目录
- 背景 & 目标
- Doris 数据划分
- Partition
- Bucket
- Join 方式
- 总览
- Broadcast / Shuffle Join
- Bucket Shuffle Join
- Plan Rule
- Colocate Join
- Runtime Filter 优化
- Join Reorder 优化
- Join 调优建议
背景 & 目标
- 掌握 Apache Doris Join 优化手段及其实现原理
- 为代码阅读提供理论基础
Doris 数据划分
不同的 Join 方式非常依赖于对 Doris 中数据划分方式的透彻理解。因此先在这里列举出必要的基础知识。
首先,在 Doris 中数据都以表(Table)的形式进行逻辑上的描述。
在 Doris 的存储引擎中,用户数据被水平划分为若干个数据分片(Tablet,也称作数据分桶 Bucket)。每个 Tablet 包含若干数据行。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。
一个 Tablet 只属于一个数据分区(Partition)。而一个 Partition 包含若干个 Tablet。因为 Tablet 在物理上是独立存储的,所以可以视为 Partition 在物理上也是独立的。Tablet 是数据移动、复制等操作的最小物理存储单元。
若干个 Partition 组成一个 Table。Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,仅能针对一个 Partition 进行。
Doris 支持两层的数据划分。第一层是 Partition,支持 Range 和 List 的划分方式。第二层是 Bucket(Tablet),仅支持 Hash 的划分方式。也可以仅使用一层分区。使用一层分区时,只支持 Bucket 划分。
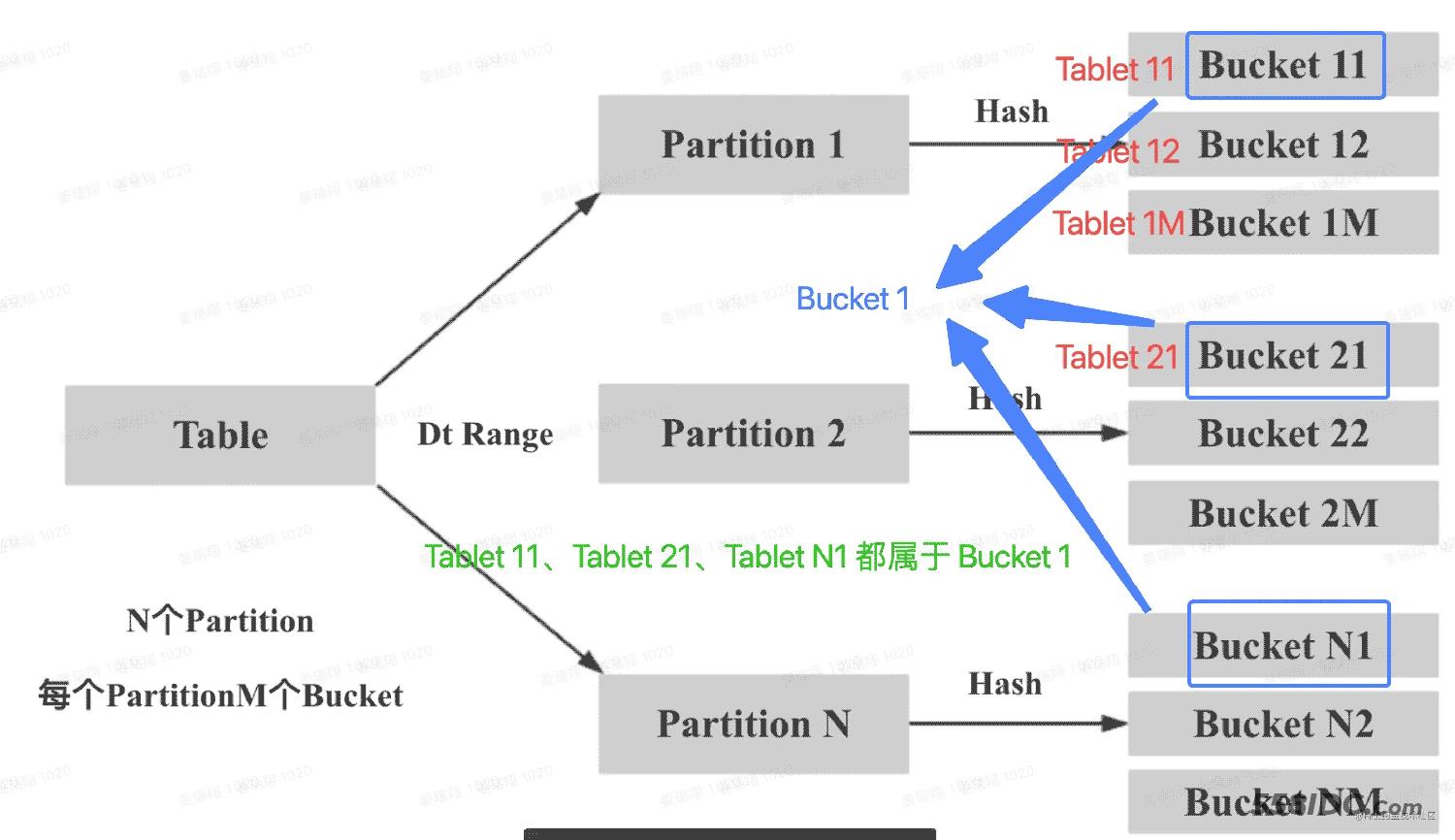
下图说明 Table、Partition、Bucket(Tablet) 的关系:
- Table 按照 Range 的方式按照 date 字段进行分区,得到了 N 个 Partition
- 每个 Partition 通过相同的 Hash 方式将其中的数据划分为 M 个 Bucket(Tablet)
- 从逻辑上来说,Bucket 1 可以包含 N 个 Partition 中划分得到的数据,比如下图中的 Tablet 11、Tablet 21、Tablet N1
特别注意:
Doris 中的 Partition 和 Bucket 定义可能和某些其它数据库系统的定义有一些差异,下面配以一个具体的建表语句为例来说明:
CREATE TABLE IF NOT EXISTS example_db.expamle_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3"
);
绿色高亮:Partition,此例中使用一个 date 字段进行分区
