目录
- 示例代码
- 一.flowOn方法
- 1.ChannelFlowOperatorImpl类
- 二.collect方法
- 1.ChannelFlowOperator类的collect方法
- 2.ChannelFlow类的collect方法
- 3.flow方法中代码的执行
- 4.接收flow方法发出的值
- 三.flowOn方法与流的融合
- 四.总结
示例代码
本文分析示例代码如下:
launch(Dispatchers.Main) {
flow {
emit(1)
emit(2)
}.flowOn(Dispatchers.IO).collect {
delay(1000)
withContext(Dispatchers.IO) {
Log.d("liduo", "$it")
}
Log.d("liduo", "$it")
}
}
一.flowOn方法
flowOn方法用于将上游的流切换到指定协程上下文的调度器中执行,同时不会把协程上下文暴露给下游的流,即flowOn方法中协程上下文的调度器不会对下游的流生效。如下面这段代码所示:
launch(Dispatchers.Main) {
flow {
emit(2) // 执行在IO线程池
}.flowOn(Dispatchers.IO).map {
it + 1 // 执行在Default线程池
}.flowOn(Dispatchers.Default).collect {
Log.d("liduo", "$it") //执行在主线程
}
}
接下来,分析一下flowOn方法,代码如下:
public fun <T> Flow<T>.flowOn(context: CoroutineContext): Flow<T> {
// 检查当前协程没有执行结束
checkFlowContext(context)
return when {
// 为空,则返回自身
context == EmptyCoroutineContext -> this
// 如果是可融合的Flow,则尝试融合操作,获取新的流
this is FusibleFlow -> fuse(context = context)
// 其他情况,包装成可融合的Flow
else -> ChannelFlowOperatorImpl(this, context = context)
}
}
// 确保Job不为空
private fun checkFlowContext(context: CoroutineContext) {
require(context[Job] == null) {
"Flow context cannot contain job in it. Had $context"
}
}
在flowOn方法中,首先会检查方法所在的协程是否执行结束。如果没有结束,则会执行判断语句,这里flowOn方法传入的上下文不是空上下文,且通过flow方法构建出的Flow对象也不是FusibleFlow类型的对象,因此这里会走到else分支,将上游flow方法创建的Flow对象和上下文包装成ChannelFlowOperatorImpl类型的对象。
1.ChannelFlowOperatorImpl类
ChannelFlowOperatorImpl类继承自ChannelFlowOperator类,用于将上游的流包装成一个ChannelFlow对象,它的继承关系如下图所示:
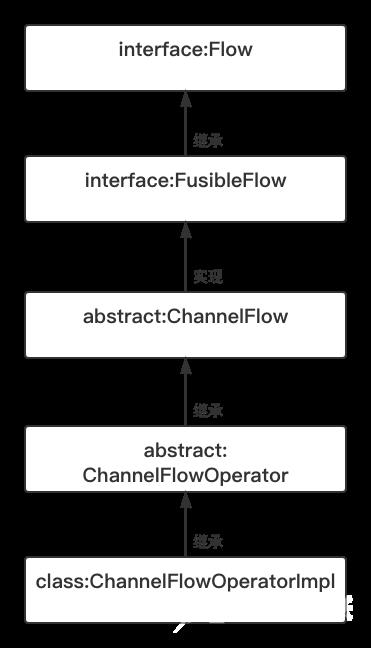
通过上图可以知道,ChannelFlowOperatorImpl类最终继承了ChannelFlow类,代码如下:
internal class ChannelFlowOperatorImpl<T>(
flow: Flow<T>,
context: CoroutineContext = EmptyCoroutineContext,
capacity: Int = Channel.OPTIONAL_CHANNEL,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
) : ChannelFlowOperator<T, T>(flow, context, capacity, onBufferOverflow) {
// 用于流融合时创建新的流
override fun create(context: CoroutineContext, capacity: Int, onBufferOverflow: BufferOverflow): ChannelFlow<T> =
ChannelFlowOperatorImpl(flow, context, capacity, onBufferOverflow)
// 若当前的流不需要通过Channel即可实现正常工作时,会调用此方法
override fun dropChannelOperators(): Flow<T>? = flow
// 触发对下一级流进行收集
override suspend fun flowCollect(collector: FlowCollector<T>) =
flow.collect(collector)
}
二.collect方法
在Kotlin协程:Flow基础原理中讲到,当执行collect方法时,内部会调用最后产生的Flow对象的collect方法,代码如下:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit = collect(object : FlowCollector<T> {<!--{C}%3C!%2D%2D%20%2D%2D%3E--> override suspend fun emit(value: T) = action(value) })public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T> {
override suspend fun emit(value: T) = action(value)
})
这个最后产生的Flow对象就是ChannelFlowOperatorImpl类对象。
1.ChannelFlowOperator类的collect方法
ChannelFlowOperatorImpl类没有重写collect方法,因此调用的是它的父类ChannelFlowOperator类的collect方法,代码如下:
override suspend fun collect(collector: FlowCollector<T>) {
// OPTIONAL_CHANNEL为默认值,这里满足条件,之后会详细讲解
if (capacity == Channel.OPTIONAL_CHANNEL) {
// 获取当前协程的上下文
val collectContext = coroutineContext
// 计算新的上下文
