1.课题意义及目标 中文分词技术不断发展,各种中文分词系统层出不穷。中文分词技术应用也原来越广泛。如搜索引擎的应用、语音识别系统、机器翻译、自动分类校对等。学生应通
1.课题意义及目标
中文分词技术不断发展,各种中文分词系统层出不穷。中文分词技术应用也原来越广泛。如搜索引擎的应用、语音识别系统、机器翻译、自动分类校对等。学生应通过本次毕业设计,综合运用所学过的基础理论知识,深入中了解文分词技术,为学生在毕业后相关工作打好基础。
2.主要任务
研究常见的几种分词方法,阐述其原理、优缺点。
着重研究正向最大分词的原理,得出相关结论。
根据最大分词方法做出相应程序来实现对若干句子的分词,在记事本(或Word)中显示出来并比较几种分词方法的优缺点。
3.主要参考资料
[1] 宗成庆.统计自然语言处理[M].北京:清华大学出版社.2008:105-143.
[2] 刘件,魏程. 中文分词算法研究[J]. 微计算机应用.
[3] 崔彦翔.基于条件随机场的网络研究[D].大连:大连理工大学,2013.
4.进度安排
摘 要
本毕业设计主要对几种常见的中文分词算法的切分结果进行了研究对比。阐述了分词算法的原理,着重研究了正向最大分词的原理,分析了分词算法的思想、数学模型及算法的实现。在以上分析研究的基础上,本毕业设计基于机械分词算法,结合了N-Gram模型在前人研究的基础上采用JAVA程序设计语言,结合更加优良的存储和匹配方法,设计出相应的分词程序,最终实现了对若干句子的分词,并在文本文档中显示出切分结果。同时相应的提高了中文分词的效率和正确率。
本毕业设计采用了先进的软件工程的设计方法,通过研究分析,使用概要设计、详细设计的方法,运用JAVA程序开发语言等技术手段,进行了系统化的设计与实现。本文的最后对本次设计及论文进行了总结,提出了需要改进之处并展望了中文分词算法的美好前景及应用。
关键字:中文分词,正确率,机械分词算法,JAVA语言
The Research and Implementation of Chinese Word Segmentation Algorithm
Abstract
The article researched the different of the common types of the results of the Chinese word segmentation ,and illustrated algorithm,especially the principle of forward maximum matching method,what’s more,this article has also analyzed the theory of segmentation algorithm,also the realization of mathematical model and the algorithm has been studied.What’s more,based on the mechanical word segmentation,the paper used the N-gram model,the Java program language,finally realize the segmentation of have been improved.
In a word,by using the advanced design method of software engineering,basically achieved the good of the design and the realization of the system.Besides,I also used the outline design,the detailed design and the Java http://technology.In the end of this paper,the needed improvements of the Chinese word segmentation has been pointed out,also presented the prospect and the application of this advanced segmentation.
Keywords :Chinese word segmentation, mechanical segmentation,accuracy,JAVA language
目 录
1 绪论11
1.1 研究背景11
1.2 研究现状22
1.3 研究目的及意义22
1.4 设计思路及实现技术33
2 中文分词方法研究44
2.1 中文分词的概述44
2.2 中文分词常用算法44
2.2.1 基于词典的分词方法44
2.2.2 基于统计的分词方法66
2.2.3 基于理解的分词方法77
2.3 中文分词的难点77
2.3.1 歧义识别77
2.3.2 新词识别88
2.4 基于词典的正向最大匹配研究88
2.4.1 算法思想88
2.4.2 正向最大匹配算法实现原理1010
2.4.3 N-Gram数学模型1111
2.4.4 Trie树结构1111
2.4.5 Trie树与其他结构的比较1313
3 需求分析1515
3.1 可行性分析1515
3.2 中文分词系统目标的分析1515
3.3 系统功能需求分析1616
4 系统的设计1717
4.1 整体设计1717
4.2 分词系统处理流程1818
4.3 系统的详细设计1919
5 系统实现2222
5.1 分词功能实现2222
5.1.1 优化的分词功能的实现2222
5.1.2 添加分词算法的实现2424
5.2 显示功能2525
5.3 时间与内存显示功能2626
6 系统测试2828
6.1 分词及显示功能测试2828
6.2 切分时间及内存显示测试3030
