目录
- 前言
- 一、大小端介绍
- 1. 大端字节序与小端字节序的概念
- 2. 为什么会有大小端之分?
- 3.一道和字节序相关的例题
- 题干
- 思路
- 二、如何设计一个小程序判断当前机器的字节序
- 百度2015年系统工程师笔试题
- 题干
- 解题
前言
本文以C语言实现,主要通过例题+说明的模式讲解存储模式:大小端字节序。
对于正整数而言,它的补码 = 原码 = 反码;
对于负整数而言,它的补码 = 原码按位取反(就是反码) + 1;
例如,当语句int a = 500被执行时,内存中会开辟 4字节(即32bit)的空间存储整数20的二进制补码(00000000 00000000 0000000111110100)。同时,我们也知道,内存中的每一个存储单元的大小为 1字节(8bit)。
那么此时问题来了:int a = 500所占的总空间是4字节,然而每一个内存单元只存的下1字节的数据,换句话说,每一个整型数据需要4个存储单元才能存的下——那么,这4个存储单元在内存中到底是如何分布的呢?
是像数组一样,用来存储数据的4个内存单元彼此之间连续开辟,还是物理空间上其实并不连续、只是解析数据时把4个单元中的数据“拼”到一起,还原出连续的整型数呢?
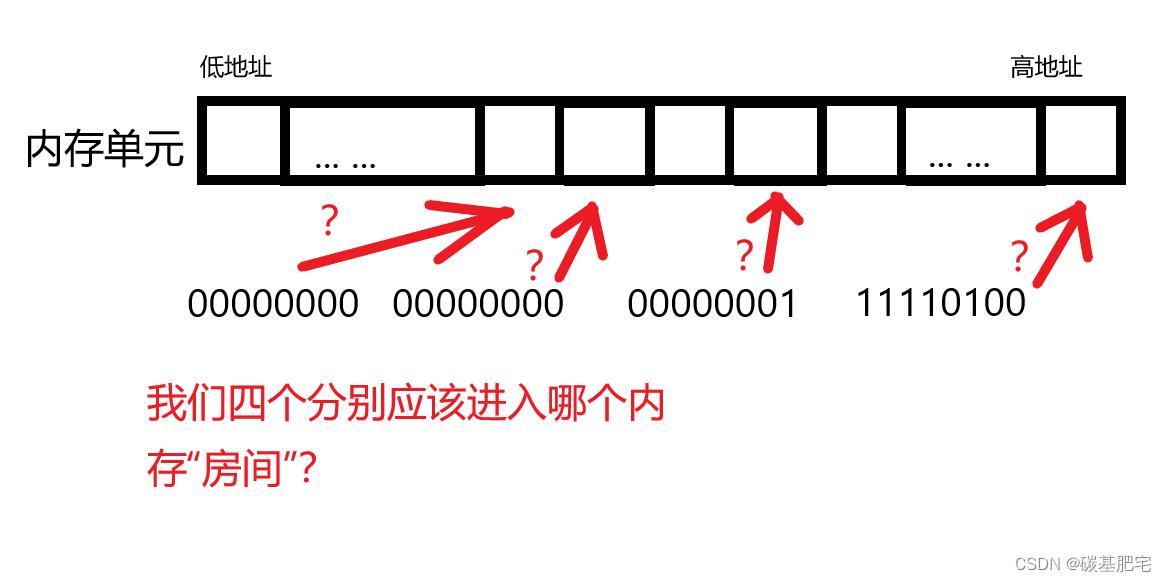
每一个字节的数据,如何“被安排”存储空间?