蓝色高亮:Bucket,此例中使用 user_id 字段为作为分布列
Partition
- Partition 列可以指定一列或多列,分区列必须为 KEY 列
- 分区数量理论上没有上限
- 当不使用 Partition 建表时,系统会自动生成一个和表名同名的,全值范围的 Partition。该 Partition 对用户不可见,并且不可删改
创建分区时不可添加范围重叠的分区
有两种分区方式:
Bucket
- 如果使用了 Partition,则 DISTRIBUTED 语句描述的是数据在各个分区内的划分规则。如果不使用 Partition,则描述的是对整个表的数据划分规则
- 分桶列的选择,是在 查询吞吐 和 查询并发 之间的一种权衡:
- 如果选择多个分桶列,则数据分布更均匀。如果一个查询条件不包含所有分桶列的等值条件(意味着无法做桶裁剪以减少数据查询范围),那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景
- 如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描(意味着可以做桶裁剪以减少数据查询范围)。此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的 IO 影响较小,尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景
- 分桶的数量理论上没有上限
Join 方式
总览
作为分布式的 MPP 数据库, 在 Join 的过程中是需要进行数据的 Shuffle。数据需要进行拆分调度,才能保证最终的 Join 结果是正确的。举个简单的例子,假设关系 S 和 R 进行Join,N 表示参与 Join 计算的节点的数量;T 则表示关系的 Tuple 数目。
目前 Doris 支持的 Join 方式有以上 4 种,这 4 种方式灵活度和适用性是从高到低的,对数据分布的要求越来越严,但 Join 计算的性能则通过降低网络开销而越来越好。
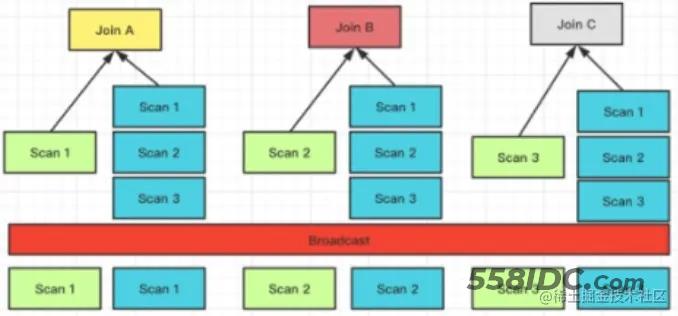
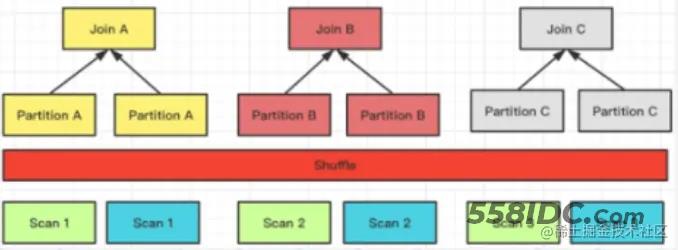
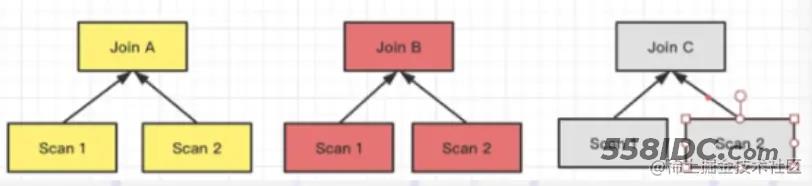
Join 方式的选择是 FE 生成分布式计划阶段会考虑的事项之一。在 FE 进行分布式计划时,优先选择的顺序为(总是会优先选择预期性能最好的):Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。
Colocate 以及 Bucket Shuffle 是可遇不可求的。当无法使用它们时,Doris会自动尝试进行 Broadcast Join,如果预估小表过大则会自动切换至 Shuffle Join。
但是用户可以通过显式 Hint 来强制使用期望的 Join 类型,比如:
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
