re.search(): 匹配整个字符串,并返回第一个成功的匹配。如果匹配失败,则返回None pattern: 匹配的规则, string : 要匹配的内容, flags 标志位 这个是可选的,就是可以不写,可以写, 比如要忽
re.search():匹配整个字符串,并返回第一个成功的匹配。如果匹配失败,则返回None

pattern: 匹配的规则,
string : 要匹配的内容,
flags 标志位 这个是可选的,就是可以不写,可以写, 比如要忽略字符的大小写就可以使用标志位
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释
示例代码:【检查字符串是否以 "Long" 开头并以 "China" 结尾】
import re
s = "Long live the people's Republic of China"
ret = re.search("^Long.*China$", s)
print(ret)
print(ret.group())
print(ret[0])
运行结果:

示例代码:【在字符串中搜索第一个空白字符】
import re
s = "Long live the people's Republic of China"
ret = re.search("\s", s)
print(ret)
print(ret.start())
运行结果:

示例代码:【如果search未匹配到,返回None】
import re
s = "Long live the people's Republic of China"
ret = re.search("USA", s)
print(ret)
运行结果:

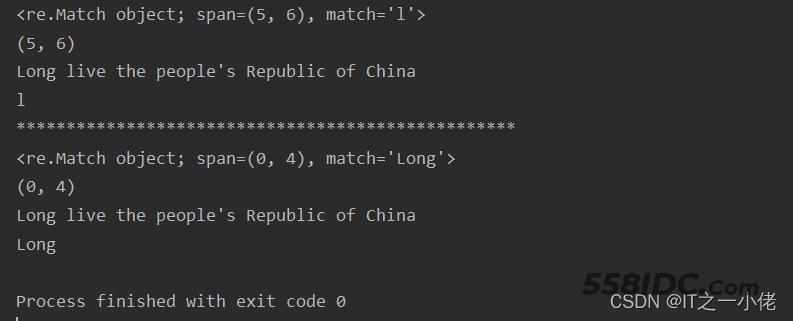
示例代码:【忽略大小写】
import re
s = "Long live the people's Republic of China"
# ret1 = re.search('long', s) 这行代码直接报错
ret1 = re.search('l', s)
print(ret1)
print(ret1.span())
print(ret1.string)
print(ret1.group())
print("*" * 50)
ret2 = re.search('long', s, re.I)
print(ret2)
print(ret2.span())
print(ret2.string)
print(ret2.group())
运行结果:
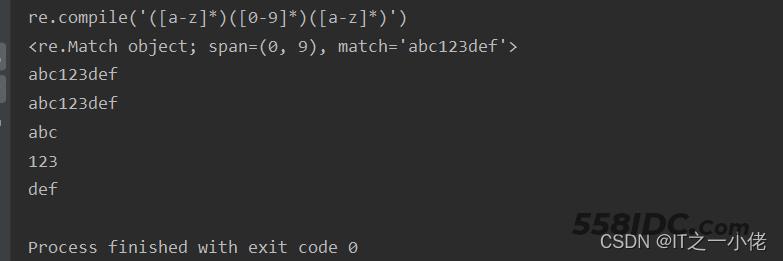
示例代码:【group()的使用】
import re
s = 'abc123def456ghi789'
ret_compile = re.compile("([a-z]*)([0-9]*)([a-z]*)")
print(ret_compile)
ret = ret_compile.search(s)
print(ret)
print(ret.group())
print(ret.group(0)) # group()和group(0) 一样匹配的是整体
print(ret.group(1)) # 匹配第1个小括号的内容
print(ret.group(2)) # 匹配第2个小括号的内容
print(ret.group(3)) # 匹配第3个小括号的内容
运行效果:
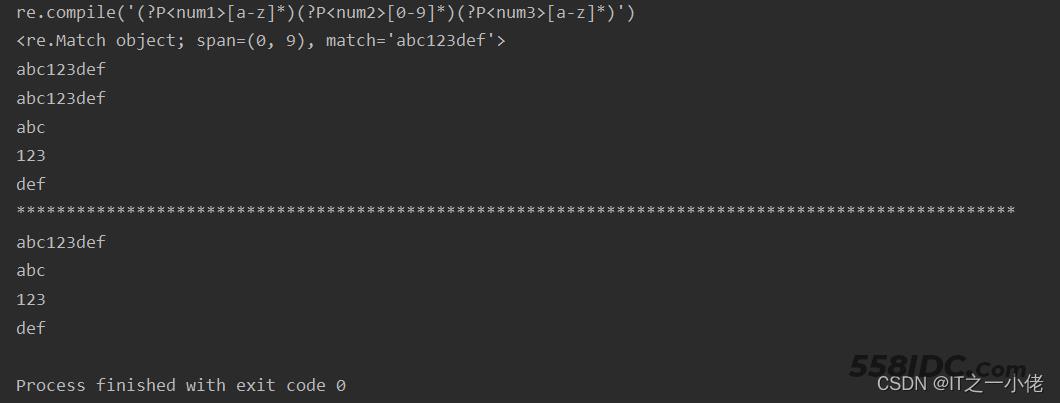
示例代码:【group()分组的使用】
import re
s = 'abc123def456ghi789'
ret_compile = re.compile("(?P<num1>[a-z]*)(?P<num2>[0-9]*)(?P<num3>[a-z]*)")
print(ret_compile)
ret = ret_compile.search(s)
print(ret)
print(ret.group())
print(ret.group(0)) # group()和group(0) 一样匹配的是整体
print(ret.group(1)) # 匹配第1个小括号的内容
print(ret.group(2)) # 匹配第2个小括号的内容
print(ret.group(3)) # 匹配第3个小括号的内容
print("*" * 100)
print(ret.group())
print(ret.group("num1")) # 这里效果等同于group(1)
print(ret.group("num2")) # 这里效果等同于group(3)
print(ret.group("num3")) # 这里效果等同于group(3)
运行效果:
总结:为匹配方便,能用search就不用match,match方法限定匹配时,头部必须是一致的
匹配演练:最后我们做些匹配演练,实战下
import re
html='''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id ="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈惠琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君"><i class="fa fa-user"></i>但愿人长久</a>
</li>
</ul>
</div>
'''
上面是html代码,要求匹配出 第3个li标签中的齐秦 往事随风 ,代码如下:
result = re.search('<li.*?active.*?singer="(.*?)">(.*?)</a>',html,re.S)#re.S确保.能匹配到换行符
if result:
print(result.group(1),result.group(2))
结果:
齐秦 往事随风
我们还要求匹配出第二个li标签中的内容 任贤齐 沧海一声笑
result = re.search('<li.*?singer="(.*?)">(.*?)</a>',html,re.S)
if result:
print(result.group(1),result.group(2))
结果:
任贤齐 沧海一声笑
如果匹配时候不需要匹配换行符,那么参数中就没必要带re.S,比如匹配第4个和第5个li标签中的歌手和歌名。但是re.search也仅仅是返回一个符合匹配的结果。如果我们要返回符合匹配的所有结果,要用到re.findall。这一节的re.search就说到这里。
总结
到此这篇关于Python正则表达式re.search()用法详解的文章就介绍到这了,更多相关Python re.search()用法内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!