目录
- 进程
- 线程
- 内核态线程
- 用户态线程
- 轻量级进程(LWP)
- 小结
- 协程
- I/O 模型
- 阻塞 I/O
- 非阻塞 I/O
- 同(异)步 I/O
- Node.js 的并发模型
- 总结
前言:
Node.js 现在已成为构建高并发网络应用服务工具箱中的一员,何以 Node.js 会成为大众的宠儿?本文将从进程、线程、协程、I/O 模型这些基本概念说起,为大家全面介绍关于 Node.js 与并发模型的这些事。
进程
我们一般将某个程序正在运行的实例称之为进程,它是操作系统进行资源分配和调度的一个基本单元,一般包含以下几个部分:
- 程序:即要执行的代码,用于描述进程要完成的功能;
- 数据区域:进程处理的数据空间,包括数据、动态分配的内存、处理函数的用户栈、可修改的程序等信息;
- 进程表项:为了实现进程模型,操作系统维护着一张称为
进程表的表格,每个进程占用一个进程表项(也叫进程控制块),该表项包含了程序计数器、堆栈指针、内存分配情况、所打开文件的状态、调度信息等重要的进程状态信息,从而保证进程挂起后,操作系统能够正确地重新唤起该进程。
进程具有以下特征:
- 动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的;
- 并发性:任何进程都可以同其他进程一起并发执行;
- 独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;
- 异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进。
需要注意的是,如果一个程序运行了两遍,即便操作系统能够使它们共享代码(即只有一份代码副本在内存中),也不能改变正在运行的程序的两个实例是两个不同的进程的事实。
在进程的执行过程中,由于中断、CPU 调度等各种原因,进程会在下面几个状态中切换:
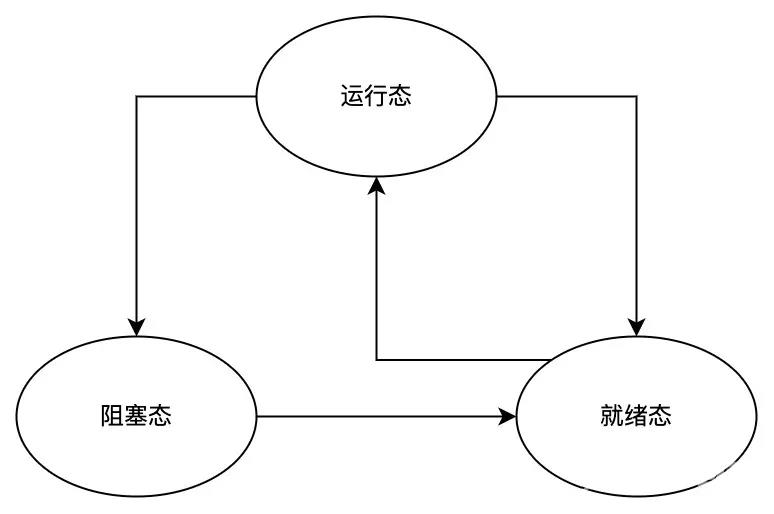
- 运行态:此刻进程正在运行,并占用了 CPU;
- 就绪态:此刻进程已准备就绪,随时可以运行,但因为其它进程正在运行而被暂时停止;
- 阻塞态:此刻进程处于阻塞状态,除非某个外部事件(比如键盘输入的数据已到达)发生,否则进程将不能运行。
通过上面的进程状态切换图可知,进程可以从运行态切换成就绪态和阻塞态,但只有就绪态才能直接切换成运行态,这是因为:
- 从运行态切换成就绪态是由进程调度程序引起的,因为系统认为当前进程已经占用了过多的 CPU 时间,决定让其它进程使用 CPU 时间;并且进程调度程序是操作系统的一部分,进程甚至感觉不到调度程序的存在;
- 从运行态切换成阻塞态是由进程自身原因(比如等待用户的键盘输入)导致进程无法继续执行,只能挂起等待某个事件(比如键盘输入的数据已到达)发生;当相关事件发生时,进程先转换为就绪态,如果此时没有其它进程运行,则立刻转换为运行态,否则进程将维持就绪态,等待进程调度程序的调度。
线程
有些时候,我们需要使用线程来解决以下问题:
- 随着进程数量的增加,进程之间切换的成本将越来越大,CPU 的有效使用率也会越来越低,严重情况下可能造成系统假死等现象;
- 每个进程都有自己独立的内存空间,且各个进程之间的内存空间是相互隔离的,而某些任务之间可能需要共享一些数据,多个进程之间的数据同步就过于繁琐。
关于线程,我们需要知道以下几点:
- 线程是程序执行中的一个单一顺序控制流,是操作系统能够进行运算调度的最小单位,它包含在进程之中,是进程中的实际运行单位;
- 一个进程中可以包含多个线程,每个线程并行执行不同的任务;
- 一个进程中的所有线程共享进程的内存空间(包括代码、数据、堆等)以及一些资源信息(比如打开的文件和系统信号);
- 一个进程中的线程在其它进程中不可见。
了解了线程的基本特征,下面我们来聊一下常见的几种线程类型。
内核态线程
内核态线程是直接由操作系统支持的线程,其主要特点如下:
- 线程的创建、调度、同步、销毁由系统内核完成,但其开销较为昂贵;
- 内核可将内核态线程映射到各个处理器上,能够轻松做到一个处理器核心对应一个内核线程,从而充分地竞争与利用 CPU 资源;
- 仅能访问内核的代码和数据;
- 资源同步与数据共享效率低于进程的资源同步与数据共享效率。
用户态线程
用户态线程是完全建立在用户空间的线程,其主要特点如下:
- 线程的创建、调度、同步、销毁由用户空间完成,其开销非常低;
- 由于用户态线程由用户空间维护,内核根本感知不到用户态线程的存在,因此内核仅对其所属的进程做调度及资源分配,而进程中线程的调度及资源分配由程序自行处理,这很可能造成一个用户态线程被阻塞在系统调用中,则整个进程都将会阻塞的风险;
