目录
- MySQL 优化
- 子查询优化
- 待排序的分页查询的优化
- 给排序字段添加索引
- 给排序字段跟 select 字段添加复合索引
- 给排序字段加索引 + 手动回表
- 解决办法
- 排序优化
MySQL 优化
子查询优化
- 将子查询改变为表连接,尤其是在子查询的结果集较大的情况下;
- 添加复合索引,其中复合索引的包含的字段应该包括 where 字段与关联字段;
- 复合索引中的字段顺序要遵守最左匹配原则;
- MySQL 8 中自动对子查询进行优化;
现有两个表
create table Orders
(
id integer AUTO_INCREMENT PRIMARY KEY,
name varchar(255) not null,
order_date datetime NOT NULL
) comment '订单表';
create table OrderDetails
(
id integer AUTO_INCREMENT PRIMARY KEY,
order_id integer not null,
product_code varchar(20) not null,
quantity integer not null
) comment '订单详情表';
子查询
select * from orders where id in (select order_id from OrderDetails where product_code = 'PC50');
优化1:改为表连接
select * from orders as t1 inner join orderdetails o on t1.id = o.order_id where product_code='PC50';
优化2:给 order_id 字段添加索引
优化3:给 product_code 字段添加索引
结果证明:给 product_code 字段添加索引 的效果优于给 order_id 字段添加索引,因为不用对索引列进行全表扫描
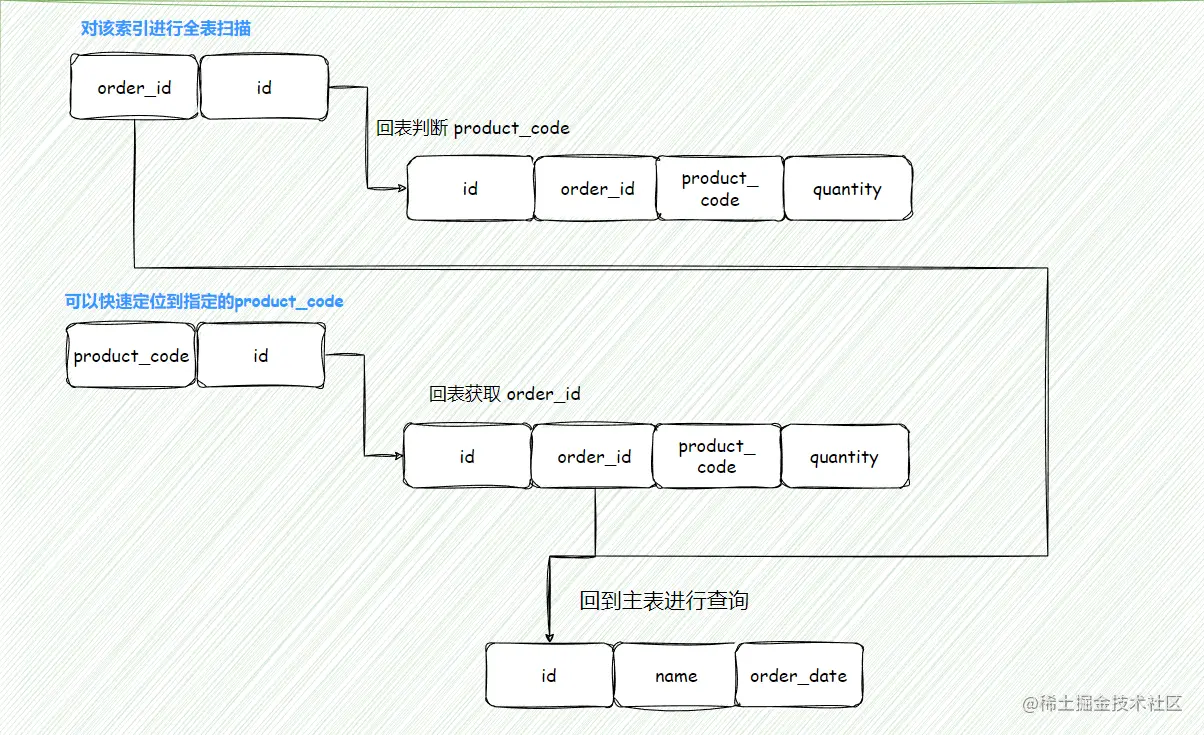
优化4:给 order_id 和 product_code 添加复合索引
优化5:给 product_code 和 order_id 添加复合索引
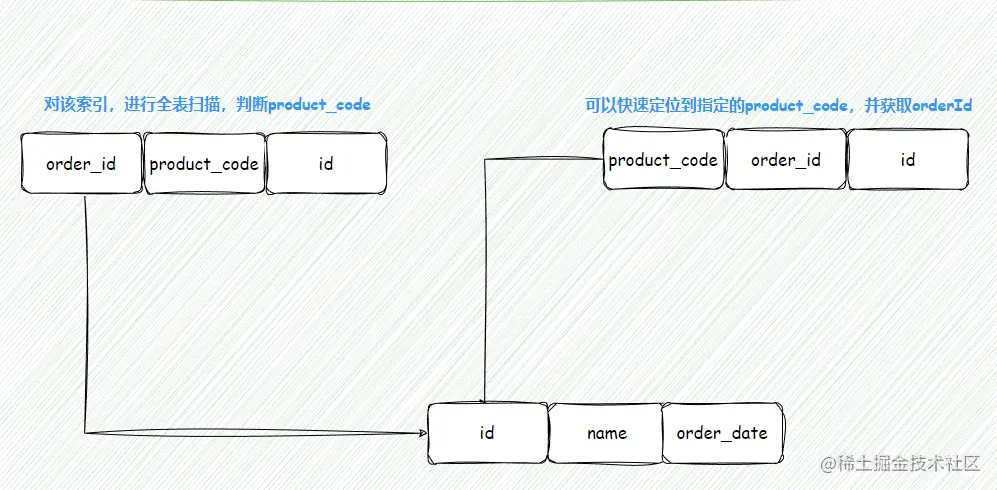
对于复合索引 idx(order_id, product_code),因为查询中需要判断 product_code 的值是否为 PC51,所以要对 order_id 该列进行全索引扫描,性能较低 [ 因为 product_code 不是有序的,先根据 order_id 进行排序,再根据 product_code 进行排序 ];
对于复合索引 idx(product_code, order_id) ,因为 product_code 本身是有序的,所以可以快速定位到该 product_code 然后快速获取该 order_id,性能较高;
待排序的分页查询的优化
现有一个电影表
create table film
(
id integer auto_increment primary key,
score decimal(2, 1) not null,
release_date date not null,
film_name varchar(255) not null,
introduction varchar(255) not null
) comment '电影表';
对于浅分页
select score, release_date, film_name from film order by score limit 0, 20;
耗时 825ms
对于深分页
select score, release_date, film_name, introduction from film order by score limit 1500000, 20;
耗时 1s 247ms
若不加处理,浅分页的速度快,limit 的深度越深,查询的效率越慢
给排序字段添加索引
给 score 字段添加索引
create index idx_score on film(score);
结果
浅分页的速度为 60 ms,深分页的速度为 1s 134ms
浅分页的情况得到了优化,而深分页依然很慢
查看深分页的执行情况