Broadcast / Shuffle Join
原理比较简单,这里不展开。
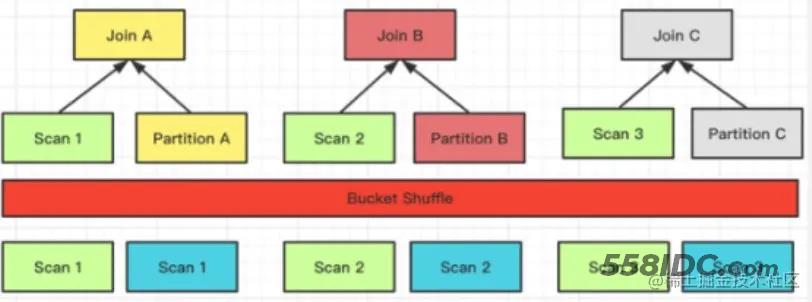
Bucket Shuffle Join
当 Join 条件命中了左表的数据分布列时,Broadcast 以及 Shuffle Join 会有非必要的网络传输开销。而 Bucket Shuffle Join 旨在解决这类问题,通过对左表实现本地性计算优化,来减少左表数据在节点间的传输耗时,从而加速查询。
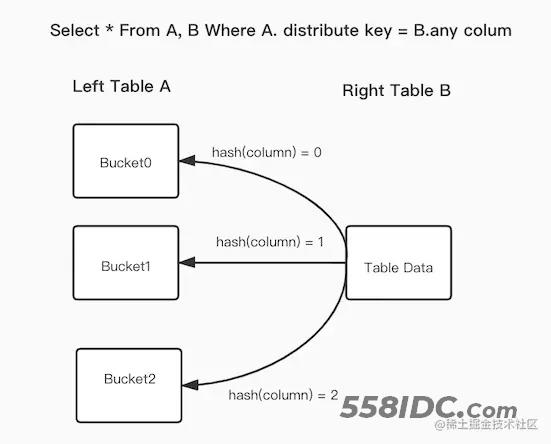
以上的例子中,Join 的等值表达式命中了表 A(左表)的数据分布列。Bucket Shuffle Join 会根据表 A 的数据分布信息,将表 B(右表)的数据发送到对应表 A 的数据计算节点。
定性分析上:
- 降低了网络与内存开销(相比 Broadcast 以及 Shuffle Join 都不会更差),使一类 Join 查询有更好的性能。尤其是当 FE 能够执行左表的分区裁剪与桶裁剪时
- 与 Colocate Join 不同,它对于表的数据分布方式没有侵入性,对于用户来说是透明的。对于表的数据分布没有强制性的要求(体现在建表语句中不需要显式地设置 colocate_with 属性),不容易导致数据倾斜的问题
- 可以为 Join Reorder 提供更多可能的优化空间
Plan Rule
- Bucket Shuffle Join 只生效于 Join 条件为等值的场景,原因与 Colocate Join 类似,它们都依赖 Hash 来计算确定的数据分布
- 在等值 Join 条件之中包含两张表的分桶列,当左表的分桶列为等值的 Join 条件时,它有很大概率会被规划为 Bucket Shuffle Join
- 由于不同的数据类型的 Hash 值计算结果不同,所以 Bucket Shuffle Join 要求左表的分桶列的类型与右表等值 Join 列的类型需要保持一致,否则无法进行对应的规划
- Bucket Shuffle Join 只作用于 Doris 原生的 OLAP 表,对于 ODBC,MySQL,ES 等外表,当其作为左表时是无法规划生效的
- 对于分区表,由于每一个分区的数据分布规则可能不同,所以 Bucket Shuffle Join 只能保证左表为单分区时生效。所以在 SQL 执行之中,需要尽量使用 where 条件使分区裁剪的策略能够生效
- 假如左表为 Colocate 的表,那么它每个分区的数据分布规则是确定的,Bucket Shuffle Join 能在Colocate 表上表现更好
Colocate Join
可以理解为在数据分布满足一定条件的前提下,减少一切不必要的网络传输开销,实现完全的计算本地化来加速查询。同时因为没有网络传输开销,BE 节点可以拥有更高的并发度,从而进一步提升 Join 性能。
要理解这个算法,需要先了解两个术语:
- Colocation Group(CG):一个 CG 中会包含一张及以上的 Table。在同一个 Group 内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布
- Colocation Group Schema(CGS):用于描述一个 CG 中的 Table,和 Colocation 相关的通用 Schema 信息。包括分桶列类型,分桶数以及副本数等
和 Buckets Sequence 这一概念:
一个表的数据,最终会根据分桶列值 Hash、对桶数取模后落在某一个分桶内。假设一个 Table 的分桶数为 8,则共有 [0, 1, 2, 3, 4, 5, 6, 7] 8 个分桶(Bucket),我们称这样一个序列为一个 BucketsSequence。每个 Bucket 内会有一个或多个数据分片(Tablet)。当表为单分区表时,一个 Bucket 内仅有一个 Tablet。如果是多分区表,则会有多个(因为多个 Partition 中的不同 Tablet 会被划分到相同的 Bucket)。
Colocation Join 功能,是将一组拥有相同 CGS 的 Table 组成一个 CG。并保证这些 Table 对应的数据分片会落在同一个 BE 节点上。使得当 CG 内的表进行分桶列上的 Join 操作时,可以通过直接进行本地数据 Join,减少数据在节点间的传输耗时。
因此关键问题就转变为了「如何保证这些 Table 对应的数据分片会落在同一个 BE 节点上?」
通过同一 CG 内的 Table 必须保证以下属性相同实现:
- 分桶列和分桶数
分桶列,即在建表语句中 DISTRIBUTED BY HASH(col1, col2, ...) 中指定的列。分桶列决定了一张表的数据通过哪些列的值进行 Hash 划分到不同的 Tablet 中。同一 CG 内的 Table 必须保证分桶列的类型和数量完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制。
- 副本数
同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。不过,同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致。
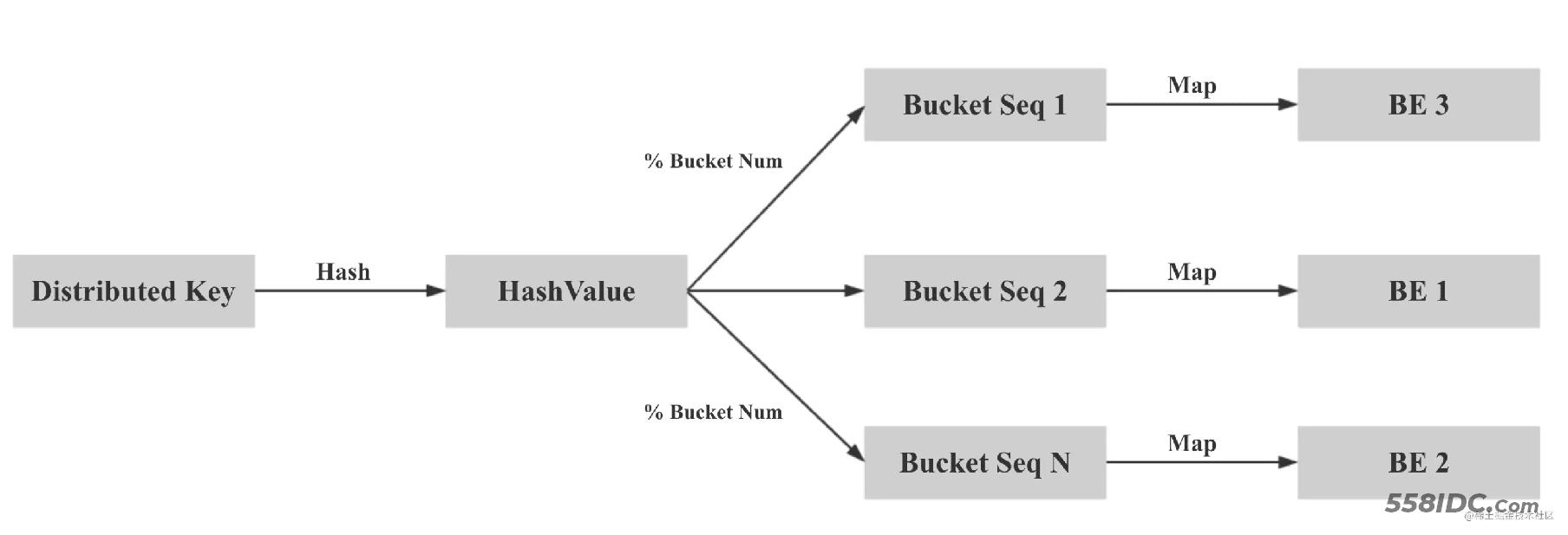
在固定了分桶列和分桶数后,同一个 CG 内的表会拥有相同的 BucketsSequence。而副本数决定了每个分桶内的 Tablet 的多个副本,存放在哪些 BE 上。假设 BucketsSequence 为 [0, 1, 2, 3, 4, 5, 6, 7],BE 节点有 [A, B, C, D] 4个。则一个可能的数据分布如下:
+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ | 0 | | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 | +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+ | A | | B | | C | | D | | A | | B | | C | | D | | | | | | | | | | | | | | | | | | B | | C | | D | | A | | B | | C | | D | | A | | | | | | | | | | | | | | | | | | C | | D | | A | | B | | C | | D | | A | | B | +---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
CG 内所有表的数据都会按照上面的规则进行统一分布,这样就保证了,分桶列值相同的数据都在同一个 BE 节点上,可以进行本地数据 Join。其核心思想是「两次映射」,保证相同的 Distributed Key 的数据会被映射到相同的 Bucket Sequence,再保证 Bucket Sequence 对应的 Bucket 映射到相同的 BE 节点:
通过查询计划可以检查一个查询是否使用了 Colocate Join,同时计划中的 Exchange Node 也被去掉了,会将 ScanNode 直接设置为 Hash Join Node 的孩子节点。
DESC SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2); -- 在 Hash Join 节点会显示: -- colocate: true/false
Colocate Join 十分适合几张表按照相同字段分桶,并高频根据固定的字段 Join 的场景。这样可以将数据预先存储到相同的分桶中,实现本地计算。
Runtime Filter 优化
Doris 在进行 Hash Join 计算时会在右表构建一个 Hash Table,左表流式地通过右表的 Hash Table 从而得出 Join 结果。而 Runtime Filter 就是充分利用了右表的 Hash Table 构建阶段去做一些额外的事情。
在右表生成 Hash Table 的时,同时生成一个基于 Hash Table 数据的一个过滤条件,然后下推到左表的数据扫描节点。通过这样的方式,Doris 可以在运行时进行数据过滤。
假如左表是一张大表,右表是一张小表,那么利用下推到左表的过滤条件就可以把绝大多数 Join 层要过滤的数据在数据读取时就提前过滤(如果能够下推到引擎层,还能够利用 Doris 针对 Key 列过滤的延迟物化),从而大幅度地提升 Join 查询的性能。
Runtime Filter 在查询规划时生成,在 HashJoinNode 中构建,在 ScanNode 中应用。比如 T1(行数 10w) 和 T2(行数 2k) 的 Join 操作:
| > HashJoinNode < | | | | | 100000 | 2000 | | | | OlapScanNode OlapScanNode | ^ ^ | | 100000 | 2000 | T1 T2 |