6.3 测试结果分析3131
7 结论3232
参考文献3333
致谢3434
绪论研究背景词作为微小的语言成分,在日常的生活中可以独立活动且具有实际意义。在五千年文化的积淀下,形成了相应的汉语书写习惯:汉语句子中词与词之间没有明确的自然分界符。中文与被广泛使用的英语相比,中文没有明显的空格来区分词与词之间的具体含义。中文区分词义的明显标识是句子之间的符号(如:顿号、逗号、分号、句号等)以及段落与段落之间的重新分割。中文的这些分界标识并不能作为中文词与词之间的自然分割符来切分文本。换句话说,从形式上来看中文虽然以字为最基本的书写单位,但单个字却不能像英文那样作为词的单位。如:用英语表达一句话,I want to go my home.汉语的表达方式为:我想回我家。我们可以轻易的将用英语表达的句子词义通过空格来区分:I/want/go/my/home 。而同样的意思在汉语的表达语句中我们却不能明显的通过自然分界符来区分词与词之间的意思。“我想回我家”按照正确的理解可将其划分为:我想回/我家。我们之所以能够正确的划分汉语中的词义是因为我们具有思维,而电脑等机器是不像人类一样具有思维的,它们不能用也不会用人类的思维方式将汉语语料进行正确的划分。由于中文中词和词语的边界如此模糊,因此,通常在处理中文语言时,首先处理的是中文文本中的句子,“将句子中的字序列先切分为一个一个的词序列,之后再对切分出来的次序列进行整合分析处理,从而将中文文本的具体含义、关键词提取出来。[1]”同时,中文分词涉及到计算机科学、数学、汉语言学数学三大领域运用了语用学、语义学的知识。随着科学技术的进步,电脑的普及以及互联网的快速发展,使用网络来浏览新闻、查阅资料等等行为看似普通却成为人们日常生活中必不可少的一个环节。论文的查重、关键字的提取、机器翻译、语音识别自动摘要、汉字的智能输入等等越来越多的领域、技术都需要用到中文分词这一核心性、基础性的算法、技术、系统。“20世纪80年代初,自动分词在中文信息处理领域中被提出,从此,研究相关方面的众多专家学者、科研院所、[2]”商业机构便深入研究实践中文的自动分词,在大家的不懈努力下,中文自动分词在中文系息处理领域甚至其他领域取得了一些重要的进展和一些实用性的成果,而且有些成熟的技术已经应用于产品当中。随之相适应的即为各种中文分词方法的产生。根据唯物主义可知,只有运动是绝对的,中文分词方法也必然是具有前进行的,不是完美无缺的,也存在着不足。研究现状“中文分词的研究起始于二十世纪八十年代左右,八十年代初期,我国在中文自动分词方面取得了初步的进展,与此同时,国内的学者也开始对中文分类自动引标技术的逐步进行深入的研究。[3]”1983年北京航天航空大学梁南元副教授采用主辅结合,辅助以词尾字构词纠错技术完成并实现了第一个汉语自动分词系统 CDWS( The Modern Printed Chinese Distinguishing Word System),该系统采用了基于词典的最大匹配算法,能够对2500万字的现代汉语词频进行统计工作,切分精度约为1/625,基本满足了词频统计及其他一些应用的需要。 此后许多科研院校相继研发出许多分词系统:“清华大学早期研制的SEG分词系统提出了全切分的概念、[4]”“清华大学SEGTAG分词系统着眼于将各种各类的信息进行综合从而提高了切分精读、复旦大学的分词系统、[5]”山西大学计算机系研制的ABWS系统、微软研究院的自然语言研究所研究开发的能够处理多国语言的Microsoft Research语法分析器即NLPWwin语法分析器分词系统、1988年北京航空航天大学实现的CASS分词系统哈尔滨工业大学研究的基于统计分词纯切词的统计分词系统、中国科学院计算技术研究所开发的在973专家组测评中获得第一名的ICTCLAS汉语分词系统。现如今,已经可以通过对中文语义所体现的关键词进行自动的提取及筛选,从而实现了语义的自动分离引标。“国外对中文分词技术的相关研究大概也是从1980年初开始的,国外对中文分词技术的研究的大致方向是中文分词技术的应用和评测,国外对中文分词技术的研究大多是介绍自动分词在信息检索、汉字处理、语音处理、内容识别与分析、自然语言理解等方面的应用。[6]”同时也相应的阐释了中文分的词难点及其在信息检索中的应用。国外也有少部分专门针对分词技术做研究。Fu lee Wang 采用数据库挖掘的方法解决了中文分词问题,提出了一种新的分词规则,从一方面提高了分词的效率及准确率。研究目的及意义在日常生活工作中,我们可以发现网站、网页等信息英文居多,利用互联网进行信息检索时英文的检索要比中文的检索效率高一些。造成这种结果的主要原因除了英语是通用的的语言之外,最重要的一个原因是英文不需要分词即英文在词的利用上具有先天性的优势,而中文则需要进行分词这一关键性步骤。所以研究中文分词是非常有必要的,具有非常重要的意义,对个体来说,可以节约时间从而提高效率;对于企业来说,研究好中文分词会给企业的发展带来战略机遇,因为如果国外的计算机处理技术如果想要打入中国市场,那么首先他们必须入乡随俗,考虑中国国内的市场需求,那么就必须拥有中文分词技术;对我们国家来说,研究好中文分词才会为超越英文使中文在信息领域的主导地位,有利于科学技术的进一步发展,体现中国作为大国、强国的风范。中文分词在分词标准以及在分词算法上相比起英文分词来说,都存在着一定的困难,需要通过不停的研究、优化,不断的提高中文分词的效率和准确性。本文对中文分词的常用算法进行了比较分析,借用已有的分词系统对分词的准确率进行了统计。本毕业设计基于机械分词算法,结合了N-Gram模型在前人研究的基础上采用JAVA程序开发语言,结合更加优良的存储和匹配方法,做出相应的分词程序,最终实现了对若干句子的分词,并在文本文档中显示出切分结果。同时相应的提高了中文分词的效率和正确率。本文的研究成果可以作为中文分词相关研究的参考,为中文分词算法研究提供一种思路和方向。同时在研究中思考问题、解决矛盾的方法能够为今后无论是在学习、生活还是工作中可以提供一种特别的角度。设计思路及实现技术本毕业设计采用基于词典的分词算法,对算法进行实现。在实现的过程中将N-Gram模型应与全切分技术结合、将正向最大分词算法与逆向最大分词算法结合对词典进行双向扫描,并引入利基于trie索引树的分词词典机制进行词典优化。本毕业设计在中文分词技术实现过程中采用了典型的软件工程工作方法,通过调查研究、需求分析、概要设计、系统设计、编码、测试,在windows7的环境下采用myeclipse开发工具,用JAVA程序开发语言实现中文分词。
