前言
Apache BookKeeper 是企业级存储系统,旨在保证高持久性、一致性与低延迟。自 2011 年起,BookKeeper 开始在 Apache ZooKeeper 下作为子项目孵化,并于2015 年1 月作为顶级项目成功问世。
企业级的实时存储平台需要具备的特点:
- 以极低的延迟(小于 5 毫秒)读写 entry 流
- 能够持久、一致、容错地存储数据
- 在写数据时,能够进行流式传输或追尾传输
- 有效地存储、访问历史数据与实时数据
BookKeeper 的设计完全符合以上要求,并广泛用于多种用例:分布式系统提供高可用性或多副本,在单个集群中或多个集群间(多个数据中心)提供跨机器复制,为发布/订阅(pub-sub)消息系统提供存储服务,为流工作存储不可变对象。
一、BookKeeper 架构
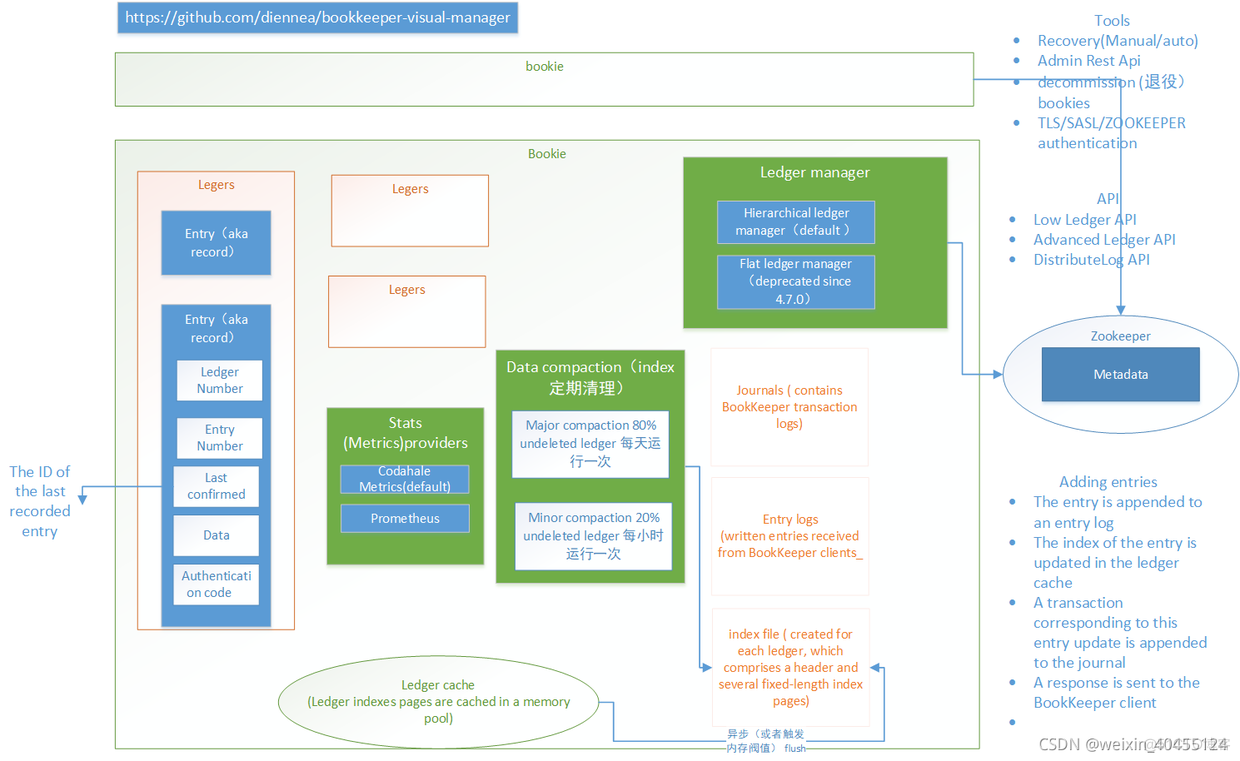
一个 BookKeeper 集群主要包括三个部分:
- Client APIs:BookKeeper 客户端,提供用于操作 BookKeeper 的 API
- Bookie cluster:由多个 bookie 节点组成,提供数据读、写和存储服务
- Metadata store:元数据存储,支持 Zookeeper 和 ETCD 两种类型,主要提供元数据存储以及服务发现功能
术语和定义
- Entry:主节点写的每一个日志对象则为一个entry
- Ledger:一个ledger由entry集合组成,每一个日志段对应一个ledger,相同日志段追加edits即为向相应的ledger追加entry
- Bookkeeper client:在HDFS中即为namenode
- Bookie:一个bookkeeper的存储服务,存储了bookkeeper的write ahead日志,及其数据(ledgers)内容
- Metadata server:由zookeeper充当bookkeeper的元数据服务器,在zk中存储了ledger相关元数据,edits元数据,及其bookie相关元数据
- Ensemble:即为bookie可用的最小的节点数量;该参数应该大于等于quorums
- Quorums:法定的bookie数量,即日志写入bk服务端的冗余分数,并且每份副本均成功才算成功,否则通过rr算法,查找下一组quorums重新写日志
