目录
- 前言
- 工具
- 模板
- 说明
- 测试
前言
“Algorithm+Data Structures=Programs”——瑞士计算机科学家尼古拉斯·沃斯
工具
C/C++库函数中的time.h/ctime库中的clock()函数
模板
#include<iostream>
#include<ctime>
using namespace std;
clock_t start_time = clock();
{ 算 法 代 码 块 };
clock_t end_time = clock();
cout<<(double)(end_time - start_time) / CLOCKS_PER_SEC<<"秒";
说明
clock()函数返回类型为clock_t(实际上是long类型),它返回从开启某个程序进程到再次调用clock()函数之间的CPU时钟计时单元(时钟周期)。
CLOCKS_PER_SEC是标准库中所定义的宏,表示每1秒CPU时钟计时单元(时钟周期)的个数
end_time - start_time 表示该程序执行期间CPU时钟计时单元(时钟周期)的总个数,除以每秒钟CPU时钟计时单元(时钟周期),即可得到程序实际运行时间,返回的单位是毫秒。
测试
分别测试选择排序算法和C++中的sort()函数的算法性能,测试数据由随机数生成。
#include<iostream>
#include<algorithm>
#include<ctime>
using namespace std;
//选择排序
void SelectSort(int a[],int n){
for(int i=0;i<n;i++){
int min_index=i;
for(int j=i+1;j<n;j++)
if(a[j]<a[min_index])
min_index=j;
swap(a[i],a[min_index]);
}
}
//随机数组
int* RandomArray(int n,int rangeL,int rangeR){
int *arr=new int[n];//创建一个大小为n的数组
srand(time(NULL));//以时间为"种子"产生随机数
for(int i=0;i<n;i++){
arr[i]=rand()%(rangeR-rangeL+1)+rangeL;//生成指定区间[rangeL,rangeR]里的数
}
return arr;
}
int main(){
int n;
cout<<"请输入数据规模n: ";cin>>n;
int *arr1,*arr2;
arr1=RandomArray(n,0,10000);
arr2=arr1;
clock_t start_time1=clock();
SelectSort(arr1,n);//选择排序算法
clock_t end_time1=clock();
cout<<"选择排序耗时:"<<(double)(end_time1-start_time1)/CLOCKS_PER_SEC<<"秒"<<endl;
clock_t start_time2=clock();
sort(arr2,arr2+n);//C++中sort()排序函数,底层为优化的快速排序算法
clock_t end_time2=clock();
cout<<"优化快排耗时:"<<(double)(end_time2-start_time2)/CLOCKS_PER_SEC<<"秒"<<endl;
return 0;
}
测试结果
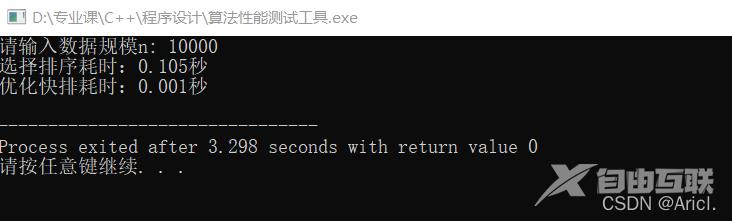
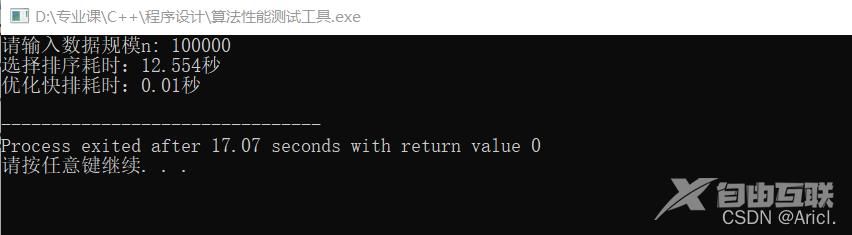
测试结果分析
通过对比可知,在数据规模相同的情况下,C++sort()排序算法的性能远远远远优于选择排序。
我们能从数据上直观的看到数据规模的增长所带来的运行时间的加长,数据规模由10000变为100000,扩大了10倍,那么根据时间复杂度的分析,选择排序的算法时间会扩大100倍左右,而sort()排序函数则会扩大10倍左右,由测试结果看出,确实如此。
因为选择排序算法的时间复杂度为O(n^2),而C++sort()排序函数的底层实现原理是快速排序算法,而且是优化的快速排序,系统会根据数据形式和数据量自动选择合适的排序方法。它每次排序中不只选择一种方法,比如给一个数据量较大的数组排序,开始采用快速排序,分段递归,分段之后每一段的数据量达到一个较小值后它就不继续往下递归,而是选择插入排序,如果递归的太深,他则会选择堆排序,时间复杂度为O(nlogn)。可见C++中sort()排序算法性能之强悍!(呐喊)
到此这篇关于C++用函数对算法性能进行测试的文章就介绍到这了,更多相关C++性能测试内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!