这个问题,本质上是数据在内存中的存储模式问题。这就关系到我们今天要介绍的重点:大端数据存储模式或小端数据存储模式(即大端字节序与小端字节序)。
我们打开编译器vs2019的内存监视,可以从监视窗口看到数值在内存中的存储情况(显示为16进制)。
注意:32位下,
20的16进制补码为:00 00 00 14
-10的十六进制补码为:ff ff ff f6
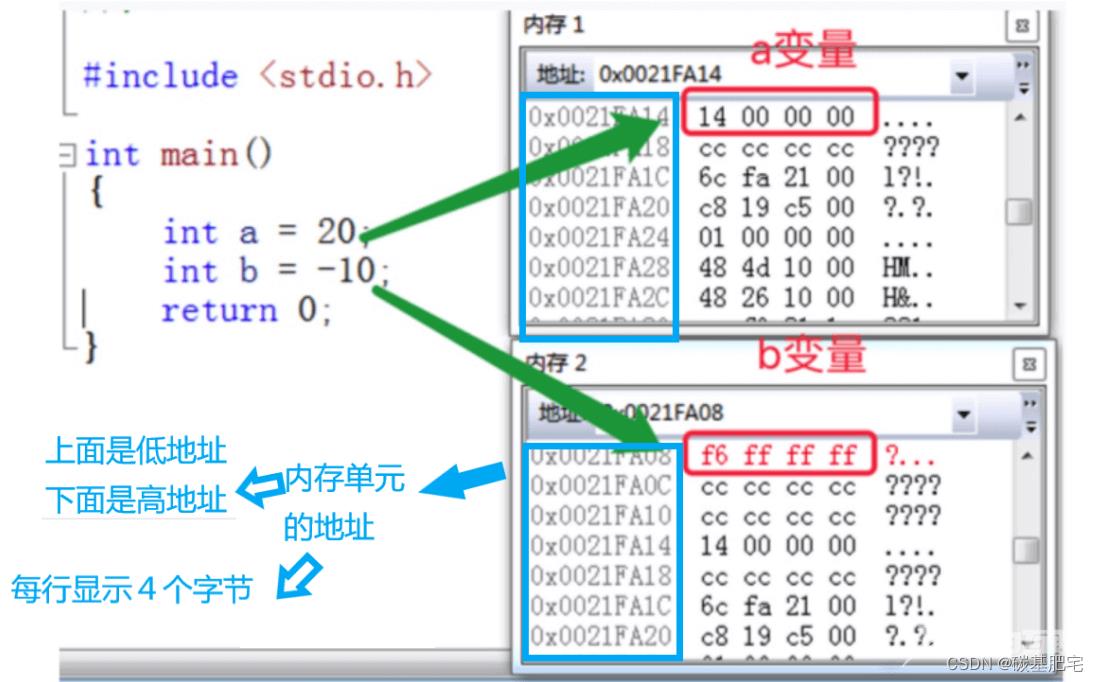
两个16进制位恰好是一个字节8bit。我们将视图调整为每行显示4个字节(即一个int,这样看得更清晰),于是可以发现,在内存中数据似乎是“倒着存”的。00 00 00 14在内存中的存储显示为了14 00 00 00.
事实上,这并不叫做“倒着存”,这正是我们上面提到过的:小端字节序的存储模式。在阅读完本文后,我们就能明白。
一、大小端介绍
当一个数值的大小超过 1字节 ,那么它要存到内存中,字节与字节之间就有存储顺序的问题。这个顺序称之为字节序。
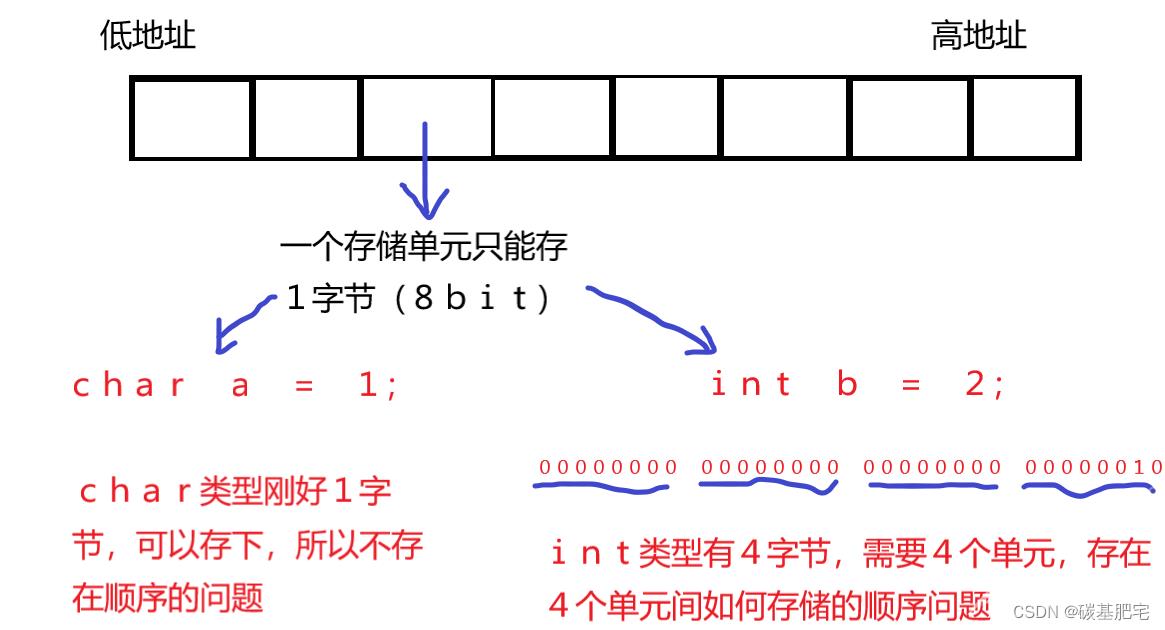
以int类型为例。
理论上来说,即使存储一个int型数据的4个存储单元不连续,甚至天南海北,只要最终解析时能还原成一个正常的数即可。但是这么做属实没有必要:计算机中存储肯定是采用最便捷的存储方式,那就是连续存储,一个整型的4个字节空间挨在一块儿。
这时要考虑的问题便是,这四个挨在一块的存储空间,是由低地址向高地址存储,还是由高地址向低地址存储?