- ledgerId:标志ledger的编号,该编号依次递增
- entryId:标志entry的编号,该编号依次递增,一个txid就会对应一个entryId
- entryLogId:Bookie内标志存储entry的log文件编号
- startLogSegment:开始一个新的日志段,该日志段状态为接收写入日志的状态
- finalizeLogSegment:将文件由正在写入日志的状态转化为不接收写日志的状态
- recoverUnfinalizedSegments:主从切换等情况下,恢复没有转换为finalized状态的日志
二、Bookkeeper 核心概念
BookKeeper 复制并持久存储日志流,日志流是形成良好序列的记录流。 Bookkeeper中比较核心的就两个元素:日志(ledger/stream)和记录(entry)
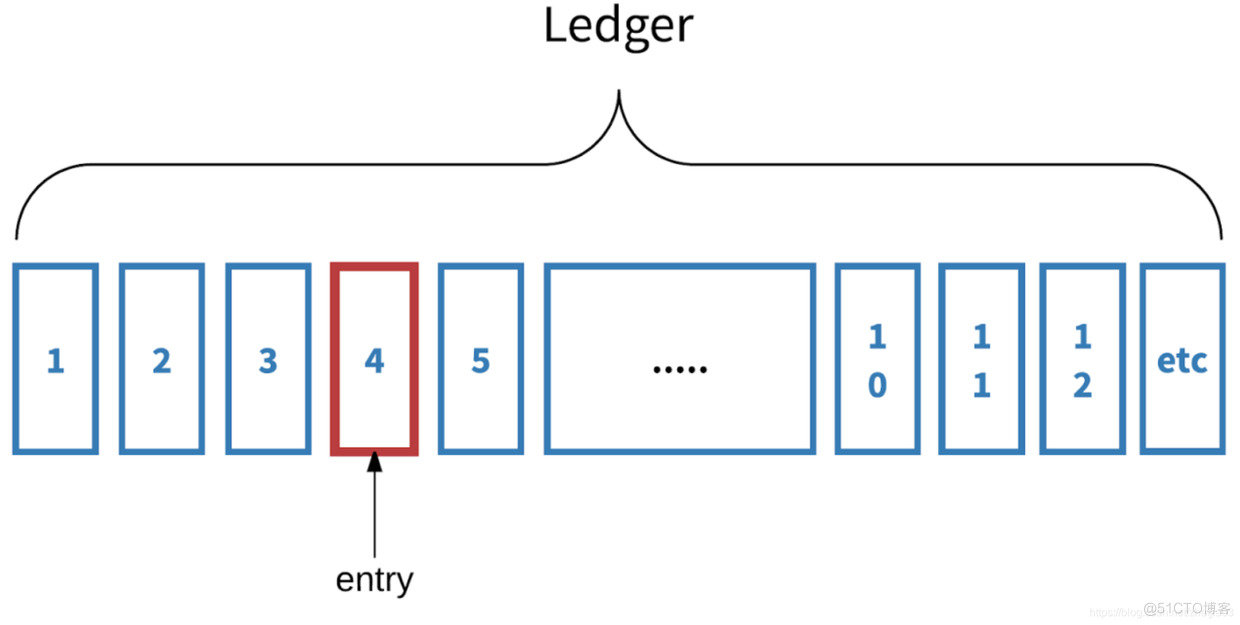
2.1 日志(ledger/stream)
BookKeeper 中提供了两个表示日志存储的名词:一个是 ledger(又称日志段);另一个是 stream(又称日志流)。
2.2 Ledger
-
用于记录或存储一系列数据记录(日志)。当客户端主动关闭或者当充当writer 的客户端宕机时,正在写入此 ledger 的记录会丢失,而之前存储在 ledger 中的数据不会丢失。Ledger 一旦被关闭就不可变,也就是说,不允许向已关闭的ledger 中添加数据记录(日志)。
-
Ledger 是 Entry 的序列
-
Entry 以 append-only 的方式被添加到 leger 中
-
一个 Ledger 同时只能有一个 writer,但是可以有多个 Reader
-
关闭之后不可改变
Ledger 元数据
- 状态信息:标识 ledger 状态
- Last Entry Id:标识 ledger 中的最后一个 Entry 的 Id
- 持久化配置:ensemble size、write quorum、ack quorum
- ensemble 列表:标识 Ledger 数据存储的 Bookie 节点信息
2.3 记录(entry)
-