显而易见对 T2 扫描数据要远远快于 T1,如果我们主动等待一段时间再扫描 T1,等 T2 将扫描的数据记录交给 HashJoinNode 后,HashJoinNode 根据 T2 的数据计算出一个过滤条件,比如 T2 数据的最大和最小值,或者构建一个 Bloom Filter,接着将这个过滤条件发给等待扫描 T1 的 ScanNode,后者应用这个过滤条件,将过滤后的数据交给 HashJoinNode,从而减少 probe hash table 的次数和网络开销,这个过滤条件就是 Runtime Filter,效果如下:
| > HashJoinNode < | | | | | 6000 | 2000 | | | | OlapScanNode OlapScanNode | ^ ^ | | 100000 | 2000 | T1 T2 |
如果能将过滤条件(Runtime Filter)下推到存储引擎,则某些情况可以利用索引(比如 Join 列为 Key 列,可以利用延迟物化能力)来直接减少扫描的数据量,从而大大减少扫描耗时,效果如下:
| > HashJoinNode < | | | | | 6000 | 2000 | | | | OlapScanNode OlapScanNode | ^ ^ | | 6000 | 2000 | T1 T2 |
可见,和谓词下推、分区裁剪不同,Runtime Filter 是在运行时动态生成的过滤条件,即在查询运行时解析 Join 条件确定过滤表达式,并将表达式下推给正在读取左表的 ScanNode,从而减少扫描的数据量,进而减少 probe hash table 的次数,避免不必要的 IO 和网络传输。因为其运行时生效的特性,官方认为它是 Adaptive Query Execution 的一种应用。
根据上面的例子,可以推导出场景满足以下的条件时,使用 Runtime Filter 的效果会比较好:
- 左表大右表小(当右表上还有额外的过滤条件会更理想),因为构建 Runtime Filter 是需要承担计算成本的,包括一些内存的开销,而开销直接取决于右表的实际数据量
- 左右表 Join 出来的结果很少,说明通过 Runtime Filter 可以过滤掉左表的绝大部分数据
Doris 支持 3 种 Runtime Filter:
- 一种是 IN,很好理解,将一个 hashset 下推到数据扫描节点。
- 第二种就是 BloomFilter,就是利用哈希表的数据构造一个 BloomFilter,然后把这个 BloomFilter 下推到查询数据的扫描节点。
- 最后一种就是 MinMax,就是个 Range 范围,通过右表数据确定 Range 范围之后,下推给数据扫描节点。
工作原理和优劣总结如下:
一些使用的注意事项(比较细节了,后面考虑结合代码再深入理解):
开启 Runtime Filter 后,左表的 ScanNode 会为每一个分配给自己的 Runtime Filter 等待一段时间再扫描数据,即如果 ScanNode 被分配了 3 个 Runtime Filter,那么它最多会等待 3000ms。
