缓存使用指南 缓存是现在系统中必不可少的模块,并且已经成为了高并发高性能架构的一个关键组件。这篇博客我们来分析一下使用缓存的正确姿势。 缓存能解决的问题 提升性能 绝大
缓存使用指南
缓存是现在系统中必不可少的模块,并且已经成为了高并发高性能架构的一个关键组件。这篇博客我们来分析一下使用缓存的正确姿势。
缓存能解决的问题
提升性能
- 绝大多数情况下,select是出现性能问题最大的地方。一方面,select 会有很多像 join、group、order、like等这样丰富的语义,而这些语义是非常耗性能的;另一方面,大多数应用都是读多写少,所以加剧了慢查询的问题。
- 分布式系统中远程调用也会耗很多性能,因为有网络开销,会导致整体的响应时间下降。为了挽救这样的性能开销,在业务允许的情况(不需要太实时的数据)下,使用缓存是非常必要的事情。
缓解数据库压力
- 当用户请求增多时,数据库的压力将大大增加,通过缓存能够大大降低数据库的压力。
缓存的适用场景
对于数据实时性要求不高
- 对于一些经常访问但是很少改变的数据,读明显多于写,适用缓存就很有必要。比如一些网站配置项。
对于性能要求高
缓存三种模式
一般来说,缓存有以下三种模式:
- Cache Aside 更新模式
- Read/Write Through 更新模式
- Write Behind Caching 更新模式
通俗一点来讲就是,同时更新缓存和数据库(Cache Aside 更新模式);先更新缓存,缓存负责同步更新数据库(Read/Write Through 更新模式);先更新缓存,缓存定时异步更新数据库(Write Behind Caching 更新模式)。这三种模式各有优劣,可以根据业务场景选择使用。
Cache Aside 更新模式
这是最常用的缓存模式了,具体的流程是:
- 失效:应用程序先从 cache 取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从 cache 中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
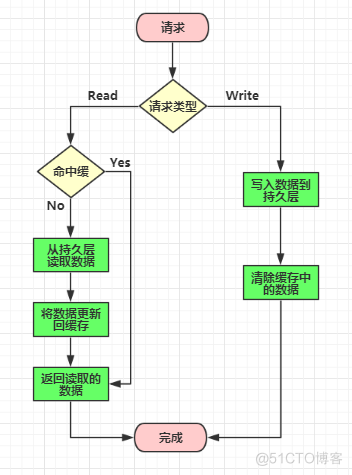
注意我们上面所提到的,缓存更新时先更新数据库,然后在让缓存失效。那么为什么不是直接更新缓存呢?这里有一些缓存更新的坑,我们需要避免入坑。
避坑指南一
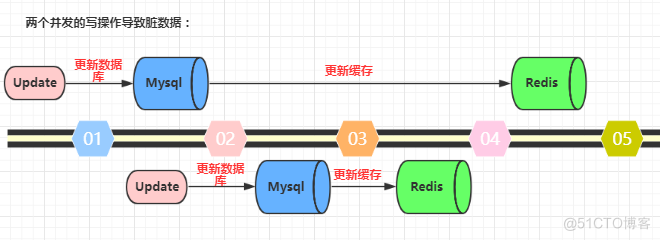
先更新数据库,再更新缓存。这种做法最大的问题就是两个并发的写操作导致脏数据。如下图(以Redis和Mysql为例),两个并发更新操作,数据库先更新的反而后更新缓存,数据库后更新的反而先更新缓存。这样就会造成数据库和缓存中的数据不一致,应用程序中读取的都是脏数据。
避坑指南二
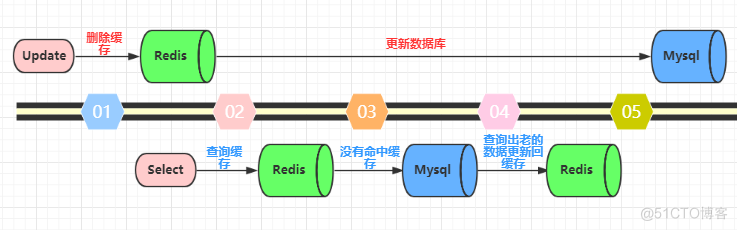
先删除缓存,再更新数据库。这个逻辑是错误的,因为两个并发的读和写操作导致脏数据。如下图(以Redis和Mysql为例)。假设更新操作先删除了缓存,此时正好有一个并发的读操作,没有命中缓存后从数据库中取出老数据并且更新回缓存,这个时候更新操作也完成了数据库更新。此时,数据库和缓存中的数据不一致,应用程序中读取的都是原来的数据(脏数据)。
避坑指南三
先更新数据库,再删除缓存。这种做法其实不能算是坑,在实际的系统中也推荐使用这种方式。但是这种方式理论上还是可能存在问题。如下图(以Redis和Mysql为例),查询操作没有命中缓存,然后查询出数据库的老数据。此时有一个并发的更新操作,更新操作在读操作之后更新了数据库中的数据并且删除了缓存中的数据。然而读操作将从数据库中读取出的老数据更新回了缓存。这样就会造成数据库和缓存中的数据不一致,应用程序中读取的都是原来的数据(脏数据)。
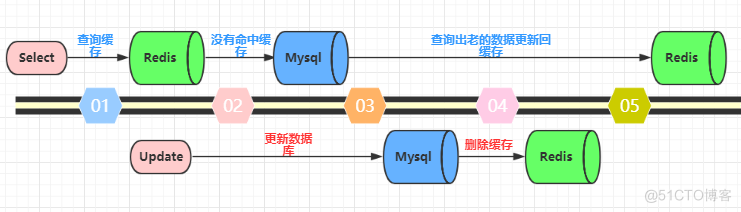 但是,仔细想一想,这种并发的概率极低。因为这个条件需要发生在读缓存时缓存失效,而且有一个并发的写操作。实际上数据库的写操作会比读操作慢得多,而且还要加锁,而读操作必需在写操作前进入数据库操作,又要晚于写操作更新缓存,所有这些条件都具备的概率并不大。但是为了避免这种极端情况造成脏数据所产生的影响,我们还是要为缓存设置过期时间。
