目录
- 背景
- 响应式实现原理
- 依赖收集
- 派发通知
- 副作用函数
- 响应式实现的优化
- 依赖收集的优化
- 响应式 API 的优化
- trackOpBit 的设计
- 总结
背景
Vue 3 正式发布距今已经快一年了,相信很多小伙伴已经在生产环境用上了 Vue 3 了。如今,Vue.js 3.2 已经正式发布,而这次 minor 版本的升级主要体现在源码层级的优化,对于用户的使用层面来说其实变化并不大。其中一个吸引我的点是提升了响应式的性能:
More efficient ref implementation (~260% faster read / ~50% faster write)
~40% faster dependency tracking
~17% less memory usage
翻译过来就是 ref API 的读效率提升约为 260%,写效率提升约为 50% ,依赖收集的效率提升约为 40%,同时还减少了约 17% 的内存使用。
这简直就是一个吊炸天的优化啊,因为要知道响应式系统是 Vue.js 的核心实现之一,对它的优化就意味着对所有使用 Vue.js 开发的 App 的性能优化。
而且这个优化并不是 Vue 官方人员实现的,而是社区一位大佬 @basvanmeurs 提出的,相关的优化代码在 2020 年 10 月 9 号就已经提交了,但由于对内部的实现改动较大,官方一直等到了 Vue.js 3.2 发布,才把代码合入。
这次 basvanmeurs 提出的响应式性能优化真的让尤大喜出望外,不仅仅是大大提升了 Vue 3 的运行时性能,还因为这么核心的代码能来自社区的贡献,这就意味着 Vue 3 受到越来越多的人关注;一些能力强的开发人员参与到核心代码的贡献,可以让 Vue 3 走的更远更好。
我们知道,相比于 Vue 2,Vue 3 做了多方面的优化,其中一部分是数据响应式的实现由 Object.defineProperty API 改成了 Proxy API。
当初 Vue 3 在宣传的时候,官方宣称在响应式的实现性能上做了优化,那么优化体现在哪些方面呢?有部分小伙伴认为是 Proxy API 的性能要优于 Object.defineProperty 的,其实不然,实际上 Proxy 在性能上是要比 Object.defineProperty 差的,详情可以参考 Thoughts on ES6 Proxies Performance 这篇文章,而我也对此做了测试,结论同上,可以参考这个 repo。
既然 Proxy 慢,为啥 Vue 3 还是选择了它来实现数据响应式呢?因为 Proxy 本质上是对某个对象的劫持,这样它不仅仅可以监听对象某个属性值的变化,还可以监听对象属性的新增和删除;而 Object.defineProperty 是给对象的某个已存在的属性添加对应的 getter 和 setter,所以它只能监听这个属性值的变化,而不能去监听对象属性的新增和删除。
而响应式在性能方面的优化其实是体现在把嵌套层级较深的对象变成响应式的场景。在 Vue 2 的实现中,在组件初始化阶段把数据变成响应式时,遇到子属性仍然是对象的情况,会递归执行 Object.defineProperty 定义子对象的响应式;而在 Vue 3 的实现中,只有在对象属性被访问的时候才会判断子属性的类型来决定要不要递归执行 reactive,这其实是一种延时定义子对象响应式的实现,在性能上会有一定的提升。
因此,相比于 Vue 2,Vue 3 确实在响应式实现部分做了一定的优化,但实际上效果是有限的。而 Vue.js 3.2 这次在响应式性能方面的优化,是真的做到了质的飞跃,接下来我们就来上点硬菜,从源码层面分析具体做了哪些优化,以及这些优化背后带来的技术层面的思考。
响应式实现原理
所谓响应式,就是当我们修改数据后,可以自动做某些事情;对应到组件的渲染,就是修改数据后,能自动触发组件的重新渲染。
Vue 3 实现响应式,本质上是通过 Proxy API 劫持了数据对象的读写,当我们访问数据时,会触发 getter 执行依赖收集;修改数据时,会触发 setter 派发通知。
接下来,我们简单分析一下依赖收集和派发通知的实现(Vue.js 3.2 之前的版本)。
依赖收集
首先来看依赖收集的过程,核心就是在访问响应式数据的时候,触发 getter 函数,进而执行 track 函数收集依赖:
let shouldTrack = true
// 当前激活的 effect
let activeEffect
// 原始数据对象 map
const targetMap = new WeakMap()
function track(target, type, key) {
if (!shouldTrack || activeEffect === undefined) {
return
}
let depsMap = targetMap.get(target)
if (!depsMap) {
// 每个 target 对应一个 depsMap
targetMap.set(target, (depsMap = new Map()))
}
let dep = depsMap.get(key)
if (!dep) {
// 每个 key 对应一个 dep 集合
