首先我们需要导入random模块
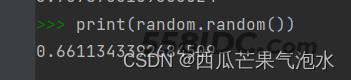
1. random.random(): 返回随机生成的一个浮点数,范围在[0,1)之间
import random print(random.random())
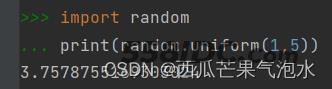
2. random.uniform(a, b): 返回随机生成的一个浮点数,范围在[a, b)之间
import random print(random.uniform(1,5))
3. random.randint(a,b):生成指定范围内的整数
import random print(random.randint(1,10))

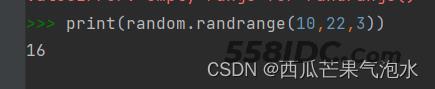
4. random.randrange([start],stop[,step]):用于从指定范围内按指定基数递增的集合中获取一个随机数。
例如random.randrange(10,100,2),结果相当于从 [10,12,14,16...96,98] 序列中获取一个随机数。random.randrange (10,100,2) 的结果上与 random.choice(range(10,100,2)) 等效。
import random print(random.randrange(10,22,3))
5. random.choice():从指定的序列中获取一个随机元素
random.choice()从序列中获取一个随机元素,其原型为random.choice(sequence),参数sequence表示一个有序类型。这里说明一下,sequence在Python中不是一种特定的类型,而是泛指序列数据结构。列表,元组,字符串都属于sequence。
import random
print(random.choice('学习python')) # 从字符串中随机取一个字符
print(random.choice(['good', 'hello', 'is', 'hi', 'boy'])) # 从list列表中随机取
print(random.choice(('str', 'tuple', 'list'))) # 从tuple元组中随机取

6. random.shuffle(x[,random]):用于将一个列表中的元素打乱,随机排序
import random p=['hehe','xixi','heihei','haha','zhizhi','lala','momo..da'] random.shuffle(p) print(p) x = [1, 2, 3, 4, 5] random.shuffle(x) print(x)

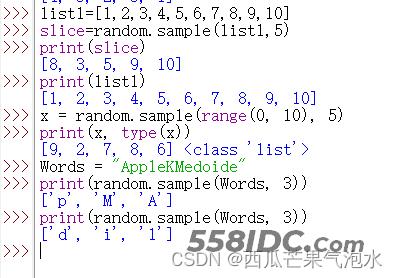
7. random.sample(sequence,k):用于从指定序列中随机获取指定长度的片段,sample()函数不会修改原有序列。
import random list1=[1,2,3,4,5,6,7,8,9,10] slice=random.sample(list1,5) print(slice) #[8, 3, 5, 9, 10] print(list1) #[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] x = random.sample(range(0, 10), 5) print(x, type(x)) #[9, 2, 7, 8, 6] <class 'list'> Words = "AppleKMedoide" print(random.sample(Words, 3)) #['p', 'M', 'A'] print(random.sample(Words, 3)) #['d', 'i', 'l']
下面的函数需要调用numpy库
8. np.random.rand(d0, d1, …, dn): 返回一个或一组浮点数,范围在[0, 1)之间
import random import numpy as np x = np.random.rand() y = np.random.rand(4) print(x,type(x)) #0.09842641570445387 <class 'float'> print(y,type(y)) #[0.27298291 0.12350038 0.63977128 0.90791234] <class 'numpy.ndarray'>
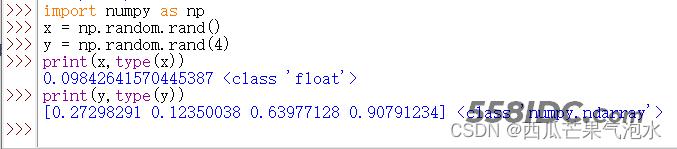
9. np.random.normal(loc=a, scale=b, size=()): 返回满足条件为均值=a, 标准差=b的正态分布(高斯分布)的概率密度随机数
np.random.normal(loc=a, scale=b, size=()) - 返回满足条件为均值=a, 标准差=b的正态分布(高斯分布)的概率密度随机数,size默认为None(返回1个随机数),也可以为int或数组
import random import numpy as np x = np.random.normal(10,0.2,2) print(x,type(x)) #[9.78391585 9.83981096] <class 'numpy.ndarray'> y = np.random.normal(10,0.2) print(y,type(y)) #9.871187751372984 <class 'float'> z = np.random.normal(0,0.1,(2,3)) print(z,type(z)) #[[-0.07114831 -0.10258022 -0.12686863] # [-0.08988384 -0.00647591 0.06990716]] <class 'numpy.ndarray'> z = np.random.normal(0,0.1,[2,2]) print(z,type(z)) #[[ 0.07178268 -0.00226728] # [ 0.06585013 -0.04385656]] <class 'numpy.ndarray'>
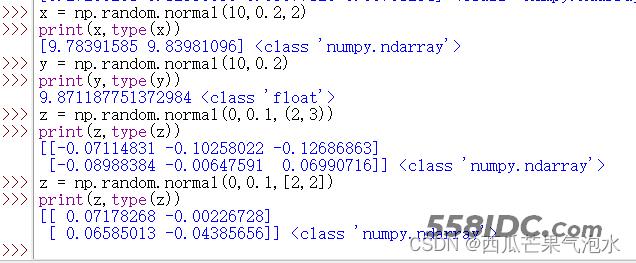
10 np.random.randn(d0, d1, … dn): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数
np.random.randn(d0, d1, ... dn): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数,
import random import numpy as np x = np.random.randn() y = np.random.randn(3) z = np.random.randn(3, 3) print(x, type(x)) print(y, type(y)) print(z, type(z))