但是,仔细想一想,这种并发的概率极低。因为这个条件需要发生在读缓存时缓存失效,而且有一个并发的写操作。实际上数据库的写操作会比读操作慢得多,而且还要加锁,而读操作必需在写操作前进入数据库操作,又要晚于写操作更新缓存,所有这些条件都具备的概率并不大。但是为了避免这种极端情况造成脏数据所产生的影响,我们还是要为缓存设置过期时间。
Read/Write Through 更新模式
在上面的 Cache Aside 更新模式中,应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。而在Read/Write Through 更新模式中,应用程序只需要维护缓存,数据库的维护工作由缓存代理了。
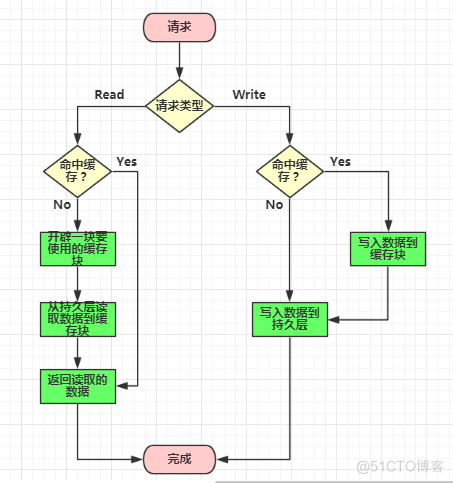
Read Through
Read Through 模式就是在查询操作中更新缓存,也就是说,当缓存失效的时候,Cache Aside 模式是由调用方负责把数据加载入缓存,而 Read Through 则用缓存服务自己来加载。
Write Through
Write Through 模式和 Read Through 相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后由缓存自己更新数据库(这是一个同步操作)。
Write Behind Caching 更新模式
Write Behind Caching 更新模式就是在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是直接操作内存速度快。因为异步,Write Behind Caching 更新模式还可以合并对同一个数据的多次操作到数据库,所以性能的提高是相当可观的。
但其带来的问题是,数据不是强一致性的,而且可能会丢失。另外,Write Behind Caching 更新模式实现逻辑比较复杂,因为它需要确认有哪些数据是被更新了的,哪些数据需要刷到持久层上。只有在缓存需要失效的时候,才会把它真正持久起来。
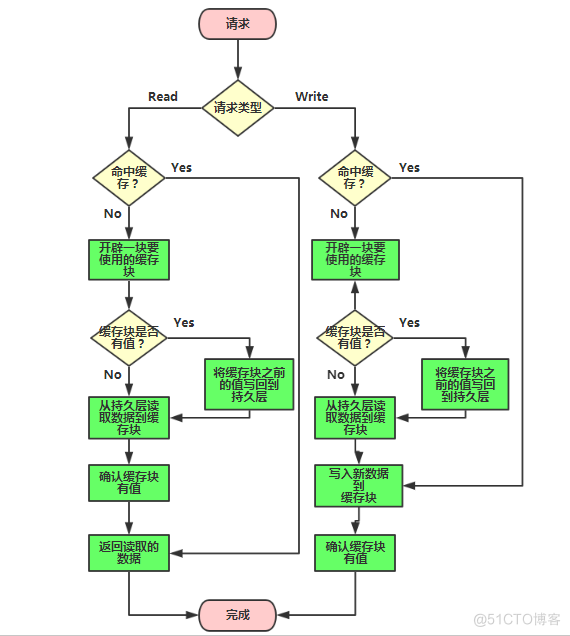
总结三种缓存模式的优缺点:
- Cache Aside 更新模式实现起来比较简单,但是需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。
- Read/Write Through 更新模式只需要维护一个数据存储(缓存),但是实现起来要复杂一些。
- Write Behind Caching 更新模式和Read/Write Through 更新模式类似,区别是Write Behind Caching 更新模式的数据持久化操作是异步的,但是Read/Write Through 更新模式的数据持久化操作是同步的。优点是直接操作内存速度快,多次操作可以合并持久化到数据库。缺点是数据可能会丢失,例如系统断电等。
缓存是通过牺牲强一致性来提高性能的。所以使用缓存提升性能,就是会有数据更新的延迟。这需要我们在设计时结合业务仔细思考是否适合用缓存。然后缓存一定要设置过期时间,这个时间太短太长都不好,太短的话请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势。太长的话缓存中的脏数据会使系统长时间处于一个延迟的状态,而且系统中长时间没有人访问的数据一直存在内存中不过期,浪费内存。
Redis简介
Redis是当前比较热门的NOSQL系统之一,它是一个开源的使用ANSI c语言编写的key-value存储系统(区别于MySQL的二维表格的形式存储。)。和Memcache类似,但很大程度补偿了Memcache的不足。和Memcache一样,Redis数据都是缓存在计算机内存中,不同的是,Memcache只能将数据缓存到内存中,无法自动定期写入硬盘,这就表示,一断电或重启,内存清空,数据丢失。所以Memcache的应用场景适用于缓存无需持久化的数据。而Redis不同的是它会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,实现数据的持久化。