1. 大端字节序与小端字节序的概念
小端字节序:把一个数值的低位字节内容存放在低地址处;高位字节内容存放在高地址处。(低位存低地址,高位存高地址)。
大端字节序:把一个数值的低位字节内容存放在高地址处;高位字节内容存放在低地址处。(低位存高地址,高位存低地址)。
例如,要存储一个十六进制数 0x11223344。该数中右端是低数位,左端是高数位(类比十进制数,十进制数10里面0是个位更低,1是十位更高)。
小端存储情况如下:
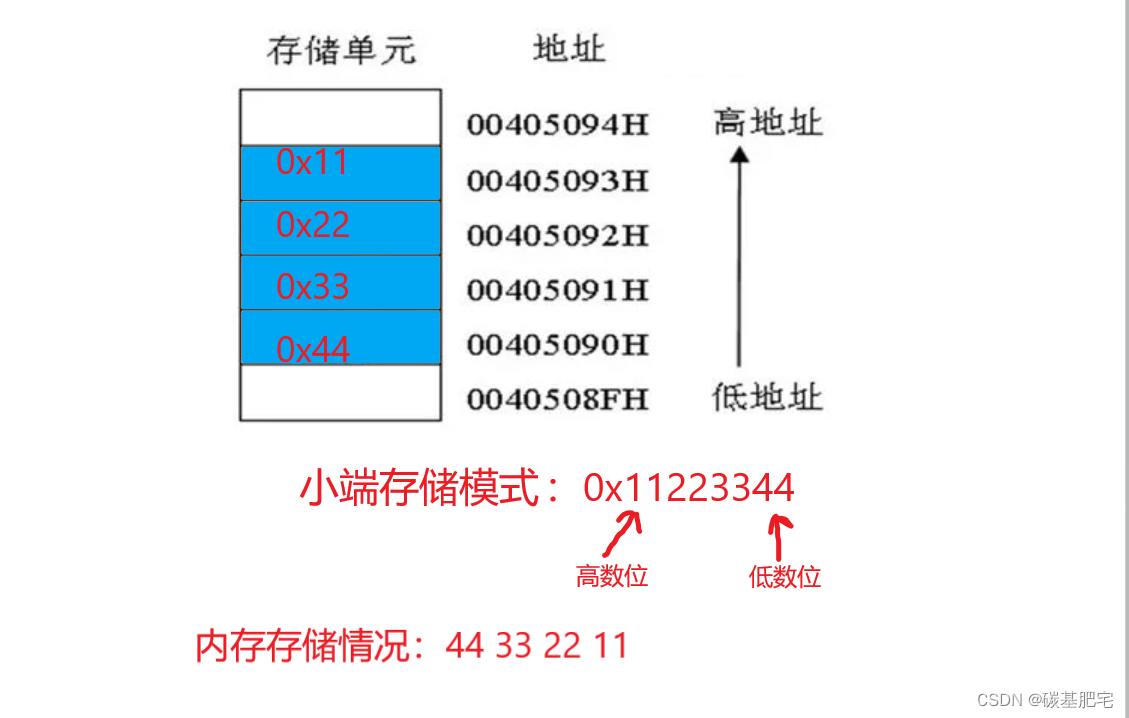
小端存储模式示意
小端存储模式下,若取出该int型数据的首地址内容会发现,存的其实是0x44。
而大端存储情况如下:
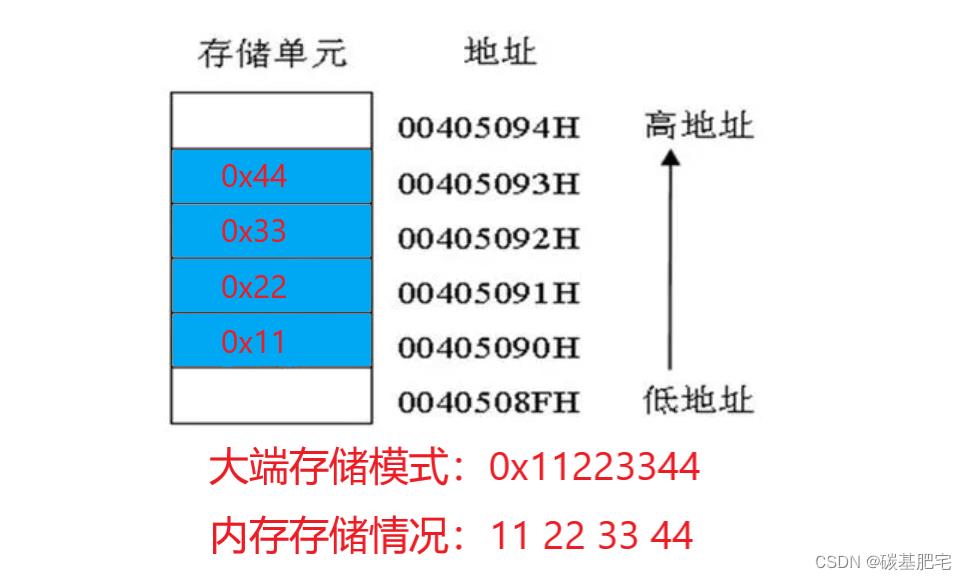
大端存储模式示意
以上就是对大小端存储模式的理解。
至于实际中如何存储的,还取决于具体编译器的选择。现在大部分的编译器选择的是小端存储模式,也就是我们上面看到的“倒着存”。
这时再参照引言中的例子,应该能对这两种存储模式有一个较好的理解了。
2. 为什么会有大小端之分?
这是因为在计算机系统中,我们以字节为单位,每个地址单元都对应着一个字节,一个字节为8 bit 。但是在 C 语言中,除了 8 bit 的 char 之外,还有 16 bit 的 short 型,32 bit 的 long 型(要看具体的编译器);另外,对于位数大于 8 位的处理器,例如 16 位或者 32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如,一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节,0x22 为低字节。
