目录 K-means算法分割 应用:分类 实例 K-means算法分割 K-means是一种经典的无监督聚类算法---不需要人工干预。 算法原理: (1)随机选择两个中心点; (2)计算每个点到这两个中心点的
目录
- K-means算法分割
- 应用:分类
- 实例
K-means算法分割
K-means是一种经典的无监督聚类算法---不需要人工干预。
算法原理:
(1)随机选择两个中心点;
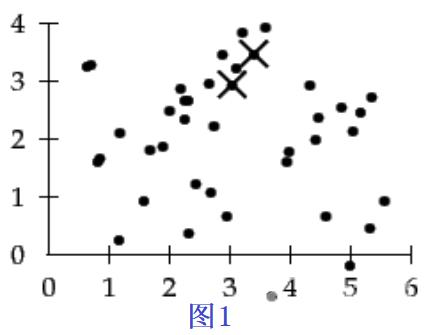
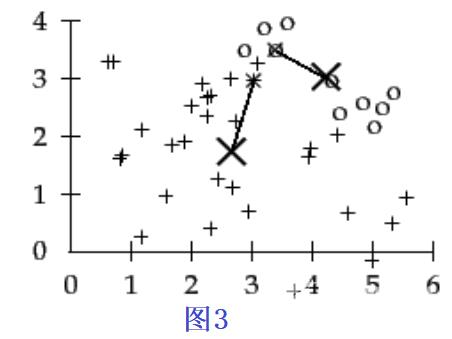
(2)计算每个点到这两个中心点的距离,最近的分成一类(连接起来);

(3)重新计算中心点(平均值计算),计算新的中心点到旧的中心点的差值如果小于输入的值,就说明中心的位置发生了变化,,那么到(2)步重新计算中心点到每个点的距离,开始下一次循环;
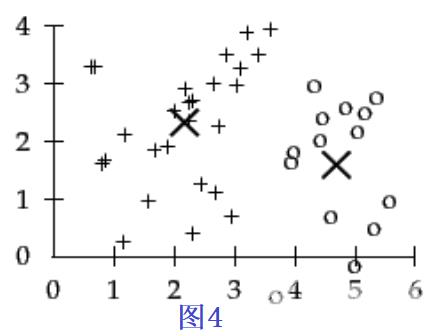
(4)执行多个迭代之后,满足收敛时,得到最终的分类
应用:分类
根据颜色分类
#include<opencv2/opencv.hpp>
#include<iostream>
int main(int argc, char** argv) {
cv::Mat img(500, 500, CV_8UC3);
cv::RNG rng(12345);
cv::Scalar colorTab[] = {
cv::Scalar(0, 0, 255),
cv::Scalar(0, 255, 0),
cv::Scalar(255, 0, 0),
cv::Scalar(0, 255, 255),
cv::Scalar(255, 0, 255)
};
int numCluster = rng.uniform(2, 5);
printf("种类数量 : %d\n", numCluster);
//4
int sampleCount = rng.uniform(2, 1000);//随机样本
printf("样本数量 : %d\n", sampleCount);
//591
cv::Mat points(sampleCount, 1, CV_32FC2);
cv::Mat labels;
cv::Mat centers;
for (int k = 0; k < numCluster; k++) {
cv::Point center;
center.x = rng.uniform(0, img.cols);//随机坐标
center.y = rng.uniform(0, img.rows);
cv::Mat pointChunk = points.rowRange(k * sampleCount / numCluster, k == numCluster - 1 ? sampleCount : (k + 1) * sampleCount / numCluster);
//每一类占1/numCluster 行
//rng.fill(pointChunk, cv::RNG::NORMAL, cv::Scalar(center.x, center.y), cv::Scalar(img.cols * 0.05, img.rows * 0.05));//用随机数填充矩阵
rng.fill(pointChunk, cv::RNG::UNIFORM, 0, 255);//用随机数填充矩阵
}
randShuffle(points, 1, &rng);//算法打乱元素排列顺序
kmeans(points, numCluster, labels, cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::COUNT, 10, 0.1), 3, cv::KMEANS_PP_CENTERS, centers);
/*【根据参数1的坐标进行分类】
参数1:为cv::Mat类型,每行代表一个样本,即特征,即mat.cols=特征长度,mat.rows=样本数,数据类型仅支持float
参数2:K 指定聚类时划分为几类
参数3:为cv::Mat类型,是一个长度为(样本数,1)的矩阵,即mat.cols=1,mat.rows=样本数;为K-Means算法的结果输出,指定每一个样本聚类到哪一个label中【指定每一个样本聚类到哪一类中】
参数4:TermCriteria类,算法进行迭代时终止的条件,可以指定最大迭代次数,也可以指定预期的精度,也可以这两种同时指定;
参数1:int type
type=TermCriteria::MAX_ITER/TermCriteria::COUNT 迭代到最大或迭代次数终止
type= TermCriteria::EPS 迭代到阈值终止
type= TermCriteria::MAX_ITER+ TermCriteria::EPS 上述两者都作为迭代终止条件
参数2:int maxCount 迭代的最大次数
参数3:double epsilon 阈值(中心位移值)
参数5:指定K-Means算法执行的次数,每次算法执行的结果是不一样的,选择最好的那次结果输出
参数6:初始化均值点的方法,目前支持三种:KMEANS_RANDOM_CENTERS、KMEANS_PP_CENTERS、KMEANS_USE_INITIAL_LABELS
参数7:为cv::Mat类型,输出最终的均值点,mat.cols=特征长度,mat.rols=K 【每个类的中心点】
*/
// 用不同颜色显示分类
//初始化图片颜色。
img = cv::Scalar::all(255);
for (int i = 0; i < sampleCount; i++) {
int index = labels.at<int>(i);
//获取ponint点
cv::Point p = points.at<cv::Point2f>(i);
//填充
circle(img, p, 2, colorTab[index], -1, 8);
}
// 每个聚类的中心来绘制圆
for (int i = 0; i < centers.rows; i++) {
int x = centers.at<float>(i, 0);
int y = centers.at<float>(i, 1);
printf("c.x= %d, c.y=%d", x, y);
circle(img, cv::Point(x, y), 40, colorTab[i], 1, cv::LINE_AA);
}
imshow("KMeans-Data-Demo", img);
cv::waitKey(0);
return 0;
}
实例
2.png