它支持多种类型的数据结构,如字符串(Strings),散列(Hash),列表(List),集合(Set),有序集合(Sorted Set或者是ZSet)与范围查询,Bitmaps,Hyperloglogs 和地理空间(Geospatial)索引半径查询。其中常见的数据结构类型有:String、List、Set、Hash、ZSet这5种。
Redis 内置了复制(Replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(Transactions) 和不同级别的磁盘持久化(Persistence),并通过 Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(High Availability)。
Redis也提供了持久化的选项,这些选项可以让用户将自己的数据保存到磁盘上面进行存储。根据实际情况,可以每隔一定时间将数据集导出到磁盘(快照),或者追加到命令日志中(AOF只追加文件),他会在执行写命令时,将被执行的写命令复制到硬盘里面。您也可以关闭持久化功能,将Redis作为一个高效的网络的缓存数据功能使用。
Redis不使用表,他的数据库不会预定义或者强制去要求用户对Redis存储的不同数据进行关联。
数据库的工作模式按存储方式可分为:硬盘数据库和内存数据库。Redis 将数据储存在内存里面,读写数据的时候都不会受到硬盘 I/O 速度的限制,所以速度极快。
**硬盘数据库的工作模式: **
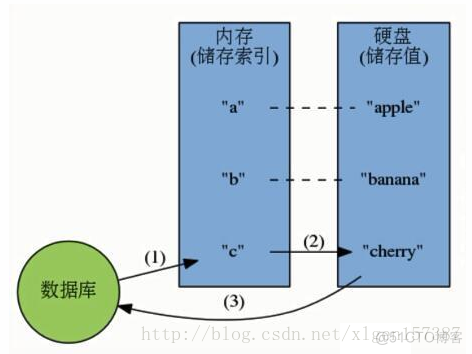
**内存数据库的工作模式: **
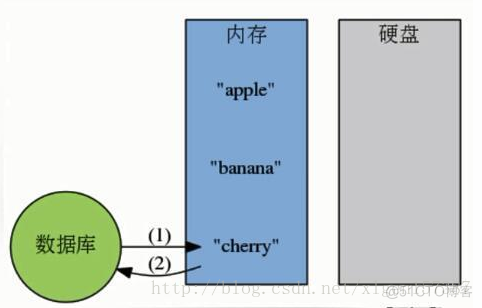
Redis到底有多快
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!有兴趣的可以参考官方的基准程序测试《How fast is Redis?》(https://redis.io/topics/benchmarks)
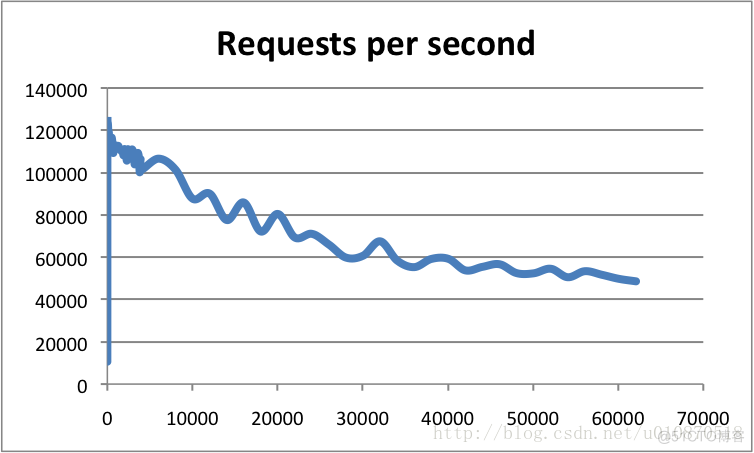 横轴是连接数,纵轴是QPS。此时,这张图反映了一个数量级,希望大家在面试的时候可以正确的描述出来,不要问你的时候,你回答的数量级相差甚远!
横轴是连接数,纵轴是QPS。此时,这张图反映了一个数量级,希望大家在面试的时候可以正确的描述出来,不要问你的时候,你回答的数量级相差甚远!
Redis为什么这么快
- 1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
- 2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
- 3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 4、使用多路I/O复用模型,非阻塞IO;
- 5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
以上几点都比较好理解,下边我们针对多路 I/O 复用模型进行简单的探讨:
多路 I/O 复用模型
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
那么为什么Redis是单线程的
我们首先要明白,上边的种种分析,都是为了营造一个Redis很快的氛围!官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)。

注意:
这里我们一直在强调的单线程,只是在处理我们的网络请求的时候只有一个线程来处理,一个正式的Redis Server运行的时候肯定是不止一个线程的,这里需要大家明确的注意一下!Redis 在持久化时会调用 glibc 的函数fork产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端请求。子进程刚刚产生时,它和父进程共享内存里面的代码段和数据段。这时你可以将父子进程想像成一个连体婴儿,共享身体。这是 Linux 操作系统的机制,为了节约内存资源,所以尽可能让它们共享起来。在进程分离的一瞬间,内存的增长几乎没有明显变化。