val newContext = collectContext + context
// 如果前后上下文没有发生变化
if (newContext == collectContext)
// 直接触发对下一级流的收集
return flowCollect(collector)
// 如果上下文发生变化,但不需要切换线程
if (newContext[ContinuationInterceptor] == collectContext[ContinuationInterceptor])
// 切换协程上下文,调用flowCollect方法触发下一级流的收集
return collectWithContextUndispatched(collector, newContext)
}
// 调用父类的collect方法
super.collect(collector)
}
// 获取当前协程的上下文,该方法会被编译器处理
@SinceKotlin("1.3")
@Suppress("WRONG_MODIFIER_TARGET")
@InlineOnly
public suspend inline val coroutineContext: CoroutineContext
get() {
throw NotImplementedError("Implemented as intrinsic")
}
ChannelFlowOperator类的collect方法在设计上与协程的withContext方法设计思路是一致的:在方法内根据上下文的不同情况进行判断,在必要时才会切换线程去执行任务。
通过flowOn方法创建的ChannelFlowOperatorImpl类对象,参数capacity为默认值OPTIONAL_CHANNEL。因此代码在执行时会进入到判断中,但因为我们指定了上下文为Dispatchers.IO,因此上下文发生了变化,同时拦截器也发生了变化,所以最后会调用ChannelFlowOperator类的父类的collect方法,也就是ChannelFlow类的collect方法。
2.ChannelFlow类的collect方法
ChannelFlow类的代码如下:
override suspend fun collect(collector: FlowCollector<T>): Unit =
coroutineScope {
collector.emitAll(produceImpl(this))
}
在ChannelFlow类的collect方法中,首先通过coroutineScope方法创建了一个作用域协程,接着调用了produceImpl方法,代码如下:
public open fun produceImpl(scope: CoroutineScope): ReceiveChannel<T> =
scope.produce(context, produceCapacity, onBufferOverflow, start = CoroutineStart.ATOMIC, block = collectToFun)
produceImpl方法内部调用了produce方法,并且传入了待执行的任务collectToFun。
produce方法在Kotlin协程:协程的基础与使用中曾提到过,它是官方提供的启动协程的四个方法之一,另外三个方法为launch方法、async方法、actor方法。代码如下:
internal fun <E> CoroutineScope.produce(
context: CoroutineContext = EmptyCoroutineContext,
capacity: Int = 0,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND,
start: CoroutineStart = CoroutineStart.DEFAULT,
onCompletion: CompletionHandler? = null,
@BuilderInference block: suspend ProducerScope<E>.() -> Unit
): ReceiveChannel<E> {
// 根据容量与溢出策略创建Channel对象
val channel = Channel<E>(capacity, onBufferOverflow)
// 计算新的上下文
val newContext = newCoroutineContext(context)
// 创建协程
val coroutine = ProducerCoroutine(newContext, channel)
// 监听完成事件
if (onCompletion != null) coroutine.invokeOnCompletion(handler = onCompletion)
// 启动协程
coroutine.start(start, coroutine, block)
return coroutine
}
在produce方法内部,首先创建了一个Channel类型的对象,接着创建了类型为ProducerCoroutine的协程,并且传入Channel对象作为参数。最后,produce方法返回了一个ReceiveChannel接口指向的对象,当协程执行完毕后,会通过Channel对象将结果通过send方法发送出来。
至此,可以知道flowOn方法的实现实际上是利用了协程拦截器的拦截功能。
在这里之后,代码逻辑分成了两部分,一部分是block在ProducerCoroutine协程中的执行,另一部分是通过ReceiveChannel对象获取执行的结果。
3.flow方法中代码的执行
在produceImpl方法中,调用了produce方法,并且传入了collectToFun对象,这个对象将会在produce方法创建的协程中执行,代码如下:
internal val collectToFun: suspend (ProducerScope<T>) -> Unit
get() = { collectTo(it) }
当调用collectToFun对象的invoke方法时,会触发collectTo方法的执行,该方法在ChannelFlowOperator类中被重写,代码如下:
protected override suspend fun collectTo(scope: ProducerScope<T>) =
flowCollect(SendingCollector(scope))
在collectTo方法中,首先将参数scope封装成SendingCollector类型的对象,接着调用了flowCollect方法,该方法在ChannelFlowOperatorImpl类中被重写,代码如下:
override suspend fun flowCollect(collector: FlowCollector<T>) =