其并没有走 score 索引,走的是全表的扫描,所以给排序字段添加索引只能优化浅分页的情况
解释
只给 score 添加索引,会造成回表的情况

对于浅分页,回表的性能消耗小于全表扫描,故走 score 索引;
对于深分页,回表的性能消耗大于全表扫描,故走 全表扫描;
给排序字段跟 select 字段添加复合索引
给 score, release_date, film_name 添加复合索引
create index idx_score_date_name on film(score, release_date, film_name);
浅分页的速度为 58 ms,深分页的速度为 357 ms,两者的速度都得到了提升
查看深分页的执行情况

可见其走了复合索引
解释
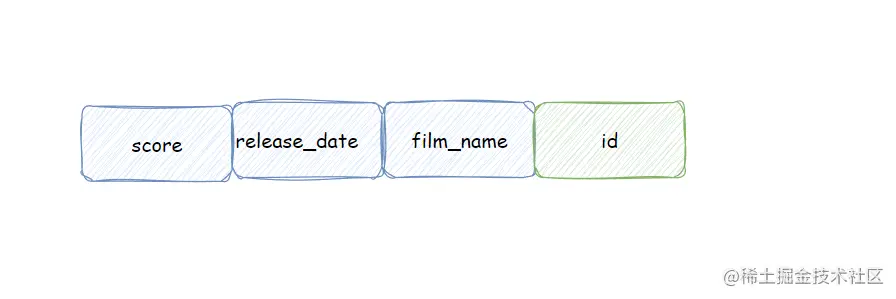
对于该复合索引,排序的值和查询的值都在索引上,没有进行回表的操作,效率很高。唯一的不足是:若要添加新的查询列,就要更改该索引的列,不够灵活。
给排序字段加索引 + 手动回表
改进SQL语句,给 score 字段添加索引
# 给排序字段添加索引 + 手动回表 select score, release_date, film_name,introduction from film a join (select id from film order by score limit 1500000, 20) b on a.id = b.id;
思路:先把 limit 字段的 id 找出来,这里走了 score 索引,效率高。然后再走主键索引根据 id 去寻找;
该语句的执行情况

