目录
- 一、背景
- 二、方法
- 1、trim()、ltrim()、rtrim()函数
- (1)trim()去除字段首尾空白字符,也可以去除指定字符
- (2)ltrim()去除左空格
- (3)rtrim()去除右空格
- 2、replace()函数
- (1)替换字段中指定字符为新字符
- (2)指定去除一下特殊字符
- 3、convert()函数配合trim()函数(解决了我的问题)
- 补充:你不知道的空格
- Level1: 半角空格
- Level2: 全角空格
- Level3: 不间断空格 ( non-breaking space )
- Level4: 零宽度空格 (ZERO WIDTH SPACE)
- Level5: 其他空格字符空格
- 总结
一、背景
最近系统线上数据库数据出现一个问题,发现某些字段存在一些异常的首尾空格,不管是使用trim对比还是like查询都查询不到具体的数据;在网上找了一些方法,最后发现一个去“不间断空格”的方法解决了问题,在这里做一下记录和汇总。
二、方法
1、trim()、ltrim()、rtrim()函数
语法:trim(字段) || trim([{BOTH | LEADING | TRAILING} [指定字符] FROM] 字段)
(1)trim()去除字段首尾空白字符,也可以去除指定字符
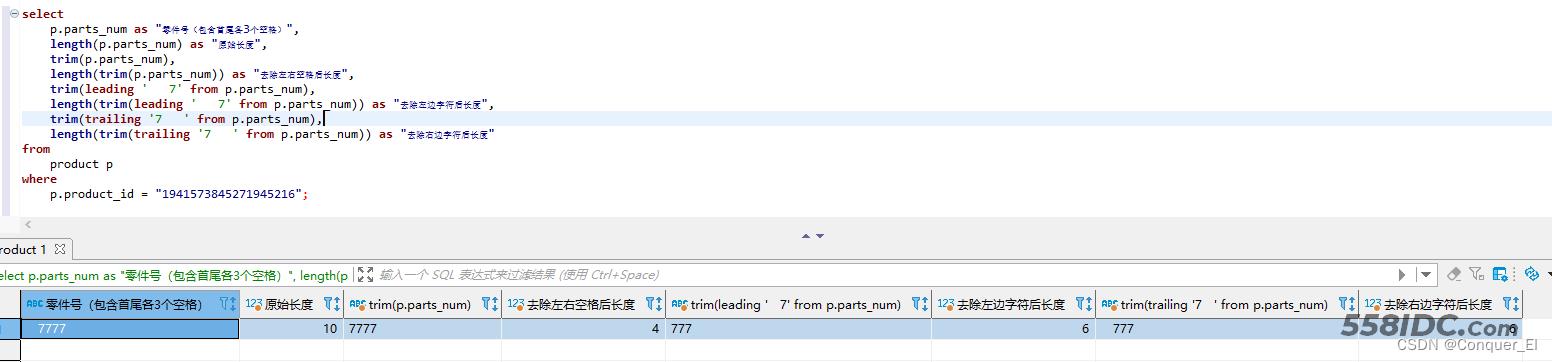
列子:去除商品零件号左右空格,以及指定字符,打印去除字符后的长度
select p.parts_num as "零件号(包含首尾各3个空格)", length(p.parts_num) as "原始长度", trim(p.parts_num), length(trim(p.parts_num)) as "去除左右空格后长度", trim(leading ' 7' from p.parts_num), length(trim(leading ' 7' from p.parts_num)) as "去除左边字符后长度", trim(trailing '7 ' from p.parts_num), length(trim(trailing '7 ' from p.parts_num)) as "去除右边字符后长度" from product p where p.product_id = "1941573845271945216";
结果:
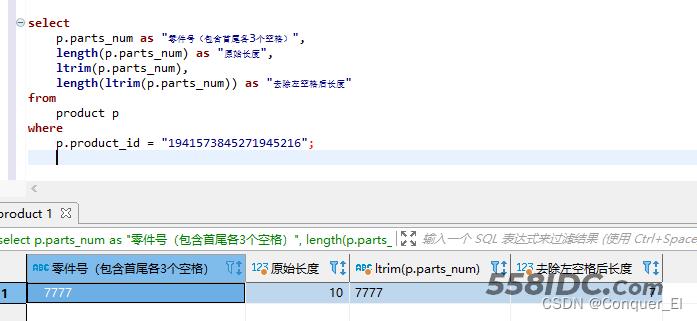
(2)ltrim()去除左空格
select p.parts_num as "零件号(包含首尾各3个空格)", length(p.parts_num) as "原始长度", ltrim(p.parts_num), length(ltrim(p.parts_num)) as "去除左空格后长度" from product p where p.product_id = "1941573845271945216";
结果:
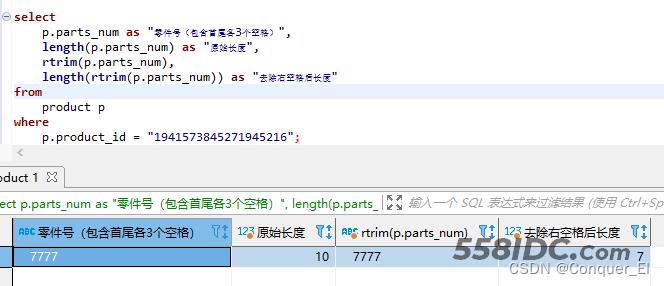
(3)rtrim()去除右空格
select p.parts_num as "零件号(包含首尾各3个空格)", length(p.parts_num) as "原始长度", rtrim(p.parts_num), length(rtrim(p.parts_num)) as "去除右空格后长度" from product p where p.product_id = "1941573845271945216";
结果:
2、replace()函数
语法:replace(object,search,replace)
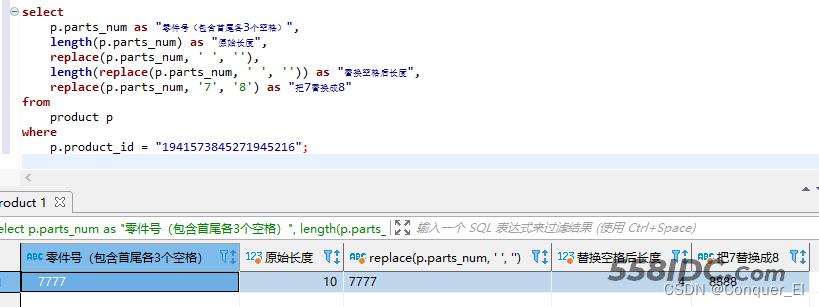
(1)替换字段中指定字符为新字符
select p.parts_num as "零件号(包含首尾各3个空格)", length(p.parts_num) as "原始长度", replace(p.parts_num, ' ', ''), length(replace(p.parts_num, ' ', '')) as "替换空格后长度", replace(p.parts_num, '7', '8') as "把7替换成8" from product p where p.product_id = "1941573845271945216";
结果:
(2)指定去除一下特殊字符
水平制表符:CHAR(9)、换行符:CHAR(10)、回车符:CHAR(13)
REPLACE(REPLACE(REPLACE(p.parts_num, CHAR(9), ''), CHAR(10), ''), CHAR(13), '')
3、convert()函数配合trim()函数(解决了我的问题)
(1)使用convert()先转换一些特殊编码的空格(unicode码位u+00a0的utf-8编码,也称为不间断空格)转换成常规空格(ASCII 中编码为0x20)
-- convert转换,trim去除 select TRIM(convert(0xC2A0 using utf8mb4) FROM p.parts_num); -- 替换掉字符中的不间断空格 select TRIM(REPLACE(p.parts_num, convert(0xC2A0 using utf8mb4), ' '));
这些特殊空格一般常见于各文本编辑器(word、Excel等,刚好出现问题的业务存在Excel导入数据的场景),想要详细了解看下面推荐的文章。
补充:你不知道的空格
Level1: 半角空格
历史最悠久的空格,在1967年,ASCII 规范中被定义。
空格在 ASCII 中编码为0x20, 占位符为一个半角字符。在日常英文书写和代码编写中使用。
Level2: 全角空格
中文输入中的空格(标准说法为中日韩表意字符(CJK)中使用的宽空格)。和其他汉字一样,作为GBK的一个字符,其对应的unicode码为\u3000.宽
度是2个半角空格的大小。
例如:
先生 孙先生
Level3: 不间断空格 ( non-breaking space )
unicode 为 \u00A0, 在代码中可能会出现的编码错误(utf8 编码0xC2 0xA0) 就是它了。
在Word中,会遇到一个有多个单词组成的词组被分割在两行文字中,这样很容易让人看不明白。这时候,不间断空格就可以上场了。
输入不间断空格,会将不间断空格连着的单词在一行展示。
举个例子:

上面英文使用了不间断空格,下面没有使用。所以上面的英文自动在一行展示,而下面没有。
在word中输入不间断空格的方式为: (Ctrl + Shift + Space)
除了在word等文本编辑软件中使用,其实不间断空格在html 中大量使用。 是html 中最为常见的空格。由于html页面中,如果有多个连着的半角空格,则空格只会展示一个。而使用 空格,则会显示占位半个自宽。
Level4: 零宽度空格 (ZERO WIDTH SPACE)
零宽度空格有两种
- 零宽度空格 unicode 编码为 \u200B.
不可见非打印字符。有了半角空格,也有了全角空格,其实还有零宽度空格。因为宽度为零,因此该字符是一个不可见字符。
这个编码虽然是不可见的,但是也是非常有用的。它可以替换html中的标签(软换行, html5 新增)。
- 零宽度非中断空格(ZWNBSP) unicode 编码为 \u2060 (之前使用\ufeff表示,unicode 3.2 开始 \ufeff 标记unicode文档的字节序。)
该空格结合了 non-breaking space 和 零宽度空格的特点。既会自动换行,宽度又是0。
零宽度空格(软换行)举例:
一行连续的英文编码:
<p style="font-size:100px;">phpIsTheBestProgramingLanguageInTheWorld</p>
而如果在每个可以换行的地方加上 <wbr />, 则可以在标记的最近的地方换行。
<p style="font-size:100px;">php<wbr />Is<wbr />The<wbr />Best<wbr />Programing<wbr />Language<wbr />In<wbr />The<wbr />World</p>
Level5: 其他空格字符空格
虽然已经有半角空格、全角空格,但是上面的空格如果字体变化了,不会随着字体的变化而变化。
因此,又有了可以随着字体的变化而变化的空格,简单罗列如下:
在html 的宽度度量中,有一种单位叫em,是按照字体大小定义的,下面的em也是字体的宽度。
打印字符的空格有很多种,罗列几个:
总结
到此这篇关于Mysql查询去空格的文章就介绍到这了,更多相关Mysql查询去空格内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!