中文分词方法研究中文分词的概述中文中的基本单位是字,字与字组成了句子,一个句子中有若干个词语,词语只能人为的划分出,所以在九年义务教育的语文课堂中,会学习断句、划分句子成分等来识别句子、文段、文章的具体含义。而中文分词就是通过一定的中文分词算法将中文文本进行切分,将中文句子切分为与原中文文本意思相一致的若干个词语(即若干个有实际意义的的词语)。“中文分词技术从科学领域来划分,它是属于自然语言处理的技术范畴。让电脑能够准确的理解中文文本的具体实际意义的处理过程就是对中文进行分词,也叫切词。[7]”中文分词常用算法中文自动分词系统中现有常用的分词方法主要有三种:(1)基于词典的分词方法;(2)基于统计频率的分词方法;(3)基于理解的分词方法。基于词典的分词方法(1)机械分词的阐述基于词典的分词方法又被叫做机械分词方法。这种方法是将中文文本中的字符串与词典(已有的固定的词库)中的字符串(词条)进行匹配,如果在词典中没有找到相应的字符串,则匹配失败,按照一定规则重新进行匹配;如果在词库中找到该字符串则匹配成功,即成功且分出一个词。基于字符串匹配的分词方法可以按照不同的规则分为正向匹配算法和逆向匹配算法(根据扫描方向划分)、最大匹配和最小匹配法(根据不同长度优先匹配原则划分)、单纯分词方法和分词与标注相结合的方法(根据是否与词性标注相结合原则划分)。常用的分词方法除了以上几种还有最少切分方法。通常情况下根据排列组合规律又能够将上述方法互相结合从而得到更多的分词方法。最常用的机械分词方法有正向最大匹配法、逆向最大匹配算法、双向匹配算法(采用最大匹配法并将正向与逆向相结合的方法)和最少切分法。“通过对正向最大匹配法及逆向最大匹配法的进行了中文分词的实现,并对分词结果进行了正确率的统计:正向最大匹配的正确率99.408284%,逆向最大匹配法的正确率是99.591837%。[8]”统计结果显示逆向最大匹配算法的正确率高于正向最大匹配算法即逆向最大匹配法优于正向最大匹配算法。尽管如此,上文所述要满足实际需求,准确率必须在99.9%以上,所以在实际中的中文分词系统都是把基于字符串的匹配方法作为最基础的(最初级的)切分方法,在此基础上用其他方法继续提高分词的准确率。现如今主要采用的方法主要有特征扫描。此方法主要是对字符串的扫描方式进行了优化,将一些具有特殊字或者明显特征的词进行先切分,在将这些词抽象为英文中的空格即分界符,再将剩余的字符串进行机械分词进而提高分词的正确率。除此之外还有一种方法是将机械分词与词类标注相结合的方法,借助词类标注的多样性进行分词,反过来又作用于分词的结果即又起到检验员的作用从而提高分词的正确率。机械分词中的辅助工具(词典)①有序线性词典结构有序线性词典顾名思义是一种有序表,该表是以词为单位的,在初始化时将字符串读取到内存中去然后通过二分法寻找定位。该种词典结构的算法简单能够减少空间存储率、方便用计算机语言实现。正因为算法的简单词典排序的有序性导致分词过程中扫描查找效率低且词典不易更新,在更新词典中需要添新词或者删除原有旧词,此过程就必须移动词典中原有不动的词来保证词典的有序性,从而降低了分词效率。有序线性词典结构如表2.1所示。表2.1有序线性词典结构大海
大海茫茫
大河
大河湖海
……
②基于整词二分的分词词典结构基于整词二分的分词词典结构可以分为三个层次:词典正文、次索引表及首字表。同有序线性结构相似该结构词典的正文也是以词为单位的有序表,词索引表是一个指针表,该表指向词典正文中的每个词,在扫描过程中通过hash定位首字表及指针的词索引表能够确定字符串的所在的一个大致的范围,然后在该范围中进行二分定位。基于此词典的扫描范围小于线性有序词典的扫描范围,从而相对的提高切分效率。有序线性词典结构如表2.1所示。
啊
阿
……
大
……
004
067
……
654
……
……
……
……
啊
啊哈
啊呀
啊哟
阿
阿Q
……
表2.2基于整词二分词词典结构首字hash表入口项个数第一项指针词典索引表词典正文指针词典正文③基于trie索引树的分词词典机制“Trie索引树是键树,表示形式为多重链表。该词典分为两部分:首字表和trie索引树结点。该词典在扫描过程中沿树链逐字进行一一匹配。[2]”由于一个词作为一个树枝,所以空间占有率大,造成资源浪费。
基于统计的分词方法基于统计的分词方法又称作统计取词法或无词典分词法。由于汉语中字与字组成了词,当几个字的经常相邻出现时我们就可以计算其共现率,当共现率高于一定值时,我们便可以人为的认定该字符串很有可能是一个词。然后切分出该字符串作为一个词组。这种方法不需像机械分词一样需要词典,只需要统计文本中字符串的共现率即可。毕竟计算机是机器而不具有思维,所以在取词的过程中不能很准确的区分识别该字符串是否为常用的词组,如“是的”、“你的”、“有些”、“是以”等。所以该方法的识别精度低而时空开销大。在实际的应用中该方法一般都会加入基础的日常词典,在统计分词的同时进行字符串匹配分词,将二者相结合提高分词的效率和准确率,同时避免歧义识别。基于理解的分词方法计算机作为一种机器不具备人的思维,而给予理解的分词方法则是模拟了人分析文本的思维方式,让计算机与人一样去理解句子,从而对文本进行切分识别。该分词方法在对词进行切分时需要同时对语法、语义进行分析,通过分析处理来消除歧义切分文本。