depsMap.set(key, (dep = new Set()))
}
if (!dep.has(activeEffect)) {
// 收集当前激活的 effect 作为依赖
dep.add(activeEffect)
// 当前激活的 effect 收集 dep 集合作为依赖
activeEffect.deps.push(dep)
}
}
分析这个函数的实现前,我们先想一下要收集的依赖是什么,我们的目的是实现响应式,就是当数据变化的时候可以自动做一些事情,比如执行某些函数,所以我们收集的依赖就是数据变化后执行的副作用函数。
track 函数拥有三个参数,其中 target 表示原始数据;type 表示这次依赖收集的类型;key 表示访问的属性。
track 函数外部创建了全局的 targetMap 作为原始数据对象的 Map,它的键是 target,值是 depsMap,作为依赖的 Map;这个 depsMap 的键是 target 的 key,值是 dep 集合,dep 集合中存储的是依赖的副作用函数。为了方便理解,可以通过下图表示它们之间的关系:
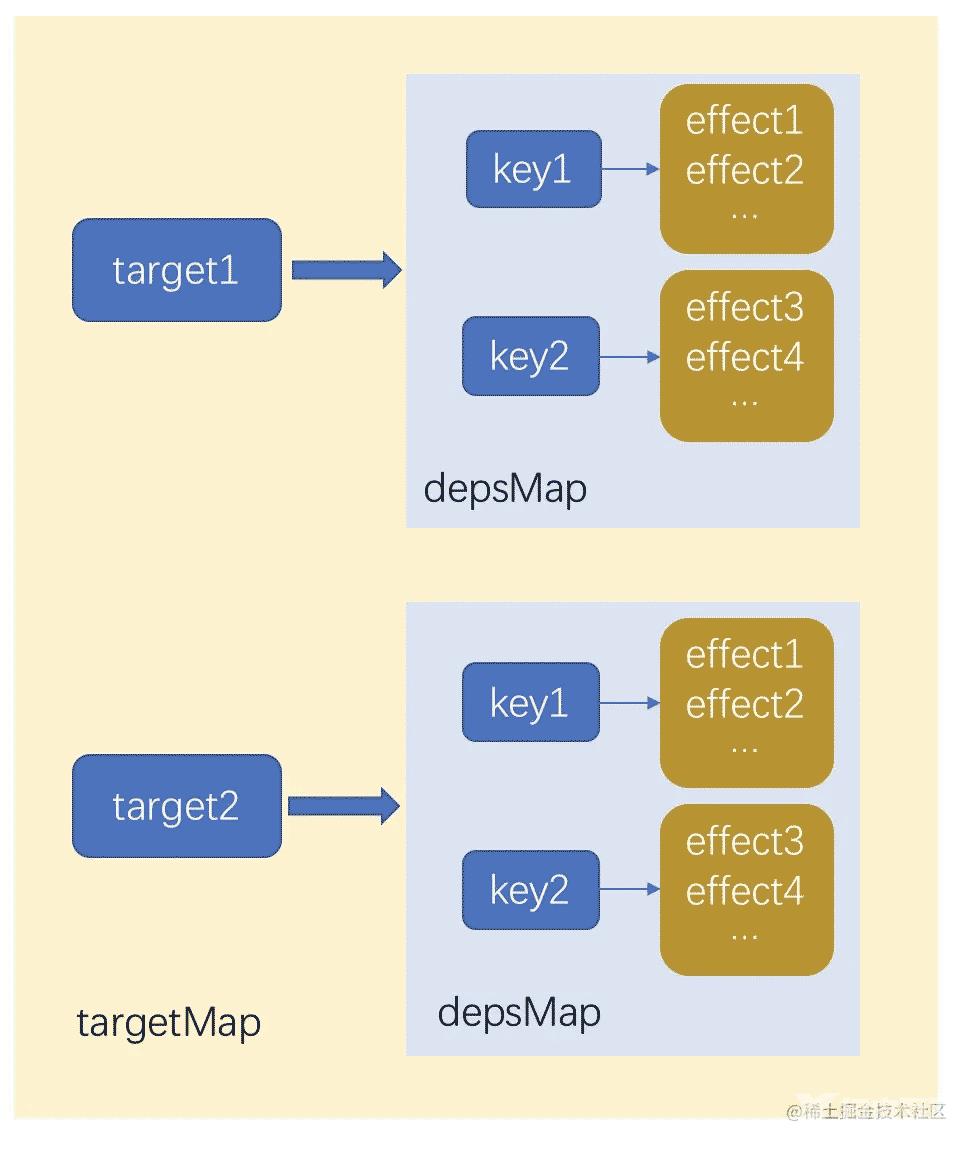
因此每次执行 track 函数,就是把当前激活的副作用函数 activeEffect 作为依赖,然后收集到 target 相关的 depsMap 对应 key 下的依赖集合 dep 中。
派发通知
派发通知发生在数据更新的阶段,核心就是在修改响应式数据时,触发 setter 函数,进而执行 trigger 函数派发通知:
const targetMap = new WeakMap()
function trigger(target, type, key) {
// 通过 targetMap 拿到 target 对应的依赖集合
const depsMap = targetMap.get(target)
if (!depsMap) {
// 没有依赖,直接返回
return
}
// 创建运行的 effects 集合
const effects = new Set()
// 添加 effects 的函数
const add = (effectsToAdd) => {
if (effectsToAdd) {
effectsToAdd.forEach(effect => {
effects.add(effect)
})
}
}
// SET | ADD | DELETE 操作之一,添加对应的 effects
if (key !== void 0) {
add(depsMap.get(key))
}
const run = (effect) => {
// 调度执行
if (effect.options.scheduler) {
effect.options.scheduler(effect)
}
else {
// 直接运行
effect()
}
}
// 遍历执行 effects
effects.forEach(run)
}
trigger 函数拥有三个参数,其中 target 表示目标原始对象;type 表示更新的类型;key 表示要修改的属性。
trigger 函数 主要做了四件事情:
- 从
targetMap中拿到target对应的依赖集合depsMap; - 创建运行的
effects集合; - 根据
key从depsMap中找到对应的effect添加到effects集合; - 遍历
effects执行相关的副作用函数。
因此每次执行 trigger 函数,就是根据 target 和 key,从 targetMap 中找到相关的所有副作用函数遍历执行一遍。
在描述依赖收集和派发通知的过程中,我们都提到了一个词:副作用函数,依赖收集过程中我们把 activeEffect(当前激活副作用函数)作为依赖收集,它又是什么?接下来我们来看一下副作用函数的庐山真面目。
副作用函数
那么,什么是副作用函数,在介绍它之前,我们先回顾一下响应式的原始需求,即我们修改了数据就能自动做某些事情,举个简单的例子:
import { reactive } from 'vue'
const counter = reactive({
num: 0
})
function logCount() {
console.log(counter.num)
}
function count() {
counter.num++
}
logCount()
count()
我们定义了响应式对象 counter,然后在 logCount 中访问了 counter.num,我们希望在执行 count 函数修改 counter.num 值的时候,能自动执行 logCount 函数。
按我们之前对依赖收集过程的分析,如果logCount 是 activeEffect 的话,那么就可以实现需求,但显然是做不到的,因为代码在执行到 console.log(counter.num) 这一行的时候,它对自己在 logCount 函数中的运行是一无所知的。
那么该怎么办呢?其实只要我们运行 logCount 函数前,把 logCount 赋值给 activeEffect 就好了:
activeEffect = logCount logCount()
顺着这个思路,我们可以利用高阶函数的思想,对 logCount 做一层封装:
function wrapper(fn) {
const wrapped = function(...args) {
activeEffect = fn
fn(...args)
}
return wrapped
}
const wrappedLog = wrapper(logCount)
wrappedLog()
wrapper 本身也是一个函数,它接受 fn 作为参数,返回一个新的函数 wrapped,然后维护一个全局变量 activeEffect,当 wrapped 执行的时候,把 activeEffect 设置为 fn,然后执行 fn 即可。
这样当我们执行 wrappedLog 后,再去修改 counter.num,就会自动执行 logCount 函数了。
实际上 Vue 3 就是采用类似的做法,在它内部就有一个 effect 副作用函数,我们来看一下它的实现:
// 全局 effect 栈
const effectStack = []
// 当前激活的 effect
let activeEffect
function effect(fn, options = EMPTY_OBJ) {
if (isEffect(fn)) {
// 如果 fn 已经是一个 effect 函数了,则指向原始函数
fn = fn.raw
}
// 创建一个 wrapper,它是一个响应式的副作用的函数
const effect = createReactiveEffect(fn, options)
if (!options.lazy) {
// lazy 配置,计算属性会用到,非 lazy 则直接执行一次
effect()
}
return effect
}
function createReactiveEffect(fn, options) {
const effect = function reactiveEffect() {
if (!effect.active) {
// 非激活状态,则判断如果非调度执行,则直接执行原始函数。
return options.scheduler ? undefined : fn()
}
if (!effectStack.includes(effect)) {
// 清空 effect 引用的依赖
cleanup(effect)
try {
// 开启全局 shouldTrack,允许依赖收集
enableTracking()
// 压栈
effectStack.push(effect)
activeEffect = effect
// 执行原始函数
return fn()
}
finally {
// 出栈
effectStack.pop()
// 恢复 shouldTrack 开启之前的状态
resetTracking()
// 指向栈最后一个 effect
activeEffect = effectStack[effectStack.length - 1]
}
}
}
effect.id = uid++
// 标识是一个 effect 函数
effect._isEffect = true
// effect 自身的状态
effect.active = true
// 包装的原始函数
effect.raw = fn
// effect 对应的依赖,双向指针,依赖包含对 effect 的引用,effect 也包含对依赖的引用
effect.deps = []
// effect 的相关配置
effect.options = options
return effect
}
结合上述代码来看,effect 内部通过执行 createReactiveEffect 函数去创建一个新的 effect 函数,为了和外部的 effect 函数区分,我们把它称作 reactiveEffect 函数,并且还给它添加了一些额外属性(我在注释中都有标明)。另外,effect 函数还支持传入一个配置参数以支持更多的 feature,这里就不展开了。
reactiveEffect 函数就是响应式的副作用函数,当执行 trigger 过程派发通知的时候,执行的 effect 就是它。
按我们之前的分析,reactiveEffect 函数只需要做两件事情:让全局的 activeEffect 指向它, 然后执行被包装的原始函数 fn。
但实际上它的实现要更复杂一些,首先它会判断 effect 的状态是否是 active,这其实是一种控制手段,允许在非 active 状态且非调度执行情况,则直接执行原始函数 fn 并返回。
接着判断 effectStack 中是否包含 effect,如果没有就把 effect 压入栈内。之前我们提到,只要设置 activeEffect = effect 即可,那么这里为什么要设计一个栈的结构呢?
其实是考虑到以下这样一个嵌套 effect 的场景:
import { reactive} from 'vue'
import { effect } from '@vue/reactivity'
const counter = reactive({
num: 0,
num2: 0
})
function logCount() {
effect(logCount2)
console.log('num:', counter.num)
