因为系统的一个Bug,导致数据库表中出现重复数据,需要做的是删除重复数据且只保留最新的一条数据。
具体场景是这样的
有张订单关联额外费用表,而且一个订单号(order_no)记录只能关联同一个费用(cost_id)一次,但是数据库中出现了同一个订单号关联同一个费用n次
当然有人会说上面的问题我们可以建一个 order_no + cost_id 的组合唯一索引,这样就算代码有bug但至少数据库表中不会有脏数据。
似乎这样就可以了,然而事情并没有那么简单。
因为我们表中的数据在删除的时候不会真的的删除,而是采用逻辑删除,会有一个 deleted 字段使用0,1标识未删除与已删除。
当然 我们也可以考虑将 order_no + cost_id + deleted 组合成一个联合唯一索引。
这样就ok了吗?
其实会有一个新的问题,就是如果同一个订单同一个费用如果被删除一次。再去删除会发现无法成功进行此操作,因为该条数据已经存在了,不能在删除了。
所以当时我们并没有建立联合唯一索引,才导致脏数据的产生。
其实上面这种场景网上有个比较好的解决方案,就是我们依旧可以将 order_no + cost_id + deleted 组合成一个联合唯一索引,
但是删除的时候deleted不再是固定的1,而是当前的主键ID,也就是deleted不等于0都是删除状态,如果删除了那deleted值=id
言归正传,接下来我们来讲下该如何修复脏数据的问题
我们先创建一张订单关联费用表
CREATE TABLE `order_cost_detail` ( `id` int NOT NULL AUTO_INCREMENT COMMENT '主键', `order_no` varchar(32) NOT NULL COMMENT '订单号', `cost_id` int NOT NULL COMMENT '费用Id', `cost_name` varchar(50) NOT NULL DEFAULT '' COMMENT '费用名称', `money` decimal(10,2) NOT NULL COMMENT '金额', `create_time` datetime NOT NULL COMMENT '创建时间', `deleted` tinyint(1) NOT NULL COMMENT '是否删除(0 否,1 是)', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 COMMENT='订单 - 费用表';
插入一些模拟数据
INSERT INTO `order_cost_detail` (`id`, `order_no`, `cost_id`, `cost_name`, `money`, `create_time`, `deleted`) VALUES (1, 'EX202208160000012-3', 2, '停车费', 100.00, '2022-08-19 11:30:48', 0), (2, 'EX202208160000012-4', 3, '停车费', 100.00, '2023-02-17 11:25:27', 0), (3, 'EX202208160000012-4', 3, '停车费', 200.00, '2023-02-17 11:25:28', 0), (4, 'EX202208170000002-1', 1, '路桥费', 300.00, '2022-08-19 11:31:57', 0), (5, 'EX202208170000002-1', 1, '路桥费', 450.00, '2022-08-19 11:32:57', 0), (6, 'EX202208180000002-1', 2, '高速费', 225.00, '2022-08-19 11:35:41', 0);
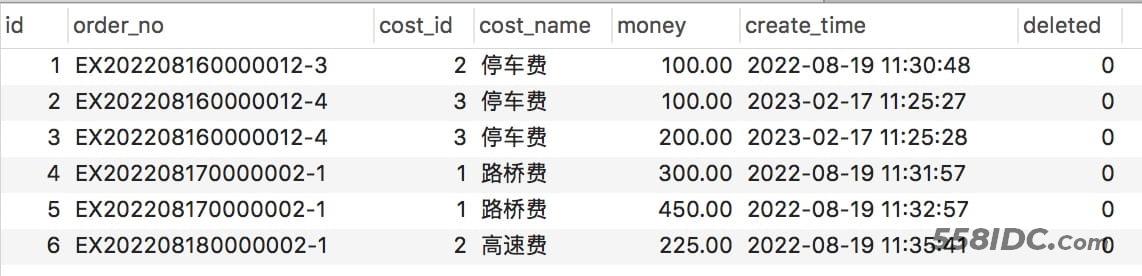
我们的目的很明确,就是要删除 多余的同一订单号费用相同的数据,同时保留最新的一条数据。
我们可以先用sql看下是否有重复数据
SELECT order_no, cost_name, count(*) AS num FROM order_cost_detail WHERE deleted = 0 GROUP BY order_no, cost_name HAVING num > 1
运行结果
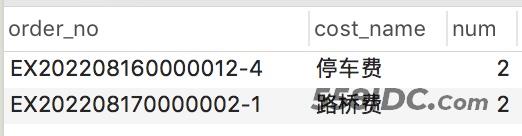
发现有两个订单有脏数据,如果实际生产只有两条脏数据那简单,直接查询这两个订单,把重复数据删掉就好了。
但如果有几十条甚至上百条数据呢,总不能一条一条的删吧。
一般我们删除重复数据都会保留最新的那条,所以我们可以这样做
如果主键是自增的,那么重复数据删除的时候,主键最大的一条就是需要保留的,如果主键不是自增的,我们可以根据创建时间,保留创建时间最大的记录
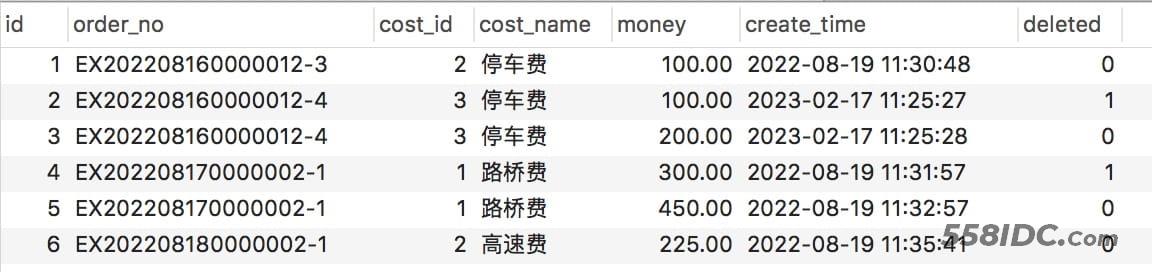
我们先看下,我们需要删除的记录
select * from order_cost_detail where id not in ( select max(id) as num from order_cost_detail where deleted = 0 group by order_no, cost_name )
查询结果

根据结果来看确实是这两条记录需要删除,那么我们开始执行删除操作
sql如下
-- 这里是逻辑删除,也就是将需要删除的数据打上deleted = 1 标记 update order_cost_detail set deleted = 1 where id in ( select id from order_cost_detail where id not in ( select max(id) as num from order_cost_detail where deleted = 0 group by order_no, cost_name ) )
执行的时候发现报错了
You can't specify target table 'order_cost_detail' for update in FROM clause
它的意思是说,不能在同一语句中,先select出同一表中的某些值,再update这个表,即不能依据某字段值做判断再来更新某字段的值。
这个问题在MySQL官网中有提到解决方案:拉到文档下面 https://dev.mysql.com/doc/refman/8.0/en/update.html
解决方法:select 的结果再通过一个中间表 select 多一次,就可以避免这个错误
update order_cost_detail set deleted = 1 where id in ( select t.id from ( select id from order_cost_detail where id not in ( select max(id) as num from order_cost_detail where deleted = 0 group by order_no, cost_name ) ) t )
执行成功
阿里巴巴手册索引规范,第一条就是
【强制】业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
说明:不要以为唯一索引影响了insert速度,这个速度损耗可以忽略,但提高查找速度是明显的:另外,即使在应用层做了非常完善
的校验和控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
到此这篇关于MySQL大量脏数据,如何只保留最新的一条?的文章就介绍到这了,更多相关MySQL保留最新的一条内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!