数据以不可分割记录的序列,而不是单个字节写入 Apache BookKeeper 的日志。记录是BookKeeper中最小的I/O 单元,也被称作地址单元。单条记录中包含与该记录相关或分配给该记录的序列号(例如递增的长数)。
-
客户端总是从特定记录开始读取,或者追尾序列。也就是说,客户端通过监听序列来寻找下一条要添加到日志中的记录。客户端可以单次接收单条记录,也可以接收包含多条记录的数据块。序列号也可以用于随机检索记录。
Entry 是 BookKeeper 的数据实体,Entry 除了包含写入 bookie 的实际数据之外,还包含一些元数据信息。
字段 说明 类型 Ledger ID Entry 写入的 ledger ID long Entry ID Entry 的唯一 ID long Last confirmed (LC) 最后记录的 Entry ID long Digest CRC 校验 -- Data 数据 byte[]Pulsar 通过操作 Ledger 来完成数据的读写
- Broker 接收到 Producer 生产的消息之后,会对应的封装一个 Entry,然后写入 Bookie,每个 Entry 都会有一个唯一的 <LedgerId, EntryId>
- Broker 通过 <LedgerId, EntryId> 来从 Bookie 读取一个 Entry,然后解析出数据推送给 消费者
Ensemble/write quorum/ack quorum Pulsar 打开一个 Ledger 时, 需要指定三个持久化配置参数,
openLedger(ensemble size, write quorum , ack quorum ) // openLedger(5,3,2)- ensemble size:在初始化 Ledger 时, 首先要选取一个 Bookie 集合作为写入节点,ensemble 表示这个集合中的节点数目
- write quorum:数据备份数目
- ack quorum:响应节点数目
2.4 Stream(又称日志流)
- 是无界、无限的数据记录序列。默认情况下,stream 永远不会丢失。stream 和ledger有所不同。在追加记录时,ledger 只能运行一次,而 stream 可以运行多次。