}
function count() {
counter.num++
}
function logCount2() {
console.log('num2:', counter.num2)
}
effect(logCount)
count()
我们每次执行 effect 函数时,如果仅仅把 reactiveEffect 函数赋值给 activeEffect,那么针对这种嵌套场景,执行完 effect(logCount2) 后,activeEffect 还是 effect(logCount2) 返回的 reactiveEffect 函数,这样后续访问 counter.num 的时候,依赖收集对应的 activeEffect 就不对了,此时我们外部执行 count 函数修改 counter.num 后执行的便不是 logCount 函数,而是 logCount2 函数,最终输出的结果如下:
num2: 0
num: 0
num2: 0
而我们期望的结果应该如下:
num2: 0
num: 0
num2: 0
num: 1
因此针对嵌套 effect 的场景,我们不能简单地赋值 activeEffect,应该考虑到函数的执行本身就是一种入栈出栈操作,因此我们也可以设计一个 effectStack,这样每次进入 reactiveEffect 函数就先把它入栈,然后 activeEffect 指向这个 reactiveEffect 函数,接着在 fn 执行完毕后出栈,再把 activeEffect 指向 effectStack 最后一个元素,也就是外层 effect 函数对应的 reactiveEffect。
这里我们还注意到一个细节,在入栈前会执行 cleanup 函数清空 reactiveEffect 函数对应的依赖 。在执行 track 函数的时候,除了收集当前激活的 effect 作为依赖,还通过 activeEffect.deps.push(dep) 把 dep 作为 activeEffect 的依赖,这样在 cleanup 的时候我们就可以找到 effect 对应的 dep 了,然后把 effect 从这些 dep 中删除。cleanup 函数的代码如下所示:
function cleanup(effect) {
const { deps } = effect
if (deps.length) {
for (let i = 0; i < deps.length; i++) {
deps[i].delete(effect)
}
deps.length = 0
}
}
为什么需要 cleanup 呢?如果遇到这种场景:
<template>
<div v-if="state.showMsg">
{{ state.msg }}
</div>
<div v-else>
{{ Math.random()}}
</div>
<button @click="toggle">Toggle Msg</button>
<button @click="switchView">Switch View</button>
</template>
<script>
import { reactive } from 'vue'
export default {
setup() {
const state = reactive({
msg: 'Hello World',
showMsg: true
})
function toggle() {
state.msg = state.msg === 'Hello World' ? 'Hello Vue' : 'Hello World'
}
function switchView() {
state.showMsg = !state.showMsg
}
return {
toggle,
switchView,
state
}
}
}
</script>
结合代码可以知道,这个组件的视图会根据 showMsg 变量的控制显示 msg 或者一个随机数,当我们点击 Switch View 的按钮时,就会修改这个变量值。
假设没有 cleanup,在第一次渲染模板的时候,activeEffect 是组件的副作用渲染函数,因为模板 render 的时候访问了 state.msg,所以会执行依赖收集,把副作用渲染函数作为 state.msg 的依赖,我们把它称作 render effect。然后我们点击 Switch View 按钮,视图切换为显示随机数,此时我们再点击 Toggle Msg 按钮,由于修改了 state.msg 就会派发通知,找到了 render effect 并执行,就又触发了组件的重新渲染。
但这个行为实际上并不符合预期,因为当我们点击 Switch View 按钮,视图切换为显示随机数的时候,也会触发组件的重新渲染,但这个时候视图并没有渲染 state.msg,所以对它的改动并不应该影响组件的重新渲染。
因此在组件的 render effect 执行之前,如果通过 cleanup 清理依赖,我们就可以删除之前 state.msg 收集的 render effect 依赖。这样当我们修改 state.msg 时,由于已经没有依赖了就不会触发组件的重新渲染,符合预期。
响应式实现的优化