因为 Runtime Filter 的构建和合并均需要时间,ScanNode 会尝试将等待时间内到达的 Runtime Filter 下推到存储引擎,如果超过等待时间后,ScanNode 会使用已经到达的 Runtime Filter 直接开始扫描数据。
如果 Runtime Filter 在 ScanNode 开始扫描之后到达,则 ScanNode 不会将该 Runtime Filter 下推到存储引擎,而是对已经从存储引擎扫描上来的数据,在 ScanNode 上基于该 Runtime Filter 使用表达式过滤,之前已经扫描的数据则不会应用该 Runtime Filter,这样得到的中间数据规模会大于最优解,但可以避免严重的劣化。
如果集群比较繁忙,并且集群上有许多资源密集型或长耗时的查询,可以考虑增加等待时间,以避免复杂查询错过优化机会。如果集群负载较轻,并且集群上有许多只需要几秒的小查询,可以考虑减少等待时间,以避免每个查询增加 1s 的延迟。
Join Reorder 优化
有了前面两表 Join 的 Runtime Filter 铺垫,再来看 Join Reorder 的优化,逻辑关系上就能够理顺了。

Doris 目前的 Join Reorder 算法是基于 RBO 的,逻辑描述如下:
- 尽量让大表跟小表做 Join,它生成的中间结果是尽可能小的
- 把有条件的 Join 表往前放,也就是说尽量让有条件的 Join 表进行过滤
- Hash Join 的优先级高于 Nest Loop Join,因为 Hash join 本身是比 Nest Loop Join 快很多的
可以发现前两条,都是在朝着让「右表」更小的方向去优化,而最后一条则是从算法的性能上来考虑。
Join 调优建议
- Join 列最好是相同的简单类型;同类型避免 Cast 操作,简单类型则有不错的 Join 计算性能
- Join 列最好是 Key 列,原因是 Key 列能够充分利用 Doris 延迟物化的特性,减少 IO 提升性能
- 大表之间的 Join 最好能够利用上 Colocate,相当于已经做好了预 Shuffle,实际查询的时候可以直接 Join 计算不再有 Shuffle 操作,彻底避免了大表的 Shuffle 网络开销
- 利用 Runtime Filter,Join 过滤性高时效果显著。根据 3 种 Runtime Filter 特点选择最适合的
- 涉及多表 Join,需要判断 Join 的合理性。尽量保证“左大右小”的原则,HashJoin 优于 NLJ。必要时可以通过 SQL Rewrite,通过 Hint 来调整 Join 顺序
REF
https://www.jb51.net/article/266004.htm
https://www.jb51.net/article/266000.htm
以上就是Apache Doris Join 优化原理详解的详细内容,更多关于Apache Doris Join 优化的资料请关注自由互联其它相关文章!