该方法需要一个总控系统,在该系统的调控下同时使用分词子系统和句法语义子系统来对中文文本进行处理。由于该方法需要结合庞大的汉语系统知识等,所以就目前现状来看,该系统还不成熟,其成熟实现仍需要继续大量深入的研究与实践。中文分词的难点汉语语言博大精深,人都不可能完完全全的理解汉语,正所谓一千个读者就有一千个哈姆雷特,所以让一个没有思维的计算机来理解汉语是不容易的。从中文分词系统研究开始到现在,歧义识别和新词识别仍是中文分词方法研究课题的两个难点。歧义识别对一句话的理解,不同的人可能有不同正确的理解,而在计算机切分时就会出现更多的正确的、不正确的切分方法,这就产生了歧义。歧义主要有交叉歧义、组和歧义。交叉识别就是在切分文本的时候一个字可以同时和前后相邻的词组成一个词组,加上计算机不会像人一样去分析理解句子的具体含义,从而导致切分结果多样化。如:我想回我家。因为“回我家”和“回我”、“我想”和“我想回”这几个字符串都组成了词组,所以对于这句话的切分就可以分为“我想回 我家”或者“我想 回我家”或者“我想 回我 家”。组合歧义就两个相邻的词相结合在不同的句子中可能切分出来时,正确的表述了句子的意思,也可能出现错误切分。如:“这个羽毛球拍卖不卖”中的“拍卖”和“拍卖会”中的“拍卖”,前者以“拍卖”来切分按照语句意思完全是错误的,而后者则是正确的切分。新词识别在一个分词系统的词典中,收录的词毕竟是有限的,而那些未收录进词典的词组即为新词。新词有地名、人名、网络语等等一系列时时更新、不断变化的词。如山西的运城,对于“运城是一座美丽的城市”和“秦皇岛是海上货运城市”这两句话中的“运城”“货运”“城市”,运城是否能算作一个词,对于计算机而言是很有难度的。所以新词识别在中文分词系统中能够评价一种分词系统优劣的主要指标。基于词典的正向最大匹配研究机械分词算发就是在系统中导入或者建一个字典库,将字符串序列与字典词库中的词组进行一一匹配。具体方法是,将待切分的字符串序列i,按照一定的规则取出字符串序列i的子字符串序列i1,将i1与字典库中的词组进行匹配,若字典库中有一个词组与i1相同,则成功切分出字符串序列i1,继续切分其余字符串序列;若字典词库中不存在该字符串序列i1,重新按照规则取出另一个字符串序列进行匹配。算法思想最大正向匹配法的基本思想为:假设字典库中最长的字符串有i个汉字字符,则在要被处理的中文文本中选取前i个字符作为一个匹配字符串序列,扫描字典库,若在字典库中能够找到这样的i个字符的字符串序列则匹配成功,则成功切分出该字符串序列;如果找不到则匹配失败,去掉i字符串序列中的最后一个汉字字符,对剩下的(i-1)个字符串序列继续重新匹配处理。如此循环直到待处理的中文文本全部处理结束。算法的流程图如图2.1所示。
图2.1 正向最大匹配算法流程图
正向最大匹配算法实现原理(1)TrieNode具体实现方法:建立TrieNode类 ;建立结点关键字,public char key=(char)0;其值为中文词中的一个字。如果该字在词语的末尾,则bound=true,public boolean bound=false;建立指向下一个结点的指针结构,用来存放当前字在词中的下一个字的位置如:Public HashMap<Character,TrieNode> childs=new 。在全切分的算法中利用N-Gram模型给每一种切分结果计算分值。如果多个切分结果分值相同,则选择切分出的词的个数最少的切分结果(最少分词原则)。(2)假设词典中保存了如下词:{今天,是,周末,原来}假设要进行分词的例句如下:“原来今天是周末啊!”我们设最大词长为5;从左边截取5个字:原来今天是原来今天原来今原来此时,我们得到一个词:原来从“原来”后面继续截取5个:今天是周末今天是周今天是今天此时,我们得到一个词:今天是周末啊是周末是周是 此时,我们得到一个词:是周末啊周末此时,我们得到一个词:周末最后正向最大匹配的结果是:原来/今天/是/周末/啊N-Gram数学模型N-Gram是一种语言模型。该模型也是搜狗拼音和微软拼音的主要思想。在实际的中文分词系统中不单单采用一种分词方法,也会采用基于统计频率的算法。N-Gram模型需要一个假设前提:第i个词的出现仅仅与前面(i-1)个词有关,与其他的词都没有关系。而该句话的概率就是每个词出现的概率的乘积。N-Gram模型常用的是二元的Bi-Gram模型和三元Tri-Gram模型。对于统计序列(汉子字符串序列)C(W1 W2 … Wi …Wn)第i个字符出现的概率只与前(i-1)个字符有关,其概率为:由和N-Gram模型可得:统计序列(汉子字符串序列)C(W1 W2 … Wi …Wn)在要处理文本中出现次数:C(W1 W2 … Wi …Wn)得:Trie树结构(1)Trie树(字典树)的结构有三种:标准树、压缩树、后缀树。Trie树在中文分词算法中的应用是用来存储大量的字符串从而提高分词时扫描的效率。前缀Trie的使用能够保证在最大匹配时进行的下一次扫描是非词典词或者不是词的前缀。Trie树中,字符串序列中所有的含有公共前缀的字符串位于同一个结点。如集合B{bear,bell,bid,bull,buy,sell,stock,stop}的Trie树图如图2.2所示。其中圆形代表内部结点,方形则为外部结点。