前面分析了响应式实现原理,看上去一切都很 OK,那么这里面还有哪些可以值得优化的点呢?
依赖收集的优化
目前每次副作用函数执行,都需要先执行 cleanup 清除依赖,然后在副作用函数执行的过程中重新收集依赖,这个过程牵涉到大量对 Set 集合的添加和删除操作。在许多场景下,依赖关系是很少改变的,因此这里存在一定的优化空间。
为了减少集合的添加删除操作,我们需要标识每个依赖集合的状态,比如它是不是新收集的,还是已经被收集过的。
所以这里需要给集合 dep 添加两个属性:
export const createDep = (effects) => {
const dep = new Set(effects)
dep.w = 0
dep.n = 0
return dep
}
其中 w 表示是否已经被收集,n 表示是否新收集。
然后设计几个全局变量,effectTrackDepth、trackOpBit、maxMarkerBits。
其中 effectTrackDepth 表示递归嵌套执行 effect 函数的深度;trackOpBit 用于标识依赖收集的状态;maxMarkerBits 表示最大标记的位数。
接下来看它们的应用:
function effect(fn, options) {
if (fn.effect) {
fn = fn.effect.fn
}
// 创建 _effect 实例
const _effect = new ReactiveEffect(fn)
if (options) {
// 拷贝 options 中的属性到 _effect 中
extend(_effect, options)
if (options.scope)
// effectScope 相关处理逻辑
recordEffectScope(_effect, options.scope)
}
if (!options || !options.lazy) {
// 立即执行
_effect.run()
}
// 绑定 run 函数,作为 effect runner
const runner = _effect.run.bind(_effect)
// runner 中保留对 _effect 的引用
runner.effect = _effect
return runner
}
class ReactiveEffect {
constructor(fn, scheduler = null, scope) {
this.fn = fn
this.scheduler = scheduler
this.active = true
// effect 存储相关的 deps 依赖
this.deps = []
// effectScope 相关处理逻辑
recordEffectScope(this, scope)
}
run() {
if (!this.active) {
return this.fn()
}
if (!effectStack.includes(this)) {
try {
// 压栈
effectStack.push((activeEffect = this))
enableTracking()
// 根据递归的深度记录位数
trackOpBit = 1 << ++effectTrackDepth
// 超过 maxMarkerBits 则 trackOpBit 的计算会超过最大整形的位数,降级为 cleanupEffect
if (effectTrackDepth <= maxMarkerBits) {
// 给依赖打标记
initDepMarkers(this)
}
else {
cleanupEffect(this)
}
return this.fn()
}
finally {
if (effectTrackDepth <= maxMarkerBits) {
// 完成依赖标记
finalizeDepMarkers(this)
}
// 恢复到上一级
trackOpBit = 1 << --effectTrackDepth
resetTracking()
// 出栈
effectStack.pop()
const n = effectStack.length
// 指向栈最后一个 effect
activeEffect = n > 0 ? effectStack[n - 1] : undefined
}
}
}
stop() {
if (this.active) {
cleanupEffect(this)
if (this.onStop) {
this.onStop()
}
this.active = false
}
}
}
可以看到,effect 函数的实现做了一定的修改和调整,内部使用 ReactiveEffect 类创建了一个 _effect 实例,并且函数返回的 runner 指向的是 ReactiveEffect 类的 run 方法。
也就是执行副作用函数 effect 函数时,实际上执行的就是这个 run 函数。
当 run 函数执行的时候,我们注意到 cleanup 函数不再默认执行,在封装的函数 fn 执行前,首先执行 trackOpBit = 1 << ++effectTrackDepth 记录 trackOpBit,然后对比递归深度是否超过了 maxMarkerBits,如果超过(通常情况下不会)则仍然执行老的 cleanup 逻辑,如果没超过则执行 initDepMarkers 给依赖打标记,来看它的实现:
const initDepMarkers = ({ deps }) => {
if (deps.length) {
for (let i = 0; i < deps.length; i++) {
deps[i].w |= trackOpBit // 标记依赖已经被收集
}
}
}
initDepMarkers 函数实现很简单,遍历 _effect 实例中的 deps 属性,给每个 dep 的 w 属性标记为 trackOpBit 的值。
接下来会执行 fn 函数,在就是副作用函数封装的函数,比如针对组件渲染,fn 就是组件渲染函数。
当 fn 函数执行时候,会访问到响应式数据,就会触发它们的 getter,进而执行 track 函数执行依赖收集。相应的,依赖收集的过程也做了一些调整:
function track(target, type, key) {
if (!isTracking()) {
return
}
let depsMap = targetMap.get(target)
if (!depsMap) {
// 每个 target 对应一个 depsMap
targetMap.set(target, (depsMap = new Map()))
}
let dep = depsMap.get(key)
if (!dep) {
// 每个 key 对应一个 dep 集合
depsMap.set(key, (dep = createDep()))
}
const eventInfo = (process.env.NODE_ENV !== 'production')
? { effect: activeEffect, target, type, key }
: undefined
trackEffects(dep, eventInfo)
}
function trackEffects(dep, debuggerEventExtraInfo) {
let shouldTrack = false
if (effectTrackDepth <= maxMarkerBits) {
if (!newTracked(dep)) {
// 标记为新依赖
dep.n |= trackOpBit
// 如果依赖已经被收集,则不需要再次收集
shouldTrack = !wasTracked(dep)
}
}
else {
// cleanup 模式
shouldTrack = !dep.has(activeEffect)
}
if (shouldTrack) {
// 收集当前激活的 effect 作为依赖
dep.add(activeEffect)
// 当前激活的 effect 收集 dep 集合作为依赖
activeEffect.deps.push(dep)
if ((process.env.NODE_ENV !== 'production') && activeEffect.onTrack) {
activeEffect.onTrack(Object.assign({
effect: activeEffect
}, debuggerEventExtraInfo))
}
}
}
我们发现,当创建 dep 的时候,是通过执行 createDep 方法完成的,此外,在 dep 把前激活的 effect 作为依赖收集前,会判断这个 dep 是否已经被收集,如果已经被收集,则不需要再次收集了。此外,这里还会判断这 dep 是不是新的依赖,如果不是,则标记为新的。
接下来,我们再来看 fn 执行完后的逻辑:
finally {
if (effectTrackDepth <= maxMarkerBits) {
// 完成依赖标记
finalizeDepMarkers(this)
}
// 恢复到上一级
trackOpBit = 1 << --effectTrackDepth
resetTracking()
// 出栈
effectStack.pop()
const n = effectStack.length
// 指向栈最后一个 effect
activeEffect = n > 0 ? effectStack[n - 1] : undefined
}
在满足依赖标记的条件下,需要执行 finalizeDepMarkers 完成依赖标记,来看它的实现:
const finalizeDepMarkers = (effect) => {
const { deps } = effect
if (deps.length) {
let ptr = 0
for (let i = 0; i < deps.length; i++) {
const dep = deps[i]
// 曾经被收集过但不是新的依赖,需要删除
if (wasTracked(dep) && !newTracked(dep)) {
dep.delete(effect)
}
else {
deps[ptr++] = dep
}
// 清空状态
dep.w &= ~trackOpBit
dep.n &= ~trackOpBit
}
deps.length = ptr
}
}