对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。 小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多ARM , DSP 都为小端模式。有些 ARM 处理器还可以由硬件来选择是大端模式还是小端模式。
3.一道和字节序相关的例题
题干
在小端机器中,下面代码输出的结果是:
#include <stdio.h>
int main()
{
int a = 0x11223344;
char *pc = (char*)&a;
*pc = 0;
printf("%x\n", a);
return 0;
}
思路
本题中的数值与我们上面讨论的数值一样,应该不难理解:
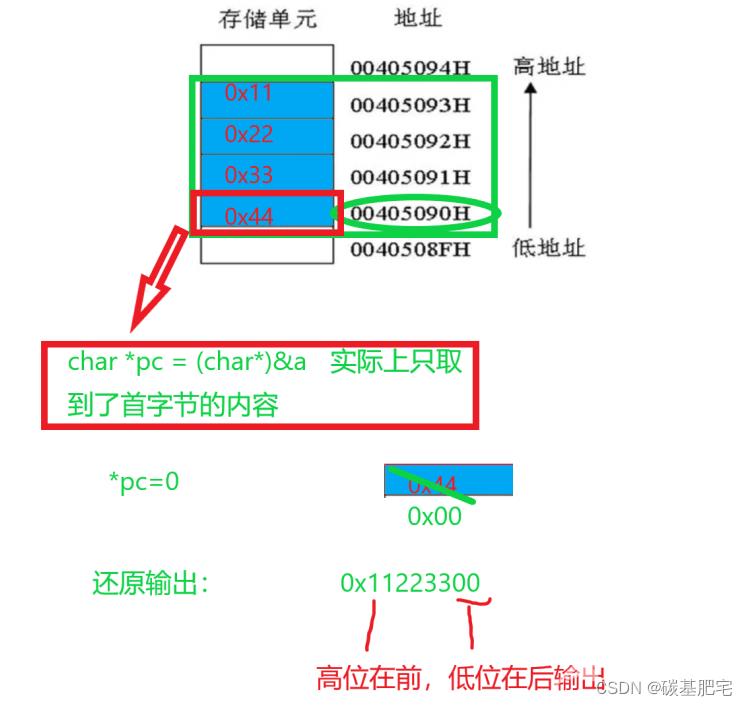
1. char*类型的指针变量pc指向的只能指向char类型的空间。如果是非char类型的空间,则必须将该空间的地址强转为char*类型。
2. char *pc = (char*)&a; pc实际指向的是整形变量a的空间,即指针pc里放的是0x00405090,指向的值即0x44。
3. *pc=0,关键一步:究竟是将哪个存储单元中的值置零了?由首个单元中存储的内容可知,将0x44位置中内容改为了0。修改完成之后,a中内容为:0x11223300 (数值书写肯定是高数位在左,低数位在右)
二、如何设计一个小程序判断当前机器的字节序
百度2015年系统工程师笔试题
题干
