Unicode是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编
Unicode是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
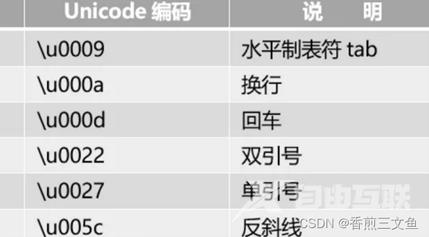
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。在 基本多文种平面里的所有字符,要用四位十六进制数;在零号平面以外的字符则需要使用五位或六位十六进制数了。
string str = @"\u0005 \u0002\U00f3 \U +e9\u00e9";
string newStr = UnicodeDecode(str);
Console.WriteLine(newStr);
Console.WriteLine();
newStr = ToUnicode("0 - * @ , 。 ? 真的 繁體字");
Console.WriteLine(newStr);
Console.WriteLine();
正常字符转换为unicode
/// <summary>
/// 对正常的字符串转换为 Unicode 的字符串
/// </summary>
/// <param name="normalStr">正常的字符串</param>
/// <param name="isIgnoreSpace">是否忽略空格符;默认 true 空格符不转换;false 空格符要转换</param>
/// <param name="isUpperCaseU">是否大写U字母 ‘\U';默认 false ‘\u'</param>
/// <returns></returns>
public string ToUnicode(this string normalStr, bool isIgnoreSpace = true, bool isUpperCaseU = false)
{
if (string.IsNullOrEmpty(normalStr))
{
return string.Empty;
}
StringBuilder strResult = new StringBuilder();
void func(int index)
{
if (isUpperCaseU)
{
strResult.Append("\\U");
}
else
{
strResult.Append("\\u");
}
strResult.Append(((int)normalStr[index]).ToString("x").PadLeft(4, '0'));
}
for (int i = 0; i < normalStr.Length; i++)
{
if (isIgnoreSpace)
{
if (normalStr[i] == ' ')
{
strResult.Append(" ");
}
else
{
func(i);
}
}
else
{
func(i);
}
}
return strResult.ToString();
}
解码
/// <summary>
/// 对 Unicode 的字符串解码
/// </summary>
/// <param name="unicodeStr">Unicode 字符串</param>
/// <returns></returns>
public string UnicodeDecode(string unicodeStr)
{
if (string.IsNullOrWhiteSpace(unicodeStr) || (!unicodeStr.Contains("\\u") && !unicodeStr.Contains("\\U")))
{
return unicodeStr;
}
string newStr = Regex.Replace(unicodeStr, @"\\[uU](.{4})", (m) =>
{
string unicode = m.Groups[1].Value;
if (int.TryParse(unicode, System.Globalization.NumberStyles.HexNumber, null, out int temp))
{
return ((char)temp).ToString();
}
else
{
return m.Groups[0].Value;
}
}, RegexOptions.Singleline);
return newStr;
}
到此这篇关于C# Unicode编码解码的实现的文章就介绍到这了,更多相关C# Unicode编码解码内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!