一个 stream 由多个 ledger 组成;每个 ledger 根据基于时间或空间的滚动策略循环。在stream 被删除之前,stream 有可能存在相对较长的时间(几天、几个月,甚至几年)。Stream 的主要数据保留机制是截断,包括根据基于时间或空间的保留策略删除最早的 ledger。
Ledger 和 stream 为历史数据和实时数据提供统一的存储抽象。在写入数据时,日志流流式传输或追尾传输实时数据记录。存储在 ledger 的实时数据成为历史数据。累积在 stream 中的数据不受单机容量的限制。
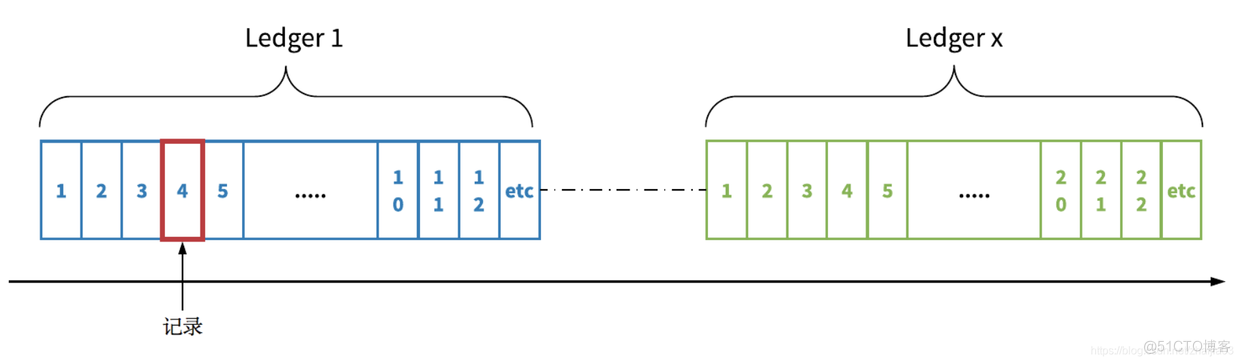
2.5 命名空间
-
通常情况下,用户在命名空间分类、管理日志流。命名空间是租户用来创建 stream 的一种机制,也是一个部署或管理单元。用户可以配置命名空间级别的数据放置策略。
-
同一命名空间的所有 stream 都拥有相同的命名空间的设置,并将记录存放在根据数据放置策略配置的存储节点中。这为同时管理多个 stream 的机制提供了强有力的支持。
2.6 Bookies
- Bookies 即存储服务器。一个 bookie 是一个单独的 BookKeeper 存储服务器,用于存储数据记录。BookKeeper跨 bookies 复制并存储数据 entries。出于性能考虑,单个 bookie 上存储 ledger 段,而不是整个ledger。因此,bookie 就像是整个集成的一部分。对于任意给定 ledger L,集成指存储L 中entries 的一组bookies。将 entries 写入 ledger 时,entries 就会跨集成分段(写入 bookies 的一个分组而不是所有的bookies)。
2.7 元数据
- BookKeeper 需要元数据存储服务,用来存储 ledger 与可用 bookie 的相关信息。目前,BookKeeper利用ZooKeeper 来完成这项工作(除了数据存储服务外,还包括一些协调、配置管理任务等)。
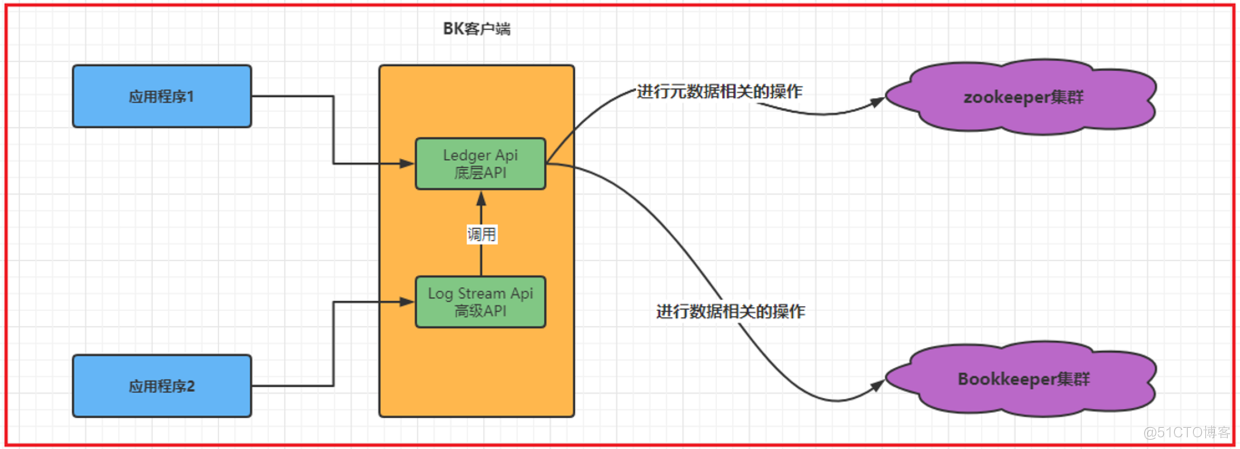
2.8 与 BookKeeper 交互
与 bookie 交互时,BookKeeper 应用程序有两个主要作用:一个是创建 ledger 或 stream 以便写入数据;另一个是打开 ledger 或 stream 以便读取数据。为了与 BookKeeper 中两个不同的存储原语交互,BookKeeper 提供了两个 API。
