部署Kafka #官方文档http://kafka.apache.org/quickstart 1、环境准备 #在三个节点提前部署jdk和zookeeper[root@node1 ~]#java -versionopenjdk version "1.8.0_342"[root@node1 ~]#zkServer.sh version/usr/bin/javaZooKeeper JMX enab
部署Kafka
#官方文档http://kafka.apache.org/quickstart1、环境准备
#在三个节点提前部署jdk和zookeeper[root@node1 ~]#java -versionopenjdk version "1.8.0_342"[root@node1 ~]#zkServer.sh version/usr/bin/javaZooKeeper JMX enabled by defaultUsing config: /usr/local/zookeeper/bin/../conf/zoo.cfgApache ZooKeeper, version 3.7.1 2022-05-07 06:45 UTC#确保三个节点的zookeeper启动[root@node1 ~]#systemctl start zookeeper[root@node1 ~]#systemctl status zookeeper.service2、下载kafka解压
官网:http://kafka.apache.org/downloads清华源:https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/#所有节点[root@node1 ~]#tar xf kafka_2.13-3.0.0.tgz -C /usr/local[root@node1 ~]#cd /usr/local[root@node1 local]#ln -sv kafka_2.13-3.0.0 kafka[root@node1 local]#echo 'PATH=/bin/local/kafka/bin:$PATH' > /etc/profile.d/kafka.sh[root@node1 local]#. /etc/profile.d/kafka.sh3、修改配置文件
#第一个节点:[root@node1 local]#vim /usr/local/kafka/config/server.properties broker.id=1 # 每个broker在集群中每个节点的正整数唯一标识,此值保存在log.dirs下的meta.properties文件listeners=PLAINTEXT://10.0.0.101:9092 # 指定当前主机的IP做为监听地址,注意:不支持0.0.0.0log.dirs=/usr/local/kafka/data # kakfa用于保存数据的目录,所有的消息都会存储在该目录当中num.partitions=3 # 设置创建新的topic时默认分区数量,建议和kafka的节点数量一致log.retention.hours=168 # 设置kafka中消息保留时间,默认为168小时即7天zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 # 指定连接的zk的地址,zk中存储了broker的元数据信息zookeeper.connection.timeout.ms=6000 # 设置连接zookeeper的超时时间,单位为ms[root@node1 local]#mkdir /usr/local/kafka/data #数据目录[root@node1 local]#scp /usr/local/kafka/config/server.properties 10.0.0.102:/usr/local/kafka/config/server.properties [root@node1 local]#scp /usr/local/kafka/config/server.properties 10.0.0.103:/usr/local/kafka/config/server.properties=============================================================================#@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 其他配置说明 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@num.network.threads=3 # 处理网络请求的线程数量,默认为3个num.io.threads=8 # 执行磁盘IO操作的线程数量,默认为8个socket.send.buffer.bytes=102400 # socket服务发送数据的缓冲区大小,默认100KBsocket.receive.buffer.bytes=102400 # socket服务接受数据的缓冲区大小,默认100KBsocket.request.max.bytes=104857600 # socket服务所能接受的一个请求的最大大小,默认为100Mdefault.replication.factor=3 # 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。num.recovery.threads.per.data.dir=1 # 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量log.flush.interval.messages=10000 # 消息刷新到磁盘中的消息条数阈值log.flush.interval.ms=1000 # 消息刷新到磁盘中的最大时间间隔,1slog.retention.bytes=1073741824 # 日志保留大小,超出大小会自动删除,默认为1Glog.segment.bytes=1073741824 # 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件log.retention.check.interval.ms=300000 # 每隔多长时间检测数据是否达到删除条件,300s#第二个节点:[root@node2 local]#vim /usr/local/kafka/config/server.propertiesbroker.id=2listeners=PLAINTEXT://10.0.0.102:9092#第三个节点:[root@node3 local]#vim /usr/local/kafka/config/server.propertiesbroker.id=3listeners=PLAINTEXT://10.0.0.103:90924、启动服务
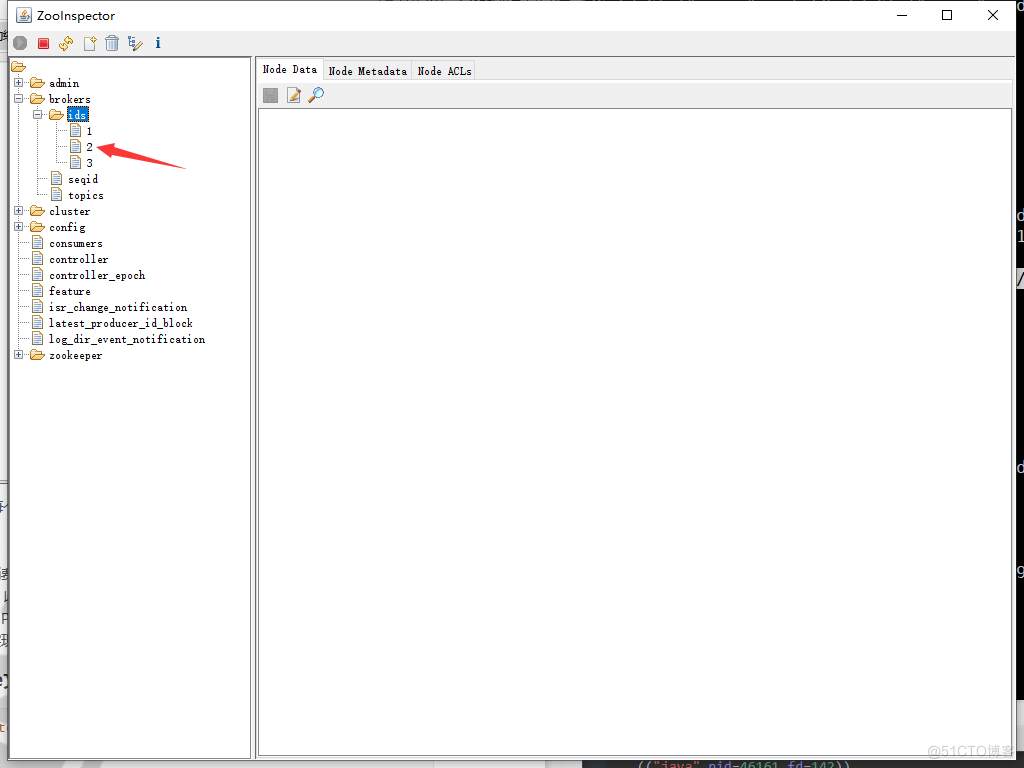
[root@node1 local]#kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties#@注:vim /usr/local/kafka/bin/kafka-server-start.sh 里的" -Xmx1G-Xms1G" 可以调整内存 # 确保服务启动状态[root@node1 local]#ss -ntlp | grep 9092LISTEN 0 50 [::ffff:10.0.0.101]:9092 *:* users:(("java",pid=46161,fd=142))# 打开zooinspector可以看到三个id