- 能够访问所属进程的所有共享地址空间和系统资源;
- 资源同步与数据共享效率较高。
轻量级进程(LWP)
轻量级进程(LWP)是建立在内核之上并由内核支持的用户线程,其主要特点如下:
- 用户空间只能通过轻量级进程(LWP)来使用内核线程,可看作是用户态线程与内核线程的桥接器,因此只有先支持内核线程,才能有轻量级进程(LWP);
- 大多数轻量级进程(LWP)的操作,都需要用户态空间发起系统调用,此系统调用的代价相对较高(需要在用户态与内核态之间进行切换);
- 每个轻量级进程(LWP)都需要与一个特定的内核线程关联,因此:
- 与内核线程一样,可在全系统范围内充分地竞争与利用 CPU 资源;
- 每个轻量级进程(LWP)都是一个独立的线程调度单元,这样即使有一个轻量级进程(LWP)在系统调用中被阻塞,也不影响整个进程的执行;
- 轻量级进程(LWP)需要消耗内核资源(主要指内核线程的栈空间),这样导致系统中不可能支持大量的轻量级进程(LWP);
- 能够访问所属进程的所有共享地址空间和系统资源。
小结
上文我们对常见的线程类型(内核态线程、用户态线程、轻量级进程)进行了简单介绍,它们各自有各自的适用范围,在实际的使用中可根据自己的需要自由地对其进行组合使用,比如常见的一对一、多对一、多对多等模型,由于篇幅限制,本文对此不做过多介绍,感兴趣的同学可自行研究。
协程
协程(Coroutine),也叫纤程(Fiber),是一种建立在线程之上,由开发者自行管理执行调度、状态维护等行为的一种程序运行机制,其特点主要有:
- 因执行调度无需上下文切换,故具有良好的执行效率;
- 因运行在同一线程,故不存在线程通信中的同步问题;
- 方便切换控制流,简化编程模型。
在 JavaScript 中,我们经常用到的 async/await 便是协程的一种实现,
比如下面的例子:
function updateUserName(id, name) {
const user = getUserById(id);
user.updateName(name);
return true;
}
async function updateUserNameAsync(id, name) {
const user = await getUserById(id);
await user.updateName(name);
return true;
}
上例中,函数 updateUserName 和 updateUserNameAsync 内的逻辑执行顺序是:
- 调用函数
getUserById并将其返回值赋给变量user; - 调用
user的updateName方法; - 返回
true给调用者。
两者的主要区别在于其实际运行过程中的状态控制:
- 在函数
updateUserName的执行过程中,按照前文所述的逻辑顺序依次执行; - 在函数
updateUserNameAsync的执行过程中,同样按照前文所述的逻辑顺序依次执行,只不过在遇到await时,updateUserNameAsync将会被挂起并保存挂起位置当前的程序状态,直到await后面的程序片段返回后,才会再次唤醒updateUserNameAsync并恢复挂起前的程序状态,然后继续执行下一段程序。
通过上面的分析我们可以大胆猜测:协程要解决的并非是进程、线程要解决的程序并发问题,而是要解决处理异步任务时所遇到的问题(比如文件操作、网络请求等);在 async/await 之前,我们只能通过回调函数来处理异步任务,这很容易使我们陷入回调地狱,生产出一坨坨屎一般难以维护的代码,通过协程,我们便可以实现异步代码同步化的目的。
需要牢记的是:协程的核心能力是能够将某段程序挂起并维护程序挂起位置的状态,并在未来某个时刻在挂起的位置恢复,并继续执行挂起位置后的下一段程序。
I/O 模型
一个完整的 I/O 操作需要经历以下阶段:
- 用户进(线)程通过系统调用向内核发起
I/O操作请求; - 内核对
I/O操作请求进行处理(分为准备阶段和实际执行阶段),并将处理结果返回给用户进(线)程。
我们可将 I/O 操作大致分为阻塞 I/O、非阻塞 I/O、同步 I/O、异步 I/O 四种类型,在讨论这些类型之前,我们先熟悉下以下两组概念(此处假设服务 A 调用了服务 B):
阻塞/非阻塞:
- 如果 A 只有在接收到 B 的响应之后才返回,那么该调用为
阻塞调用; - 如果 A 调用 B 后立即返回(即无需等待 B 执行完毕),那么该调用为
非阻塞调用。
同步/异步:
- 如果 B 只有在执行完之后再通知 A,那么服务 B 是