- Ledger API、较低级别的 API,允许用户直接与 ledger 交互,极具灵活性,用户可根据需要与 bookie 交互。
- Stream API:较高级别、面向流的 API,通过 Apache DistributedLog 实现。用户无需管理与 ledger 交互的复杂性,就可以与 stream 交互。
选择使用哪个 API 取决于用户对 ledger 语义设定的的粒度控制程度。 用户也可以在单个应用程序中同时使用这两个 API。
2.9 放在一起看
下图即为 BookKeeper 的典型安装示例。
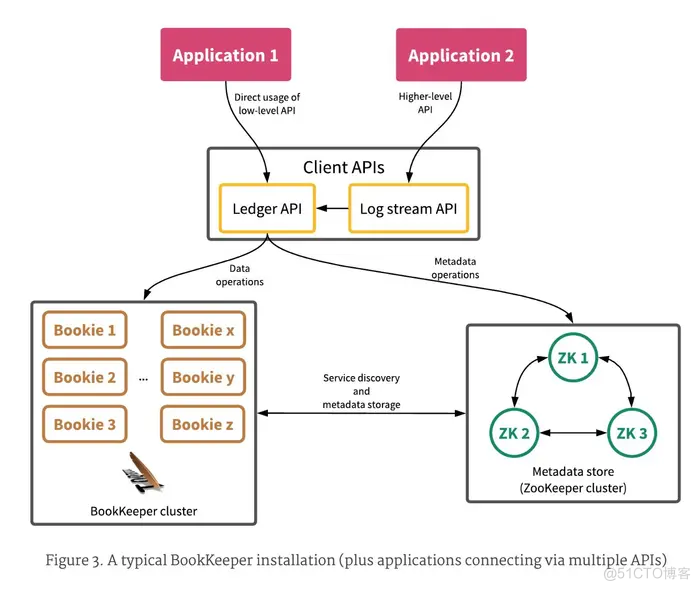
上图中的几个注意事项
- 1、典型的 BookKeeper 安装包括元数据存储区(如 ZooKeeper)、bookie 集群,以及通过提供的客户端库与 bookie 交互的多个客户端。
- 2、为便于客户端的识别,bookie 会将自己广播到元数据存储区。
- 3、Bookie 会与元数据存储区交互,作为回收站收集已删除数据。
- 4、应用程序通过提供的客户端库与 BookKeeper 交互(使用 ledger API 或 DistributedLog Stream API)
- A、应用程序 1 需要对 ledger 进行粒度控制,以便直接使用 ledger API。
- B、应用程序 2 不需要较低级别 ledger 控制,因此使用更加简化的日志流 API。
Bookkeeper的元数据存储 ----metadata store,目前是由zookeeper进行,用于存储leader ID对应的元数据信息
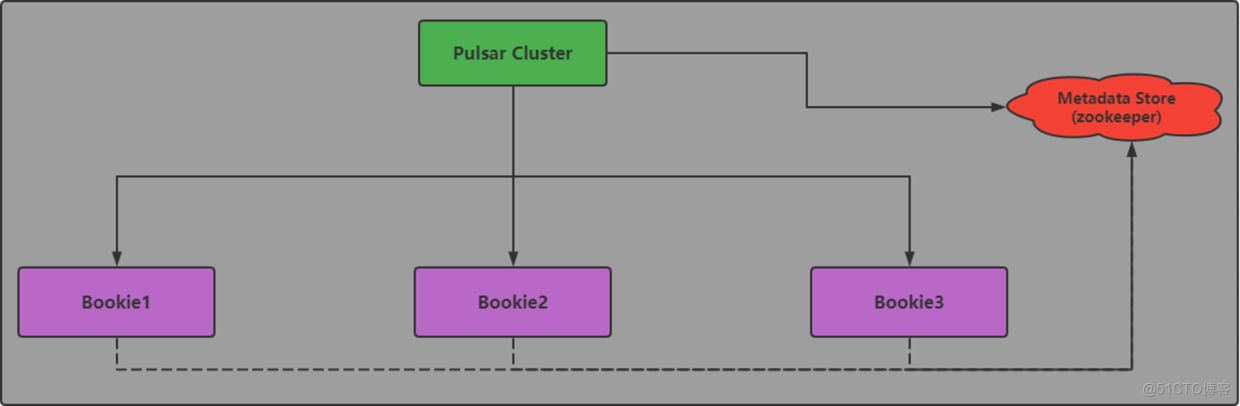
而集群中的 bookie 用来存储这些 ledger 对应的 entry,所有的 bookie 会注册到BookKeeper 上,由客户端去发现并采取相应的操作。BookKeeper 的客户端主要是实现一些与一致性、策略性相关的逻辑。
三、整体架构
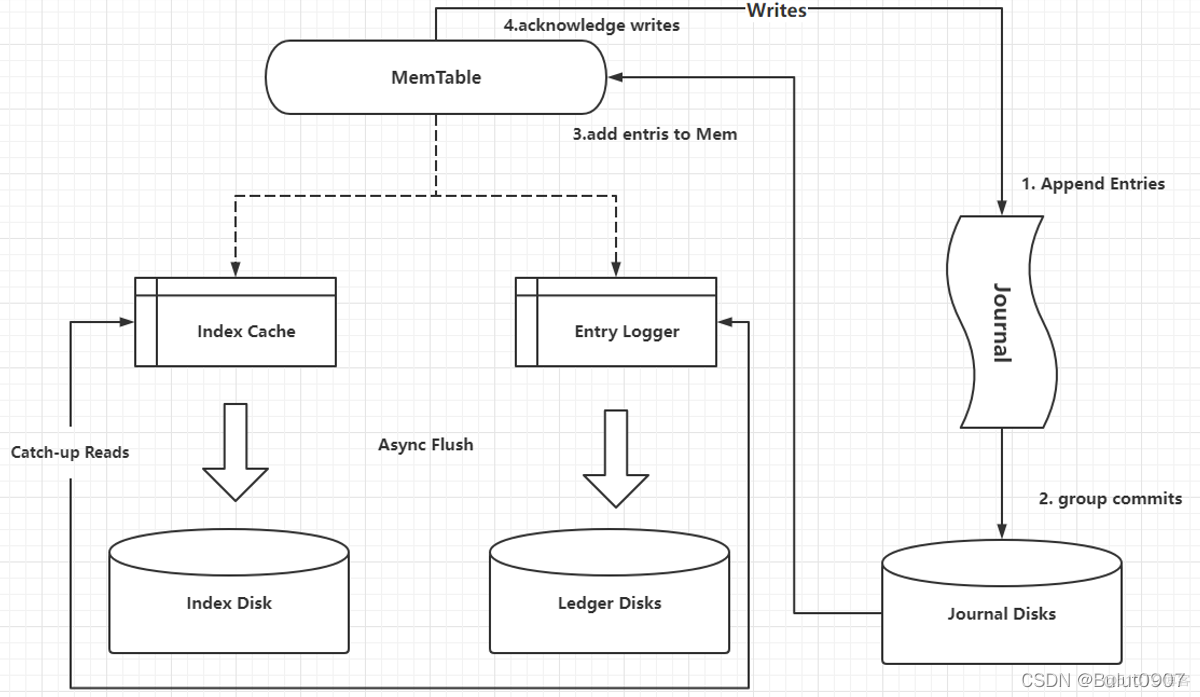