11. np.random.standard_normal(size=()): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数
np.random.standard_normal(): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数, size默认为None(返回1个随机数),也可以为int或数组
import random import numpy as np x = np.random.standard_normal() y = np.random.standard_normal(size=(3,3)) print(x, type(x)) print(y, type(y))
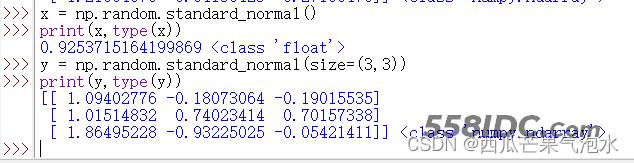
np.random.rand()与np.random.standard_normal()的方法结果相似,都是返回合符标准正态分布的随机浮点数或数组。
12. np.random.randint(a, b, size=(), dtype=int): 返回在范围在[a, b)中的随机整数(含有重复值)
np.random.randint(a, b, sizie=(), dytpe=int) - size默认为None(返回1个随机数),也可以为int或数组
import random import numpy as np # 从序列[0, 10)之间返回shape=(5,5)的10个随机整数(包含重复值) x = np.random.randint(0, 10, size=(5, 5)) # 从序列[15, 20)之间返回1个随机整数(size默认为None, 则返回1个随机整数) y = np.random.randint(15, 20) print(x, type(x)) print(y, type(y))

13. random.seed(): 设定随机种子
在设定随机种子为10之后,random.random()的随机数将被直接设定为:0.5714025946899135
import random random.seed(10) x = random.random() print(x,type(x)) random.seed(10) y = random.random() print(y,type(y)) z = random.random() print(z,type(z))

random随机数是这样生成的:我们将这套复杂的算法(是叫随机数生成器吧)看成一个黑盒,把我们准备好的种子扔进去,它会返给你两个东西,一个是你想要的随机数,另一个是保证能生成下一个随机数的新的种子,把新的种子放进黑盒,又得到一个新的随机数和一个新的种子,从此在生成随机数的路上越走越远。
我们利用如下代码进行测试:
import numpy as np
if __name__ == '__main__':
i = 0
while i < 6:
if i < 3:
np.random.seed(0)
print(np.random.randn(1, 5))
else:
print(np.random.randn(1, 5))
i += 1
i = 0
while i < 2:
print(np.random.randn(1, 5))
i += 1
print(np.random.randn(2, 5))
np.random.seed(0)
print("###################################")
i = 0
while i < 8:
print(np.random.randn(1,5))
i += 1
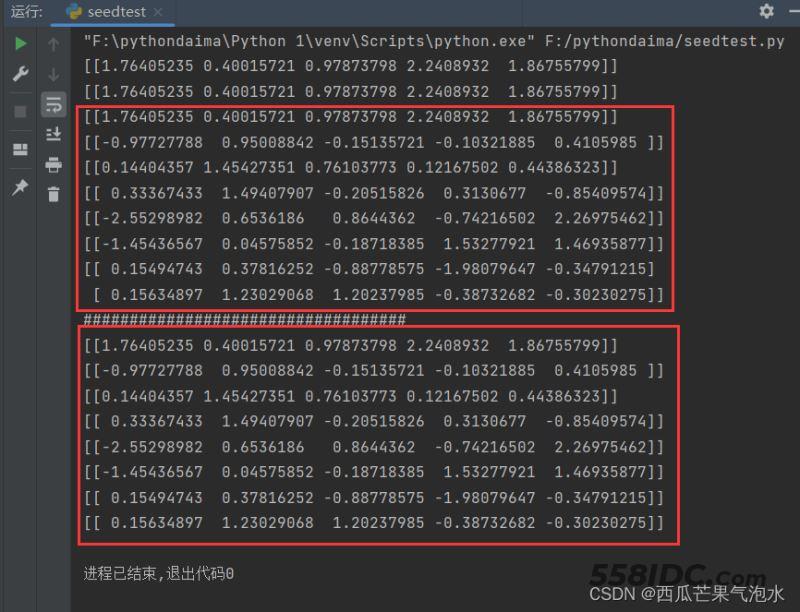
通过该实验我们可以得到以下结论:
- 两次利用随机数种子后,即便是跳出循环后,生成随机数的结果依然是相同的。第一次跳出while循环后,进入第二个while循环,得到的两个随机数组确实和加了随机数种子不一样。但是,后面的加了随机数种子的,八次循环中的结果和前面的结果是一样的。说明,随机数种子对后面的结果一直有影响。同时,加了随机数种子以后,后面的随机数组都是按一定的顺序生成的。
- 在同样的随机种子后第六次的随机数生成结果,两行五列的数组和两个一行五列的数组结果相同。说明,在生成多行随机数组时,是由单行随机数组组合而成的。
- 利用随机数种子,每次生成的随机数相同,就是使后面的随机数按一定的顺序生成。当随机数种子参数为0和1时,生成的随机数和我上面高亮的结果相同。说明该参数指定了一个随机数生成的起始位置。每个参数对应一个位置。并且在该参数确定后,其后面的随机数的生成顺序也就确定了。
- 随机数种子的参数怎么选择?我认为随意,这个参数只是确定一下随机数的起始位置。
本文综合参考了如下文章整理:
- python中的random用法
- python random函数
- python常用random随机函数汇总,用法详解及函数之间的区别
- 随机种子的理解
总结
到此这篇关于Python中random函数用法的文章就介绍到这了,更多相关Python random函数用法内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!