同步的; - 如果 A 调用 B 后,B 立刻给 A 一个请求已接收的通知,然后在执行完之后通过
回调的方式将执行结果通知给 A,那么服务 B 就是异步的。
很多人经常将阻塞/非阻塞与同步/异步搞混淆,故需要特别注意:
阻塞/非阻塞针对于服务的调用者而言;同步/异步针对于服务的被调用者而言。
了解了阻塞/非阻塞与同步/异步,我们来看具体的 I/O 模型。
阻塞 I/O
定义:用户进(线)程发起 I/O 系统调用后,用户进(线)程会被立即阻塞,直到整个 I/O 操作处理完毕并将结果返回给用户进(线)程后,用户进(线)程才能解除阻塞状态,继续执行后续操作。
特点:
- 由于该模型会阻塞用户进(线)程,因此该模型不占用 CPU 资源;
- 在执行
I/O操作的时候,用户进(线)程不能进行其它操作; - 该模型仅适用于并发量小的应用,这是因为一个
I/O请求就能阻塞进(线)程,所以为了能够及时响应I/O请求,需要为每个请求分配一个进(线)程,这样会造成巨大的资源占用,并且对于长连接请求来说,由于进(线)程资源长期得不到释放,如果后续有新的请求,将会产生严重的性能瓶颈。
非阻塞 I/O
定义:
- 用户进(线)程发起
I/O系统调用后,如果该I/O操作未准备就绪,该I/O调用将会返回一个错误,用户进(线)程也无需等待,而是通过轮询的方式来检测该I/O操作是否就绪; - 操作就绪后,实际的
I/O操作会阻塞用户进(线)程直到执行结果返回给用户进(线)程。
特点:
- 由于该模型需要用户进(线)程不断地询问
I/O操作就绪状态(一般使用while循环),因此该模型需占用 CPU,消耗 CPU 资源; - 在
I/O操作就绪前,用户进(线)程不会阻塞,等到I/O操作就绪后,后续实际的I/O操作将阻塞用户进(线)程; - 该模型仅适用于并发量小,且不需要及时响应的应用。
同(异)步 I/O
用户进(线)程发起 I/O 系统调用后,如果该 I/O 调用会导致用户进(线)程阻塞,那么该 I/O 调用便为同步 I/O,否则为 异步 I/O。
判断 I/O 操作同步或异步的标准是用户进(线)程与 I/O 操作的通信机制,其中:
同步情况下用户进(线)程与I/O的交互是通过内核缓冲区进行同步的,即内核会将I/O操作的执行结果同步到缓冲区,然后再将缓冲区的数据复制到用户进(线)程,这个过程会阻塞用户进(线)程,直到I/O操作完成;异步情况下用户进(线)程与I/O的交互是直接通过内核进行同步的,即内核会直接将I/O操作的执行结果复制到用户进(线)程,这个过程不会阻塞用户进(线)程。
Node.js 的并发模型
Node.js 采用的是单线程、基于事件驱动的异步 I/O 模型,个人认为之所以选择该模型的原因在于:
- JavaScript 在 V8 下以单线程模式运行,为其实现多线程极其困难;
- 绝大多数网络应用都是
I/O密集型的,在保证高并发的情况下,如何合理、高效地管理多线程资源相对于单线程资源的管理更加复杂。
总之,本着简单、高效的目的,Node.js 采用了单线程、基于事件驱动的异步 I/O 模型,并通过主线程的 EventLoop 和辅助的 Worker 线程来实现其模型:
- Node.js 进程启动后,Node.js 主线程会创建一个 EventLoop,EventLoop 的主要作用是注册事件的回调函数并在未来的某个事件循环中执行;
- Worker 线程用来执行具体的事件任务(在主线程之外的其它线程中以同步方式执行),然后将执行结果返回到主线程的 EventLoop 中,以便 EventLoop 执行相关事件的回调函数。
需要注意的是,Node.js 并不适合执行 CPU 密集型(即需要大量计算)任务;这是因为 EventLoop 与 JavaScript 代码(非异步事件任务代码)运行在同一线程(即主线程),它们中任何一个如果运行时间过长,都可能导致主线程阻塞,如果应用程序中包含大量需要长时间执行的任务,将会降低服务器的吞吐量,甚至可能导致服务器无法响应。
总结
Node.js 是前端开发人员现在乃至未来不得不面对的技术,然而大多数前端开发人员对 Node.js 的认知仅停留在表面,为了让大家更好地理解 Node.js 的并发模型,本文先介绍了进程、线程、协程,接着介绍了不同的 I/O 模型,最后对 Node.js 的并发模型进行了简单介绍。虽然介绍 Node.js 并发模型的篇幅不多,但笔者相信万变不离其宗,掌握了相关基础,再深入理解 Node.js 的设计与实现必将事半功倍。
到此这篇关于Node.js 与并发模型的详细介绍的文章就介绍到这了,更多相关Node.js 并发模型内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!