flow.collect(collector)
ChannelFlowOperatorImpl类的flowCollect方法内部调用了flow对象的collect方法,这个flow对象就是最初通过flow方法构建的对象。根据Kotlin协程:Flow基础原理的分析,这个flow对象类型为SafeFlow,最后会通过collectSafely方法,触发flow方法中的block执行。代码如下:
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
// 触发执行
collector.block()
}
}
当flow方法在执行过程中需要向下游发出值时,会调用emit方法。根据上面flowCollect方法和collectTo方法可以知道,collectSafely方法的collector对象就是collectTo方法中创建的SendingCollector类型的对象,代码如下:
@InternalCoroutinesApi
public class SendingCollector<T>(
private val channel: SendChannel<T>
) : FlowCollector<T> {
// 通过Channel类对象发送值
override suspend fun emit(value: T): Unit = channel.send(value)
}
当调用SendingCollector类型的对象的emit方法时,会通过调用类型为Channel的对象的send方法,将值发送出去。
接下来,将分析下游如何接收上游发出的值。
4.接收flow方法发出的值
回到ChannelFlow类的collect方法,之前提到collect方法中调用produceImpl方法,开启了一个新的协程去执行任务,并且返回了一个ReceiveChannel接口指向的对象。代码如下:
override suspend fun collect(collector: FlowCollector<T>): Unit =
coroutineScope {
collector.emitAll(produceImpl(this))
}
在调用完produceImpl方法后,接着调用了emitAll方法,将ReceiveChannel接口指向的对象作为emitAll方法的参数,代码如下:
public suspend fun <T> FlowCollector<T>.emitAll(channel: ReceiveChannel<T>): Unit =
emitAllImpl(channel, consume = true)
emitAll方法是FlowCollector接口的扩展方法,内部调用了emitAllImpl方法对参数channel进行封装,代码如下:
private suspend fun <T> FlowCollector<T>.emitAllImpl(channel: ReceiveChannel<T>, consume: Boolean) {
// 用于保存异常
var cause: Throwable? = null
try {
// 死循环
while (true) {
// 挂起,等待接收Channel结果或Channel关闭
val result = run { channel.receiveOrClosed() }
// 如果Channel关闭了
if (result.isClosed) {
// 如果有异常,则抛出
result.closeCause?.let { throw it }
// 没有异常,则跳出循环
break
}
// 获取并发送值
emit(result.value)
}
} catch (e: Throwable) {
// 捕获到异常时抛出
cause = e
throw e
} finally {
// 执行结束关闭Channel
if (consume) channel.cancelConsumed(cause)
}
}
emitAllImpl方法是FlowCollector接口的扩展方法,而这里的FlowCollector接口指向的对象,就是collect方法中创建的匿名对象,代码如下:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T> {
override suspend fun emit(value: T) = action(value)
})
在emitAllImpl方法中,当通过receiveOrClosed方法获取到上游发出的值时,会调用emit方法通知下游,这时就会触发collect方法中block的执行,最终实现值从流的上游传递到了下游。
三.flowOn方法与流的融合
假设对一个流连续调用两次flowOn方法,那么流最终会在哪个flowOn方法指定的调度器中执行呢?代码如下:
launch(Dispatchers.Main) {
flow {
emit(2)
// emit方法是在IO线程执行还是在主线程执行呢?
}.flowOn(Dispatchers.IO).flowOn(Dispatchers.Main).collect {
Log.d("liduo", "$it")
}
}
答案是在IO线程执行,为什么呢?
根据本篇上面的分析,当第一次调用flowOn方法时,上游的流会被包裹成ChannelFlowOperatorImpl对象,代码如下:
public fun <T> Flow<T>.flowOn(context: CoroutineContext): Flow<T> {
// 检查当前协程没有执行结束
checkFlowContext(context)
return when {
// 为空,则返回自身
context == EmptyCoroutineContext -> this
// 如果是可融合的Flow,则尝试融合操作,获取新的流
this is FusibleFlow -> fuse(context = context)
// 其他情况,包装成可融合的Flow
else -> ChannelFlowOperatorImpl(this, context = context)
}
}
而当第二次调用flowOn方法时,由于此时上游的流——ChannelFlowOperatorImpl类型的对象,实现了FusibleFlow接口,因此,这里会触发流的融合,直接调用上游的流的fuse方法,并传入新的上下文。这里容量和溢出策略均为默认值。
根据Kotlin协程:Flow的融合、Channel容量、溢出策略的分析,这里会调用ChannelFlow类的fuse方法。相关代码如下:
public override fun fuse(context: CoroutineContext, capacity: Int, onBufferOverflow: BufferOverflow): Flow<T> {
...