图2.2 标准Trie树(2)若大小为b的字母表中存在s个字符串的集合B,其存储长度是l,该集合B的Trie树具有如下性质:① Trie树中每个内部结点最多有b个子结点。② Trie树中有s个外部结点。③ Trie树的高度与集合B中最长串的长度相同。④ 树中的结点数为O(l)。(3)Trie树的基本性质可以归纳为:① 根节点不包含字符,除根节点以外的每个结点有且只有一个字符。② “字符串是将路径上的字符连接起来的,从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。[9]”③ 每个节点的所有子节点包含的字符串不相同。④ 如果字符的种数为n,则每个结点的出度为n,这也是空间换时间的体现,浪费了很多的空间。⑤ 插入查找的复杂度为O(l),l为字符串长度。(4)Trie树结构的数据搜索方法如下:① 首先由根结点开始;② “取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;[9]”③ “在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。[10]”④ 迭代以上搜索过程……⑤ “在某个结点处,关键词的所有字母已被取出,则读取附在该结点上的信息,从而完成查找。[11]”
Trie树与其他结构的比较Trie树,在生活中比较常见的应用就是搜索自动提示,当我们在搜索框中输入字串信息的时候,如“山西”,提示“山西省”;再有就是我们平时使用的输入法的联想功能,也是同样原理。(1)Trie树与二叉搜索树(binary search tree)的比较二叉搜索树具有以下特点:① “若果任意节点左子树不为空,那么左子树所有节点的值都小于根节点的值;[12]”② “如果任意节点右子树不为空,那么右子树所有节点的值都大于根节点的值;[12]”③ 左右子树也都是二叉搜索树;④ 所有节点的值都不相同。其实二叉搜索树的优势在于查找、插入的时间复杂度上了,其复杂度通常只有O(log n),现实中有很多的集合都是通过二叉树实现的。“在二叉树上进行插入操作时,实质上是给树添加了新的叶子节点,不需要节点移动;[12]”搜索、插入和删除的复杂度等于树的高度,其为O(log n),最坏情况下整棵树所有的节点都只有一个子节点,完全变成一个线性表,其复杂度为O(n)。Trie树在最坏情况下数据查找的速度,也要快过二叉搜索树的速度,如果搜索字符串长度用m来表示的话,它只有O(m),通常情况(树的节点个数要远大于搜索字符串的长度)下,Trie树要远小于O(n)。当然,Trie树也存在一个缺点,那就是Trie本身对key的适宜性是有严格要求的,之前我们举例都是使用的字符串,如果Trie树的key是浮点数的话,就很有可能导致整个Trie树很长,节点的可读性也会变的很差,在这种情况下,我们是不适合使用Trie树来进行保存数据的;相反二叉搜索树就不会存在这个问题。(2)Trie树与Hash结构比较Hash结构的首要问题就是表键冲突的问题。通常我们说Hash表的复杂度是O(1),其实严格意义上来说,这是接近理想的Hash表的复杂度,现实中我们还需要考虑到hash函数本身需要遍历搜索字符串,其复杂度往往是O(m)。在不同键被映射到“同一个位置”(考虑closed hashing,这“同一个位置”可以由一个普通链表来取代)的时候,需要进行查找的复杂度,是取决于这“同一个位置”下节点的个数。所以在现实中,最坏情况下,Hash表也能作为一张单向链表的。Trie树可以很容易地以key的字母序排序(整棵树只需要先序遍历一次即可),该方法对现实中很多Hash表来说是不一样的的,因为一般来情况下Hash表对于不同的key来说是无序的。在理想情况下,Hash表是可以以O(1)的速度迅找到我们想要的数据,但是,如果这张表非常大的时候,而有要放入磁盘,对于Hash表来说,在理想的情况下,其查找访问进行一次即可;但对于Trie树来说,访问磁盘的数目需要等于节点深度。在大多数情况下Trie树占用的空间要多余Hash表所占空间,如果要在一个节点放一个中文字符,对于字符串的保存来说,是不能独立成块的。但是我们可以利用Trie书的节点压缩来弥补此不足。
需求分析可行性分析对中文分词算法来说,从二十世纪八十年代开始国内专家学者就已经对中文分词有了一定深入的研究,所以从中国知网、万维网等学术性网站中可以找到相关的参考文献。作为一名即将毕业的大学生,也具备了自学的能力,能够理解相应的算法。目前也有相关的中文分词系统,能够进行测试统计,运用逻辑统计整理出几种常用分词算法的准确率,并整理出其优缺点。对中文分词技术来说,目前已经有了相对成熟的中文技术,并且已经应用在了人类实际工作、生活环境中。这些技术都可以找到相关的技术参考资料,并且能深入研究。并且,截至到目前为止已经对软件工程、数据结构、JAVA语言等相关计算机知识、技术和计算机语言有了较为深刻的理解,并能够熟练的运用相关计算机技术进行设计、编程、开发。另外,从课题研究的时间上来看,从开始到结束有将近14周到时间可用来工作,时间上也是充足可靠的。从物质投入来看也不存在额外的投入,学校提供免费的图书资料,所以以目前的条件足以进行开发研究。因此,进行中文分词方法的研究是具备一定可行性的。中文分词系统目标的分析随着科学技术的不断发展、互联网的普及越来越多的技术、软件需要用到中文分词技术,该技术、系统也越来越受到大家的关注。近几年来,人工智能领域、自然语言领以及情报检索界的专家学者对中文分词进行了深入的研究与实践,探索出了多种既可以提保证正确率又能够提高中文分词效率的中文分词的算法和系统。专家学者们在研究中文分词系统时在其分词的速率、准确率等方面有了进一步的研究同时也有了相应的提高。目前,在中文分词常用的算法中,机械分词的应用最为普遍、广泛。中文分词系统的的目标:(1)高精确;(2)高效率;(3)适应性。(1)高精确。任何一件事正确率是最基础的。中文分词系统也不例外即中文自动分词系统的核心关键是高准确率。目前的中文自动分词系统中有少数分词系统的准确率在98%—99%之间,然而分词的结果应当是高精确的,98%—99%对于中文分词来说这样的准确率是不够的,准确率只应该降低0.1甚至更少的百分点。只有提高准确率才能更好的满足实际需求。在99.9%的准确率上,即使提高1/1000的百分点对于实际的需求也是具有相当大的现实意义。(2)高效率。由于中文分词在各个系统中处于最基础的环节,所以能节约时间尽量节约时间,减少不必要的时间消耗。一个复杂繁琐的大系统必须在各个环节都用尽可能少的时间,让用户使用时觉得更加方便快捷。