- Bookie 的实现,依靠 journal(类似于WAL预写日志) 和 ledger storage,Bookie 利用 journal 进行所有写的操作。在追加多条 entry(来自不同的 ledger)的过程中,journal都在发挥着它的持久化作用。这样做的优点是不管 ledger 来自何处,Bookie 只负责按顺序将entry写到journal文件里,不会进行随机访问。
- 当一个 journal 文件写满后,Bookie 会自动开启一个新的 journal 文件,继续按顺序填补 entry 。
- 但问题是,用户无法在 journal 里查询某条 entry。所以如果应用到读请求时,就需要「索引」功能来达到更高效的过程。
- 为了让各组件独立完成任务,没有在 journal 上建立索引功能,而是在 bookie 端维持了一个「write cache」,在内存里进行一个写缓存。在 journal 里运行结束后,会放置到write cache 里。
- 经过 write cache 过程后,Bookie对 entry 进行重新排序,按 ledger 的来源划分整理entry,以便确保在缓存变满的过程中,entry 可以按照 ledger 的顺序排队。
- 当缓存变满后,bookie 会把整个 write cache 冲到磁盘里。Flush 的过程又重新整理了几个目录,用来保留相关的映射关系。一个是 entry log,用来存储value。同时维护另一个ledger index,用来记录 entry id 的位置。
- 默认的 ledger storage 有两类:DB ledger storage 和 Sorted ledger storage。本质上,这两类ledger storage的实现途径是一样的,只是在处理索引存储时不太一样。
想要了解更多关于 Apache BookKeeper 项目的信息,请访问官方网站:http://bookkeeper.apache.org。
参考: https://blog.csdn.net/yy8623977/article/details/124114456
https://blog.csdn.net/weixin_42529806/article/details/90649404
https://zhuanlan.zhihu.com/p/459213737
https://blog.csdn.net/zhaijia03/article/details/107253634/