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。( 10 分)
解题
概念部分同上,在此不再赘述。
代码部分:
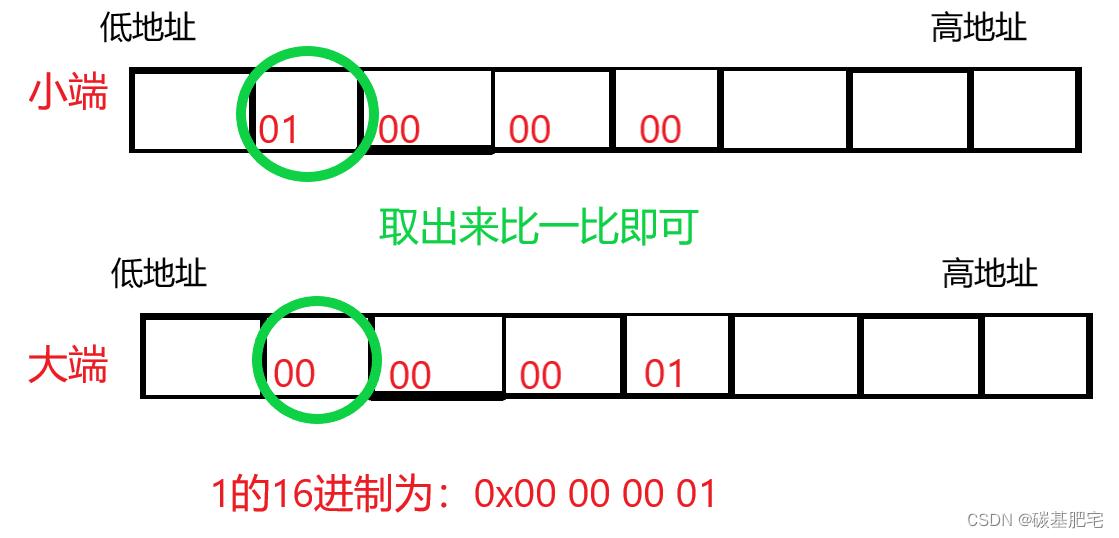
1. 要检测某一机器是大端还是小端其实并不难,我们可以直接用int类型的1来检测。
2. 1在内存中的二进制补码为:00000000000000000000000000000001
也就是说,我们只需要把首个内存单元的值取出来看看是0还是1,就能判断它是大端还是小端。
因为如果是大端,则“高数位存在低地址”,我们取出最低地址的值,应当是最高数位上的数00000000;而若是小端,则“低数位存在低地址”,依然取出最低地址的值,应当是00000001
依照该思路,有以下代码:
#include <stdio.h>
int check_sys()
{
int i = 1;
return (*(char *)&i);
}
int main()
{
int ret = check_sys();
if(ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
当然,也可以用共用体来实现检查,这是更为便捷的一种方式:
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;
}
到此这篇关于C语言大小端字节序存储模式深入解读的文章就介绍到这了,更多相关C语言大小端字节序内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!