而中文分词作为最基础的一个部分,在工作时应该高速运行达到5千字/秒—1万字/秒甚至更快为最佳。(3)适应性。适应性包括普遍适用性及多平台通用。中文分词系统不是最终的系统也不是最终的上层结果,而是一种基础性的方法、手段,是为了其他终极目标而打下的地基,为了能够更加方便的适用于在各种各样的系统中,所以应当具有普遍系统能适用的性质。中文自动分词系统在多领域的系统中处于基层环节,要具有良好的通用性来适用于各种相关但又不同的高层次系统,只有具备通用性,支持不同系统、不同地区文字的处理才能减少不必要的消耗。系统功能需求分析基于词典(字符串)的中文分词系统实现的功能如下:(1)分词功能:系统可以调用机械分词算法可以对txt格式中的文本进行分词,也可以对标准输入的文字串进行分词。(2)显示功能:系统能够将切分结果、切分时间在标准输出中显示出来;也能够将txt格式中的文本处理后的结果以txt格式返回到指定的目录下。(3)时间显示功能:在切分结果完成后,可以对切分所用时间进行显示。(4)内存显示功能:在切分结果完成后,可以对切分过程中程序运行所占内存大小进行显示。
系统的设计整体设计系统各功能模块、算法模块相互独立,能够提供功能全面的接口供其它应用系统调用,而不仅限于本系统使用。分词系统的框架图如图4.1所示。图4.1分词系统框架图该框架分成三部分:第一部分由词频信息统计、更新、语料库、语料学习构成的字典管理,实现字典的更新功能;第二部分是由待分词文本、预处理、词汇切分组成的分词器,实现对中文的切分功能;第三部分是由输出和最终分词结果组成的显示器,实现显示功能。分词系统处理流程预处理:预处理操作将读入的文本进行去标点符号操作,并把整个文本切分成一个字符串序列,并对其进行编码转换。分词:对预处理完成的字符串进行正向逐字匹配划分和逆向逐字匹配划分,将两个结果进行对比,如果不同,就进行消除歧义处理。中文分词系统处理流程如图4.2所示:
图4.2中文分词系统处理流程
系统的详细设计该中文分词系统的设计主要核心类有:CorpusTools该类是语料库工具类,用于构建二元模型和三元模型并做进一步的分析处理,同时把语料库中的新词加入词典。主要方法有:process和analyzeCorpus方法用于分析语料库,constructNGram用户建模型,processBiGram分析二元模型,processTriGram分析三元模型,processWords分析处理并存储不重复词,mergeWordsWithOldDic和旧的词典进行合并,processPhrase用于生成短语结构。CorpusTools类图如图4.3所示。图4.3 CorpusTools类图DictionaryTools类是词典工具类,用于把多个词典合并为一个并规范清理,移除词典中的短语结构。主要方法有:removePhraseFromDic用于移除词典中的短语结构,merge把多个词典合并为一个。DictionaryTools类图如图4.4所示。图4.4DictionaryTools类图recognitionTool类是词典工具类,用于把分词特殊情况识别。主要方法有:recog用于识别文本,isFraction用于小数和分数识别,isEnglishAndNumberMix用户英文和字母混合识别,isEnglish用于英文字母识别,isQuantifier用于数量词识别,isNumber用于数字识别,isChineseNumber用户中文数字识别。recognitionTool类图如图4.5所示。图4.5recognitionTool类图WordConfTools类是词典工具类,用于获取配置信息。该类中的方法都是用于获取配置文件的,具体方法名在类图中显示。WordConfTools类如图4.6所示。图4.6WordConfTools类图
系统实现分词功能实现优化的分词功能的实现系统可以调用机械分词算Ian法可以对txt格式中的文本进行分词,也可以对标准输入的文字串进行分词。进入系统之后,首先会有一个选择的界面,这个选择界面是通过switch...case...语句实现的,每一个case语句后都会有一个选择的标识,在标识后面,是用户选择了该标识之后会执行的函数体,这样就实现了用户可以选择的效果,用户通过自己需要的选择进入到系统之后,会执行不同的函数体,当用户选择了对txt格式中文本进行分词的选项之后,系统会首先在主函数中调用机械分词的算法,然后通过读取文件的语句读取到文件中的信息,保存在一条字符串中,这个字符串中现在保存的是从txt文件中读取出来的文件,这时候,系统会将从txt中保存的字符串传入到该机械分词算法函数的参数中,该函数执行完毕之后会返回一条同样是String类型的字符串,保存到一个string变量中,然后将这条字符串保存到新的txt文档中,这样就实现了对txt格式中的 文本进行分词的功能。同样,当用户选择了对标准输入的文字串进行分词的功能之后,会之后该选择后的函数体,首先,系统同样会调用系统的机械分词的算法函数,该函数需要传入一个String字符串作为参数,返回一个新的String字符串,在这个函数体中,因为需要接收用户输入的信息,所以会用到Scanner,这样系统就能接收到用户输入的信息了,在系统接收到用户输入的信息之后,会将该用户的信息保存在一个String字符串中,然后将该String字符串传入到函数中作为参数,在函数执行结束之后,系统会将结果返回的字符串保存到一个新的string字符串中,输出,这样,就完成了该功能流程。在实现分词算法前,首要解决的问题是机器词典的选择和加载方式。本系统使用核心词典为年1998年人民日报1月份语料经加工后统计出的词条,共有10456个词。为了便于调用和提高算法整体性能,先将词典文件进行词条排序,并抽象成JAVA类,然后通过JAVA序列化成*.dct格式的文件将其保存。当系统启动加载词典时,通过JAVA反序列化将*.dct文件转化成Dictionay对象,完成加载过程。词典序列化结构中汉字字符编码集为utf-8。基于词典的正向最大匹配算法的分词功能实现图如图5.1所示。