Redis的特点
- Redis读取的速度是110000次/s,写的速度是81000次/s
- 原子 。Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 支持多种数据结构:string(字符串);list(列表);hash(哈希),set(集合);zset(有序集合)
- 持久化,主从复制(集群)
- 支持过期时间,支持事务,消息订阅。
- 官方不支持window,但是有第三方版本。
SpringBoot整合Redis
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.10.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 高版本redis的lettuce需要commons-pool2 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
</configuration>
</plugin>
<!-- MyBatis 逆向工程 插件 -->
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.6</version>
<configuration>
<!--允许移动生成的文件 -->
<verbose>true</verbose>
<!-- 是否覆盖 -->
<overwrite>true</overwrite>
<!-- 自动生成的配置 -->
<configurationFile>
${basedir}/src/main/resources/generator/generatorConfig.xml
</configurationFile>
</configuration>
<!--下面这两个可以不配置-->
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.18</version>
</dependency>
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.6</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String,Object> redisTemplate(LettuceConnectionFactory factory){
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(factory);
return redisTemplate;
}
}
@Component
public class RedisUtil {
@Autowired
private RedisTemplate<String,Object> redisTemplate;
public boolean set(String key,Object value){
try{
redisTemplate.opsForValue().set(key,value);
return true;
}catch (Exception e){
return false;
}
}
public boolean set(String key,Object value,long time){
try{
redisTemplate.opsForValue().set(key,value,time, TimeUnit.SECONDS);
return true;
}catch (Exception e){
return false;
}
}
public Object get(String key){
return key == null ? null : redisTemplate.opsForValue().get(key);
}
......
