲染的,所以还需要创建 matplotlib 布局
# matplotlib 绘图区域 self.figure = plt.figure(figsize=(7, 2)) self.canvas = FigureCanvasQTAgg(self.figure) # 绘图区域放到图层canvas之中 self.gridLayout_weibo.addWidget(self.canvas, 5, 0, 1, 9) # 图层放到pyqt布局之中
创建微博查询
接下来我们创建一个微博查询函数,同时因为我们这里需要实时更新抓取进度条,所以使用了多线程的方式
def doWeiboQuery(self): weibo_link = self.lineEdit_weibo_link.text() weibo_name = self.lineEdit_weibo_name.text() weibo_page = self.weibo_comboBox.currentText() if not weibo_link or not weibo_name: QMessageBox.information(self, "Error", "微博链接或者用户名称不能为空", QMessageBox.Yes) return self.weiboWebEngine.load(QUrl(weibo_link)) self.qth = WeiBoQueryThread() self.qth.update_data.connect(self.weiboPgbUpdate) self.qth.draw_ciyun.connect(self.drawCiyun) self.qth.weibo_page = weibo_page self.qth.weibo_link = weibo_link self.qth.weibo_name = weibo_name self.qth.start()
而主线程与子线程之间的通信,是使用信号槽的形式
def weiboPgbUpdate(self, data): self.pgb.setValue(data) def drawCiyun(self): self.canvas.draw() self.toolbar = NavigationToolbar2QT(self.canvas, self) self.gridLayout_weibo.addWidget(self.toolbar, 8, 0, 1, 9)
接下来就是创建子进程函数,函数主体是爬取微博的代码
"""子进程微博查询"""
class WeiBoQueryThread(QThread):
# 创建一个信号,触发时传递当前时间给槽函数
update_data = pyqtSignal(int)
draw_ciyun = pyqtSignal()
weibo_name = None
weibo_link = None
weibo_page = None
total_pv = 0
timestamp = str(int(time.time()))
def run(self):
# 微博爬虫
try:
file_name = self.weibo_name + "_" + self.timestamp + 'comment.csv'
my_weibo = weibo_interface.Weibo(self.weibo_name)
uid, blog_info = my_weibo.weibo_info(self.weibo_link)
pv_max = int(self.weibo_page)
pre_pv = 100 // pv_max
for i in range(int(self.weibo_page)):
my_weibo.weibo_comment(uid, blog_info, str(i), file_name)
self.total_pv += pre_pv
self.update_data.emit(self.total_pv)
print("所有微博评论爬取完成!")
print("开始生成词云")
font, img_array, STOPWORDS, words = ciyun(file_name)
wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font, mask=img_array,
stopwords=STOPWORDS, contour_width=3, contour_color='steelblue').generate(words)
plt.imshow(wc)
plt.axis("off")
self.draw_ciyun.emit()
print("生成词云完成")
except Exception as e:
print(e)
而对于微博的具体爬取方法,这里就不再展开说明了,我是把所有微博爬虫的代码都封装好了,这里直接调用暴露的接口即可
词云制作
对于词云的制作,我们还是先通过 jieba 进行分词处理,然后使用 wordcloud 库生成词云即可
# 词云相关
def ciyun(file, without_english=True):
font = r'C:\Windows\Fonts\FZSTK.TTF'
STOPWORDS = {"回复", "@", "我", "她", "你", "他", "了", "的", "吧", "吗", "在", "啊", "不", "也", "还", "是",
"说", "都", "就", "没", "做", "人", "赵薇", "被", "不是", "现在", "什么", "这", "呢", "知道", "邓"}
df = pd.read_csv(file, usecols=[0])
df_copy = df.copy()
df_copy['comment'] = df_copy['comment'].apply(lambda x: str(x).split()) # 去掉空格
df_list = df_copy.values.tolist()
comment = jieba.cut(str(df_list), cut_all=False)
words = ' '.join(comment)
if without_english:
words = re.sub('[a-zA-Z]', '', words)
img = Image.open('ciyun.png')
img_array = np.array(img)
return font, img_array, STOPWORDS, words
由于很多评论当中会存在链接信息,导致制作的词云有很多高权重的英文字符,所有这里也通过正则进行了去英文字符处理
至此,我们这个微博查询功能就完成了~
结果展示
下面我们来看看最终的效果吧
到此这篇关于基于Python实现微博抓取GUI程序的文章就介绍到这了,更多相关Python微博抓取内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!