图5.1基于词典的最大匹配算法的分词功能模块实现图基于词典的最大匹配算法的分词功能实现图如图5.2所示。图5.2

基于词典的最大匹配算法的分词功能实现图
添加分词算法的实现在包中新建一个类,在类中新建一个方法把别人的方法添加进去然后在主函数新建一个该类的对象用对象点出方法,直接调用已有的分词算法。双向最大最小匹配算法的分词实现图如图5.3所示。
图5.3双向最大最小匹配算法的分词实现图正向最小匹配算法的分词实现图如图5.4所示。

图5.4正向最小匹配算法的分词实现图
基于词典的全切分算法的分词实现图如图5.5所示。图5.5

基于词典的全切分算法的分词实现图基于逆向最大匹配算法的实现图如图5.6所示。5.6

基于逆向最大匹配算法的实现图
显示功能系统能够将切分结果、切分时间在标准输出中显示出来;也能够将txt格式中的文本处理后的结果以txt格式返回到指定的目录下。这个功能的实现 流程大概描述如下,首先使用Date date=new Date();获取当前系统的时间,然后通过SimpleDataFormat的format方法,在方法中传入yyyy-MM-dd hh:mm:SS来获取当前系统的时间,形式就是前面的样子,这个样子就是时间显示的模版,当系统执行切分函数的时候,会通过上述的方法来记录当前函数执行的时间,然后通过System.out.println()的方式输出当前的时间。切分的方法会返回一个String类型的字符串,这个字符串会在函数执行结束之后,被保存在一个String类型的字符串中,然后同样是通过System.out.println()的方法来输出这个字符串,这样,就实现了系统可以将切分结果和切分函数执行的时候标准输出了。将txt格式中的文本处理后的结果以txt格式返回到指定的目录下的这个功能,首先将通过流inputStreamReader读取到程序中,在程序中,使用一个String类型的 字符串接收到txt文本中的内容,然后将这个内容传入到需要处理的函数中,在函数执行结束之后,同样会返回一个String字符串,这个字符串,通过OutputStreamWriter写入到指定的txt文件中,这样,就实现了这个功能。显示功能如图5.7所示。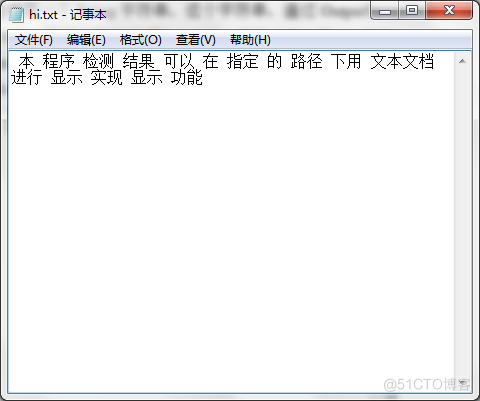
图5.7txt格式显示图
时间与内存显示功能在WordSegmenter.java类的主函数中:long cost = System.currentTimeMillis() - start;float rate = textLength/cost语句实现对切分时间的显示。在WordSegmenter.java类的主函数中:使用String pre="执行之前剩余内存:"+max+"-"+total+"+"+free+"="+(max-total+free);String post="执行之后剩余内存:"+max+"-"+total+"+"+free+"="+(max-total+free)语句实现对内存的计算及显示。时间及内存占用大小显示如图5.8所示。
图5.8时间及内存占用大小显示图
系统测试分词及显示功能测试本中文分词系统中可以调用多种算法,在不同算法下对中文文本进行切分,可以直接显示,也可以在文本文档中显示。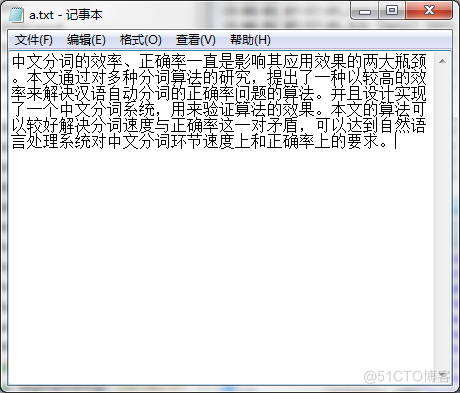
将记事本中的内容如图6.1所示分别进行正向最大分词、正向最小分词、双向最大分词、全切分。图6.1待切分的中文文本
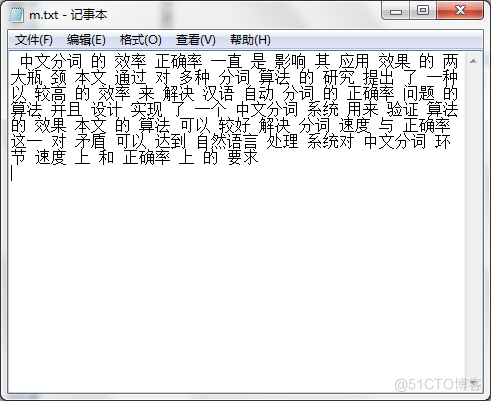
正向最大分词切分结果如图6.2所示。图6.2正向最大匹配算法的分词结果
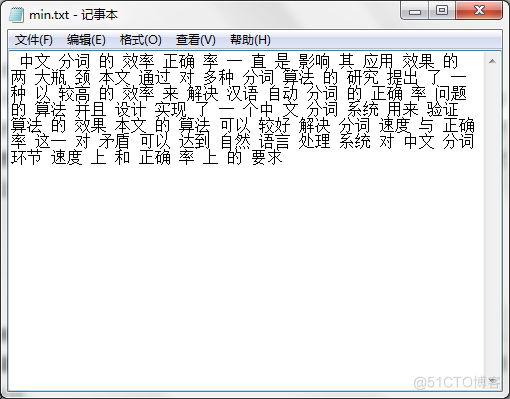
正向最小匹配分词切分结果如图6.3所示。图6.3正向最小匹配算法分词结果双向最大分词切分结果如图6.4所示。
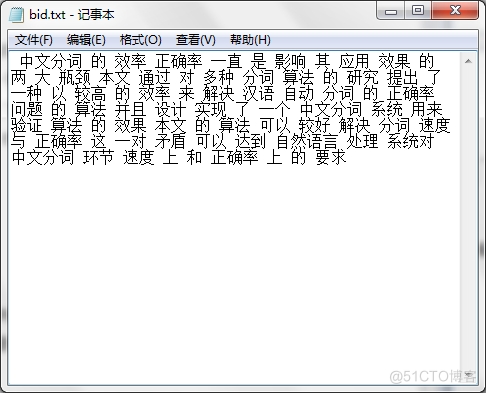
图6.4双向最大匹配算法的切分结果全切分的分词切分结果如图6.5所示。
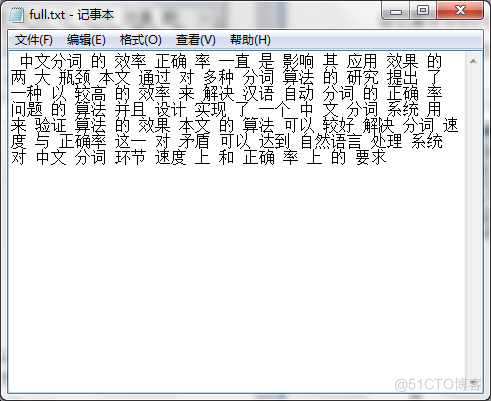
图6.5全切分的切分结果
切分时间及内存显示测试(1)正向最大匹配分词:字符数目:155分词耗时:63701 毫秒执行之前剩余内存:259.52255-16.252928+10.72676=253.99638执行之后剩余内存:259.52255-173.20346+99.0102=185.32928(2)正向最小匹配分词:字符数目:155分词耗时:58390 毫秒执行之前剩余内存:259.52255-16.252928+10.733336=254.00296执行之后剩余内存:259.52255-173.20346+99.010185=185.32928(3)双向最大匹配分词:字符数目:155分词耗时:70654 毫秒执行之前剩余内存:259.52255-16.252928+10.726304=253.99593执行之后剩余内存:259.52255-259.52255+26.046408=26.046408(4)全切分算法字符数目:155分词耗时:67812 毫秒执行之前剩余内存:259.52255-16.252928+10.726544=253.99617执行之后剩余内存:259.52255-259.52255+24.919064=24.919064测试结果分析最大匹配分词和最小匹配的切分结果中,对“最大瓶颈”、“这一对”均出现了歧义切分,而双向最大匹配中避免了该问题。在正向最小匹配的切分结果中将“中文分词”切分为“中文 分词”,“正确率”切分为“正确 率”,“自然语言”切分为“自然 语言”。在多次的中文文本切分中,双向最大匹配相对其他两种分词算法来说正确率是相对比较高的。在全切分中切分得此基于N-Gram模型进行频率统计,所以切分的结果词是不稳定的,如“中文分词”第一次被切分为“中文分词”,第二次则被切分为“中文 分词”。通过比较分析,正向最小匹配算法正确率低耗时短,运行过程中所占内存比较小;双向最大匹配算法正确率高耗时长,运行过程中所占内存比较大。