可见子查询中走了 score 索引,而外查询走了主键索引,效率非常高,执行速度为 297 ms
缺点
由上面的执行计划可见,它创建了一张中间表 ,走的是全表扫描,也就是说,中间表中的记录越多,该执行效率就越慢,观察以下语句,从500000开始查,查找 1500000 条数据;
select score, release_date, film_name,introduction from film a join (select id from film order by score limit 500000, 1500000) b on a.id = b.id;
消耗的时间为:911ms,接近一秒
所以我们可以通过业务的方法,限制每次查询的条数即可
解决办法
- 给排序的字段 + select 的字段添加复合索引
- 给排序的字段加索引 + 手动回表
- 深分页的性能问题可以通过业务方法解决:限制每次查询的数量等
排序优化
索引的字段要根据排序的字段走,且要满足最左匹配原则
create table t_order (
id integer primary key auto_increment,
col_1 int not null ,
col_2 int not null ,
col_3 int not null
)
select * from t_order order by col_1, col_2, col_3, 需要创建联合索引 col_1,col_2,col_3
select * from t_order order by col_1, col_2,需要创建联合索引 col_1, col_2, col_3
select * from t_order order by col_1 asc, col_2 desc ,需要创建联合索引 col_1 asc, col_2 desc ,指定索引的排序规则,只有在 MySQL 8 中才支持
索引失效的情况(避免出现 using filesort)
- 没有遵守最左匹配原则
select * from t_order order by col_1, col_3

select * from t_order order by col_2, col_3

可见都使用到了 ****using filesort
以第一条为例
最左匹配原则的实质是:先根据第一列排序,若第一列的值相同就根据第二列来排序,若第二列的值相同就根据第三列来排序,以此类推;
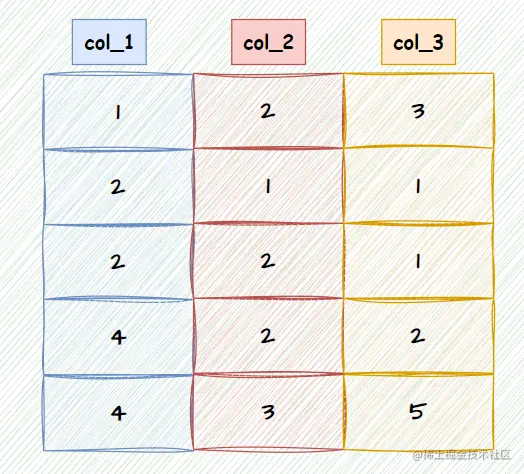
第一条 SQL 中,排序的字段为 col_2 和 col_3 明显 在抛开 col_1 的情况下,col_2 和 col_3 的顺序是无序的,故要使用 using filesort,不能依靠索引来进行排序;
- 使用了范围查询
select * from t_order where col1 >= 1 and col1 <= 4 order by col_2

select * from t_order where col1 in(1,2,4) order by col_2

若走该复合索引 (col_1, col_2, col_3) ,可以发现查询计划中使用到了 using filesort
解释
经过 col_1 的筛选后,col_2 的数据都是无序的
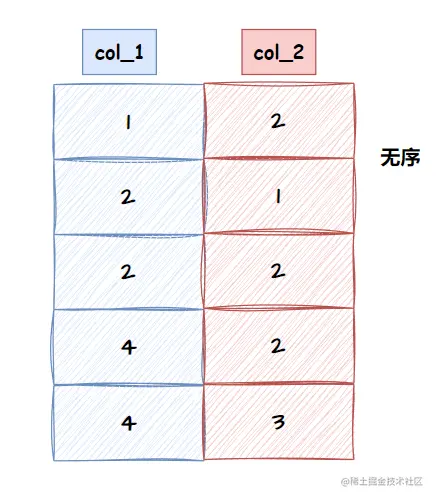
所以要使用 using filesort 再次根据 col_2 排序
若使用等值查询,则不会出现 using filesort,前提是要满足最左匹配原则
select col_1, col_2 from t_order where col_1 = 2 order by col_2;

若不满足 最左匹配原则
select col_1, col_3 from t_order where col_1 = 2 order by col_3;

则使用到了 using filesort
以上就是关于MySQL查询语句的优化详解的详细内容,更多关于MySQL查询语句优化的资料请关注自由互联其它相关文章!