}
- 4、application.properties加入Redis相关配置
# redis
# Redis服务器地址
spring.redis.host=127.0.0.1
# Redis服务器连接端口
spring.redis.port=6379
# Redis数据库索引(默认为0)
spring.redis.database=0
# Redis服务器连接密码(默认为空)
spring.redis.password=
# 连接超时时间(毫秒)
spring.redis.timeout=10000
# 以下连接池已在SpringBoot2.0不推荐使用
#spring.redis.pool.max-active=8
#spring.redis.pool.max-wait=-1
#spring.redis.pool.max-idle=8
#spring.redis.pool.min-idle=0
# Jedis
#spring.redis.jredis.max-active=8
#spring.redis.jredis.max-wait=10000
#spring.redis.jredis.max-idle=8
#spring.redis.jredis.min-idle=0
# Lettuce
# 连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=8
# 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.lettuce.pool.max-wait=10000
# 连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=8
# 连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0
# 关闭超时时间
spring.redis.lettuce.shutdown-timeout=100
@RunWith(SpringRunner.class)
@SpringBootTest
public class ApplicationTest {
@Autowired
private RedisUtil redisUtil;
@Test
public void test() throws InterruptedException {
redisUtil.set("yibo","你好",3);
System.out.println(redisUtil.get("yibo"));
Thread.sleep(3000);
System.out.println(redisUtil.get("yibo"));
}
}
企业级缓存使用
- 定义仓储层接口PersonRepository,采用数据库和缓存实现
public interface PersonRepository {
Person getPersonById(Integer id);
}
@Component
public class PersonRepositoryImpl implements PersonRepository {
@Autowired
private PersonMapper personMapper;
public Person getPersonById(Integer id){
return personMapper.selectByPrimaryKey(id);
}
}
@Component
@Slf4j
public class PersonRepositoryCacheImpl implements PersonRepository {
private static final String CACHE_PREFIX="cache_prefix_";
@Autowired
private RedisUtil redisUtil;
@Resource(name="personRepositoryImpl")
private PersonRepository personRepository;
//这个用作缓存穿透使用
private Person nullPerson = new Person(-1);
//用随机数防止缓存雪崩
private static final Random random = new Random();
@Override
public Person getPersonById(Integer id) {
Person person = getPersonFromCache(id);
if(person == null){
log.info("cache not hit");
person = personRepository.getPersonById(id);
cachePerson(id,person);
}else if(-1 == person.getId()){
log.warn("cache hit null");
return null;
}
log.info("cache hit id");
return person;
}
private void cachePerson(Integer id,Person person){
if(person != null){
redisUtil.set(generateCacheKey(id),JSON.toJSONString(person),random.nextInt(10)+5);
}else {
redisUtil.set(generateCacheKey(id),JSON.toJSONString(nullPerson),random.nextInt(10)+5);
}
}
private Person getPersonFromCache(Integer id){
String person = (String)redisUtil.get(generateCacheKey(id));
if(StringUtils.isEmpty(person)){
return null;
}
return JSON.parseObject(person,Person.class);
}
private String generateCacheKey(Integer id){
return CACHE_PREFIX + id;
}
}
- 定义服务接口PersonService,实现服务接口api并调用仓储层
public interface PersonService {
Person getPersonById(Integer id);
}
@Service
public class PersonServiceImpl implements PersonService {
@Resource(name="personRepositoryCacheImpl")
private PersonRepository personRepository;
@Override
public Person getPersonById(Integer id) {
return personRepository.getPersonById(id);
}
}
缓存击穿
- 原因:一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,导致DB瞬间压力过大,压垮DB,就像在一个屏障上凿开了一个洞。
- 方案:热点数据缓存永不过期
缓存穿透
- 原因:恶意攻击去查数据库一定不存在的数据,对数据库造成压力,甚至压垮数据库
- 方案:使用特殊缓存空值标识对象不存在
缓存雪崩
- 原因:在某一个时间段,缓存集中过期失效,对于数据库而言,就会产生周期性的压力波峰
- 方案:设置过期时间加上随机因子,尽可能分散缓存过期时间
参考:
https://www.cnblogs.com/songwenjie/p/9027012.html
https://www.cnblogs.com/taiyonghai/p/9454764.html
https://www.cnblogs.com/jpfss/p/11016445.html
https://www.cnblogs.com/xxj-bigshow/p/10314414.html
https://blog.csdn.net/chenyao1994/article/details/79491337