结论本毕业设计对基于词典的分词算法、基于统计的分词算法和基于理解分词算法进行了研究。重点对基于词典的分词算法的切分结果进行了研究对比。阐述了此算法的原理,着重研究了正向最大分词原理,分析了分词算法的思想、数学模型计算法的实现。本毕业设计主要使用JAVA程序设计语言,设计实现了一个中文分词系统,实现了分词功能、显示功能及切分消耗时间及所占内存的显示功能。通过该系统的功能验证算法的正确率及分词速度。
本设计目前存在的不足有:(1)只能显示待切分的字符数、消耗时间、运行前后内存剩余,没有正确的显示对分词速度;(2)只能在myeclipse中运行,通用性不强;(3)只能用JAVA程序设计语言调用、修改该程序,平台单一,对JAVA语言不熟悉的用户不能很好的使用该程序完成中文检索、语音识别等其他上层系统。在设计研究中还不能很好的完成分词算法的明显优化,对算法的数学模型也不能灵活使用,希望通过今后继续努力研究能够研究出更优化的算法及更高效的分词程序,并针对不足做出改进。
参考文献
[1] 陈晓霞. 中文信息处理在动态几何软件领域的应用研究[J]. 浙江科技学院学报,2012,01:30-34.
[2] 曹卫峰. 中文分词关键技术研究[D].南京理工大学,2009.
[3] 李宏波. 综合字典和统计分析的中文分词系统的研究与实现[D].武汉理工大学,2010.
[4] 刘婷. 中文自动分词法在全文检索中的研究及应用[D].南京航空航天大学,2007.
[5] 普布旦增. 藏文自动分词技术方法研究[D].西藏大学,2010.
[6] 许荣荣. 中文文本自动分词技术与算法研究[D].郑州大学,2010.
[7] 余战秋. 中文分词技术及其应用初探[J]. 电脑知识与技术,2004,32:81-83.
[8] 赵双柱. 用链栈存储搜索关键字提高中文搜索引擎中分词的速度与精确度[J]. 福建电脑,2010,01:86+90.
[9] 代明壮,马燕,李顺宝. 一种新型整数集上的动态统计数据结构——Irie[J]. 软件导刊,2009,07:14-16.
[10] 孙为,赵永精,宋健. 一种基于Trie的IPv6路由查找方案[J]. 计算机应用与软件,2008,07:35-36+50.
[11] 赵永精. 基于trie的路由查找算法研究[D].兰州理工大学,2007.
[12] 徐翠霞,崔玲玲,张家明. 利用二叉排序树改进结构化P2P模型[J]. 计算机工程与应用,2009,36:101-104.
[13] Schubert Foo,Hui Li.Chinese word segmentation and its effect on information retrieval. Information Processing and Management. 40(2004) 161-190 .
[14] Fu Lee Wang,Christopher C.Yang.Mining Web Data for Chinese Segmentation.JOURNAL OF THE AMERICAN SOCIETY INFORMATION SCIENCE AND ECHNOLOGY. 2007,58(12):1820-1837.
[15] Yunting Tang,Yan Wu. RESEARCH AND IMPLEMENTATION ON CHINESE WORD SEGMENTATION[A]. 宁波大红鹰学院.Proceedings of 2007 International Symposium on Computer Science and Technology(ISCST'2007)[C].宁波大红鹰学院:,2007:3.
[16] S. Maosong, and Z. Jiayan, "A critical appraisal of the research on Chinese word segmentation," Contemporary Linguistics, Vol.3, pp. 22-32, February 2001.
[17] 刘件,魏程. 中文分词算法研究[J]. 微计算机应用.
[18] 崔彦翔.基于条件随机场的网络研究[D].大连:大连理工大学,2013.
致谢
短短几个月的毕业设计,使我从中受到很大的教育和启迪,不仅将大学所学的知识进行了实际应用,还学到了很多书本上学不到的知识。开阔了视野,增长了知识,积累了经验。充分锻炼了自己的动手和应用能力,真正做到了理论联系实际。我能有今天的成绩,是因为身后有那么多的人在关心着我,鼓励着我,不管是同学还是长辈!
本文是在指导导师杨喜旺老师,周晓青老师的悉心指导下完成的。从开题、分析到撰稿和修改等整个论文撰写过程中,导师都给予了细心的建议和指导。导师对本人的学习等各个方面都给予了无微不至的关怀与帮助。在此,我向导师表达崇高的敬意和衷心的感激!
其次要感谢我们的班主任傅宏智老师,四年来,是您孜孜不倦的教导我们,关心我们的学习,照顾我们的生活,教会了我们认识事物的方法和做人的原则。还要感谢孔令德老师,刑敏老师以及所有曾经教过我们知识的老师们,正是你们的无私奉献才有了我们的今天。我们每一点知识的积累都与您们辛勤的帮助密不可分,您们的人格魅力和治学态度令我十分钦佩。我们能看的更远,走的更好,是因为我们站在了您们的肩膀上。
最后,再次向所有关心、帮助、理解和支持我的老师和朋友们致以深深的谢意。谢谢你们给我的无私帮助。