finalizeDepMarkers 主要做的事情就是找到那些曾经被收集过但是新的一轮依赖收集没有被收集的依赖,从 deps 中移除。这其实就是解决前面举的需要 cleanup 的场景:在新的组件渲染过程中没有访问到的响应式对象,那么它的变化不应该触发组件的重新渲染。
以上就实现了依赖收集部分的优化,可以看到相比于之前每次执行 effect 函数都需要先清空依赖,再添加依赖的过程,现在的实现会在每次执行 effect 包裹的函数前标记依赖的状态,过程中对于已经收集的依赖不会重复收集,执行完 effect 函数还会移除掉已被收集但是新的一轮依赖收集中没有被收集的依赖。
优化后对于 dep 依赖集合的操作就减少了,自然也就优化了性能。
响应式 API 的优化
响应式 API 的优化主要体现在对 ref、computed 等 API 的优化。
以 ref API 为例,来看看它优化前的实现:
function ref(value) {
return createRef(value)
}
const convert = (val) => isObject(val) ? reactive(val) : val
function createRef(rawValue, shallow = false) {
if (isRef(rawValue)) {
// 如果传入的就是一个 ref,那么返回自身即可,处理嵌套 ref 的情况。
return rawValue
}
return new RefImpl(rawValue, shallow)
}
class RefImpl {
constructor(_rawValue, _shallow = false) {
this._rawValue = _rawValue
this._shallow = _shallow
this.__v_isRef = true
// 非 shallow 的情况,如果它的值是对象或者数组,则递归响应式
this._value = _shallow ? _rawValue : convert(_rawValue)
}
get value() {
// 给 value 属性添加 getter,并做依赖收集
track(toRaw(this), 'get' /* GET */, 'value')
return this._value
}
set value(newVal) {
// 给 value 属性添加 setter
if (hasChanged(toRaw(newVal), this._rawValue)) {
this._rawValue = newVal
this._value = this._shallow ? newVal : convert(newVal)
// 派发通知
trigger(toRaw(this), 'set' /* SET */, 'value', newVal)
}
}
}
ref 函数返回了 createRef 函数执行的返回值,而在 createRef 内部,首先处理了嵌套 ref 的情况,如果传入的 rawValue 也是个 ref,那么直接返回 rawValue;接着返回 RefImpl 对象的实例。
而 RefImpl 内部的实现,主要是劫持它的实例 value 属性的 getter 和 setter。
当访问一个 ref 对象的 value 属性,会触发 getter 执行 track 函数做依赖收集然后返回它的值;当修改一个 ref 对象的 value 值,则会触发 setter 设置新值并且执行 trigger 函数派发通知,如果新值 newVal 是对象或者数组类型,那么把它转换成一个 reactive 对象。
接下来,我们再来看 Vue.js 3.2 对于这部分的实现相关的改动:
class RefImpl {
constructor(value, _shallow = false) {
this._shallow = _shallow
this.dep = undefined
this.__v_isRef = true
this._rawValue = _shallow ? value : toRaw(value)
this._value = _shallow ? value : convert(value)
}
get value() {
trackRefValue(this)
return this._value
}
set value(newVal) {
newVal = this._shallow ? newVal : toRaw(newVal)
if (hasChanged(newVal, this._rawValue)) {
this._rawValue = newVal
this._value = this._shallow ? newVal : convert(newVal)
triggerRefValue(this, newVal)
}
}
}
主要改动部分就是对 ref 对象的 value 属性执行依赖收集和派发通知的逻辑。
在 Vue.js 3.2 版本的 ref 的实现中,关于依赖收集部分,由原先的 track 函数改成了 trackRefValue,来看它的实现:
function trackRefValue(ref) {
if (isTracking()) {