// 计算融合后流的上下文
// context为下游的上下文,this.context为上游的上下文
val newContext = context + this.context
...
}
再根据之前在Kotlin协程:协程上下文与上下文元素中的分析,当两个上下文进行相加时,后一个上下文中的拦截器会覆盖前一个上下文中的拦截器。在上面的代码中,后一个上下文为上游的流的上下文,因此会优先使用上游的拦截器。代码如下:
public operator fun plus(other: CoroutineDispatcher): CoroutineDispatcher = other
四.总结
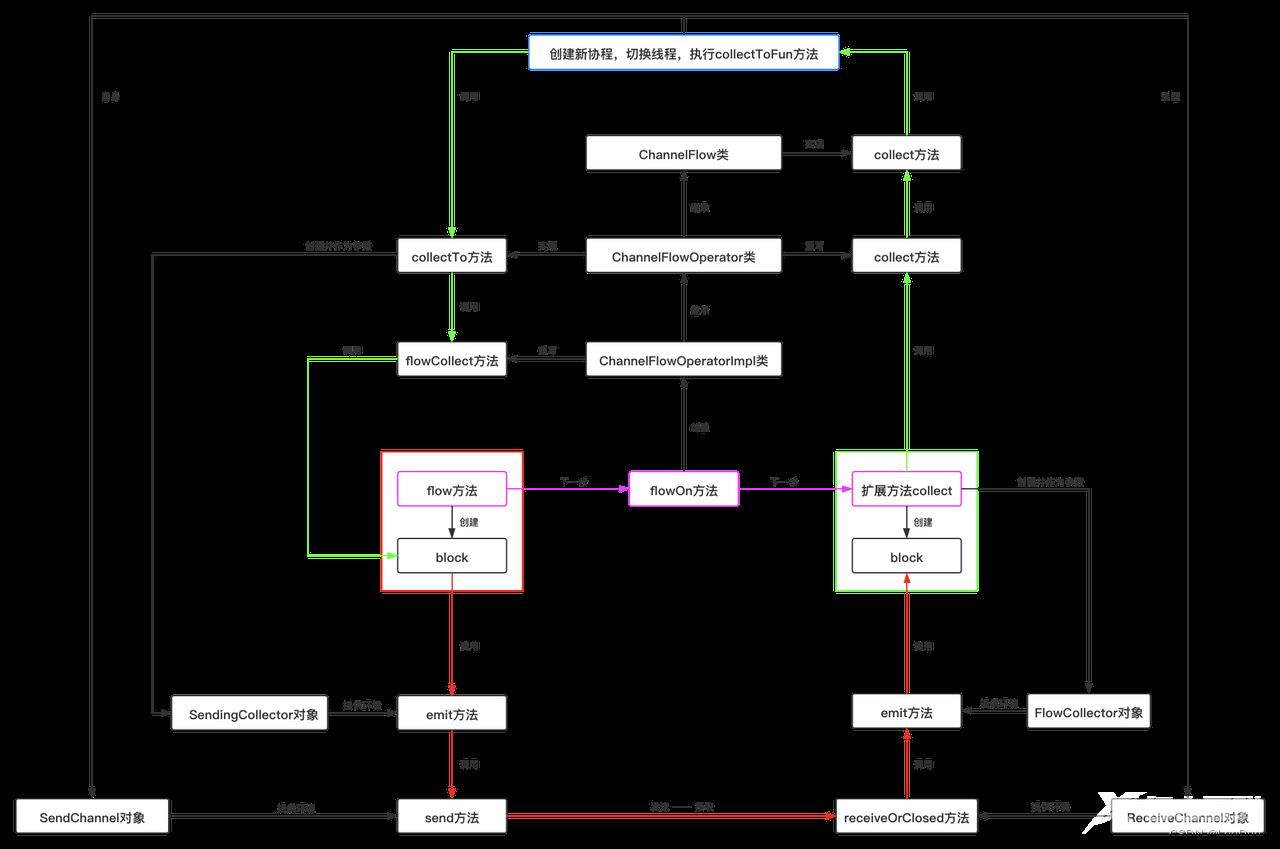
粉线为使用时代码编写顺序,绿线为下游触发上游的调用顺序,红线为上游向下游发送值的调用顺序,蓝线为线程切换的位置。
到此这篇关于Kotlin协程flowOn与线程切换超详细示例介绍的文章就介绍到这了,更多相关Kotlin flowOn与线程切换内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!