#include<opencv2/opencv.hpp>
#include<iostream>
int main(int argc, char** argv) {
cv::Scalar colorTab[] = {
cv::Scalar(0, 0, 255),
cv::Scalar(0, 255, 0),
cv::Scalar(255, 0, 0),
cv::Scalar(0, 255, 255),
};
cv::Mat src = cv::imread("D:/bb/tu1/2.png");
if (!src.data)
{
printf("图像读取失败...\n");
return -1;
}
cv::imshow("src", src);
int width = src.cols;
int height = src.rows;
int dims = src.channels();
int sampleCount = width * height; //总像素
int clusterCount = 4; //分类数量
cv::Mat points(sampleCount, dims,CV_32F,cv::Scalar(10));
//一个像素为一行
cv::Mat labels;
cv::Mat centers(clusterCount,1, points.type());
//保存中心坐标
//把RGB数据转换成样本数据
int index = 0;//像素序号
for (int row = 0; row < height;row++) {
for (int col = 0; col < width;col++) {
index = row * width + col;
cv::Vec3b bgr = src.at<cv::Vec3b>(row, col);
points.at<float>(index, 0) = static_cast<int>(bgr[0]);
points.at<float>(index, 1) = static_cast<int>(bgr[1]);
points.at<float>(index, 2) = static_cast<int>(bgr[2]);
}
}
cv::TermCriteria criteria = cv::TermCriteria(cv::TermCriteria::COUNT + cv::TermCriteria::EPS,10,0.1);
//kmeans的终止的条件
kmeans(points, clusterCount, labels, criteria, 3, cv::KMEANS_PP_CENTERS, centers);//运行kmeans
//显示图像分割结果
cv::Mat result = cv::Mat::zeros(src.size(),src.type());
for (int row = 0; row < height;row++) {
for (int col = 0; col < width;col++) {
index = row * width + col;
int label = labels.at<int>(index, 0); //获取类序号
result.at<cv::Vec3b>(row, col)[0] = colorTab[label][0];
result.at<cv::Vec3b>(row, col)[1] = colorTab[label][1];
result.at<cv::Vec3b>(row, col)[2] = colorTab[label][2];
}
}
cv::imshow("result", result);
cv::waitKey(0);
return 0;
}

以上就是OpenCV利用K-means实现根据颜色进行图像分割的详细内容,更多关于OpenCV K-means图像分割的资料请关注自由互联其它相关文章!