ref = toRaw(ref)
if (!ref.dep) {
ref.dep = createDep()
}
if ((process.env.NODE_ENV !== 'production')) {
trackEffects(ref.dep, {
target: ref,
type: "get" /* GET */,
key: 'value'
})
}
else {
trackEffects(ref.dep)
}
}
}
可以看到这里直接把 ref 的相关依赖保存到 dep 属性中,而在 track 函数的实现中,会把依赖保留到全局的 targetMap 中:
let depsMap = targetMap.get(target)
if (!depsMap) {
// 每个 target 对应一个 depsMap
targetMap.set(target, (depsMap = new Map()))
}
let dep = depsMap.get(key)
if (!dep) {
// 每个 key 对应一个 dep 集合
depsMap.set(key, (dep = createDep()))
}
显然,track 函数内部可能需要做多次判断和设置逻辑,而把依赖保存到 ref 对象的 dep 属性中则省去了这一系列的判断和设置,从而优化性能。
相应的,ref 的实现关于派发通知部分,由原先的 trigger 函数改成了 triggerRefValue,来看它的实现:
function triggerRefValue(ref, newVal) {
ref = toRaw(ref)
if (ref.dep) {
if ((process.env.NODE_ENV !== 'production')) {
triggerEffects(ref.dep, {
target: ref,
type: "set" /* SET */,
key: 'value',
newValue: newVal
})
}
else {
triggerEffects(ref.dep)
}
}
}
function triggerEffects(dep, debuggerEventExtraInfo) {
for (const effect of isArray(dep) ? dep : [...dep]) {
if (effect !== activeEffect || effect.allowRecurse) {
if ((process.env.NODE_ENV !== 'production') && effect.onTrigger) {
effect.onTrigger(extend({ effect }, debuggerEventExtraInfo))
}
if (effect.scheduler) {
effect.scheduler()
}
else {
effect.run()
}
}
}
}
由于直接从 ref 属性中就拿到了它所有的依赖且遍历执行,不需要执行 trigger 函数一些额外的逻辑,因此在性能上也得到了提升。
trackOpBit 的设计
细心的你可能会发现,标记依赖的 trackOpBit,在每次计算时采用了左移的运算符 trackOpBit = 1 << ++effectTrackDepth;并且在赋值的时候,使用了或运算:
deps[i].w |= trackOpBit dep.n |= trackOpBit
那么为什么这么设计呢?因为 effect 的执行可能会有递归的情况,通过这种方式就可以记录每个层级的依赖标记情况。
在判断某个 dep 是否已经被依赖收集的时候,使用了 wasTracked 函数:
const wasTracked = (dep) => (dep.w & trackOpBit) > 0
通过与运算的结果是否大于 0 来判断,这就要求依赖被收集时嵌套的层级要匹配。举个例子,假设此时 dep.w 的值是 2,说明它是在第一层执行 effect 函数时创建的,但是这时候已经执行了嵌套在第二层的 effect 函数,trackOpBit 左移两位变成了 4,2 & 4 的值是 0,那么 wasTracked 函数返回值为 false,说明需要收集这个依赖。显然,这个需求是合理的。
可以看到,如果没有 trackOpBit 位运算的设计,你就很难去处理不同嵌套层级的依赖标记,这个设计也体现了 basvanmeurs 大佬非常扎实的计算机基础功力。
总结
一般在 Vue.js 的应用中,对响应式数据的访问和修改都是非常频繁的操作,因此对这个过程的性能优化,将极大提升整个应用的性能。
大部分人去看 Vue.js 响应式的实现,可能目的最多就是搞明白其中的实现原理,而很少去关注其中实现是否是最优的。而 basvanmeurs 大佬能对提出这一系列的优化的实现,并且手写了一个 benchmark 工具 来验证自己的优化,非常值得我们学习。
原贴,看看他们的讨论,相信你会收获更多。
前端的性能优化永远是一个值得深挖的方向,希望在日后的开发中,不论是写框架还是业务,你都能够经常去思考其中可能存在的优化的点。
以上就是Vue.js3.2响应式部分的优化升级详解的详细内容,更多关于Vue.js3.2响应式优化升级的资料请关注易盾网络其它相关文章!