前言
如果存在什么奇怪的问题
1.压缩包放到linux环境下再解压并且不要放共享文件夹里做
2.不建议使用wsl1和wsl2
英文水平有限以及对cache理解命中率优化有限参考了现有网上很多大佬的题解
以及这个实验是有一份ppt的这份ppt里面介绍了两个模拟要用的库函数。
ppt链接http://www.cs.cmu.edu/afs/cs/academic/class/15213-f15/www/recitations/rec07.pdf
PartA
要求我们模拟cache的行为函数写在csim.c里面。
实现以下功能。
Usage: ./csim-ref [-hv] -s -E -b -t • -h: Optional help flag that prints usage info• -v: Optional verbose flag that displays trace info• -s : Number of set index bits (S 2sis the number of sets)• -E : Associativity (number of lines per set)• -b : Number of block bits (B 2bis the block size)• -t : Name of the valgrind trace to replay
刚看到是有点懵逼。
这就是一个字符串的读入读入的内容在文件里面所以要main要重定向进行流输入。getopt
数据的读入
上面的代码部分就是界面。
1.这次实验只要求我们测试hit/miss/eviction的次数并没有实际的数据存储 所以我们不用实现line中的block部分。
2.实验要求使用LRU替换策略
考虑模拟的结构
1.cache的结构体组行块。动态分配空间结束时候释放。
2.读入二进制流后获得本次操作的信息是否打印输出cache的信息每次输入数据的文件
3.初始化完cache后准备输入数据的文件进行cache的处理
4.cache的处理部分有查找命中与不命中以及不命中时候使用LRU替换策略
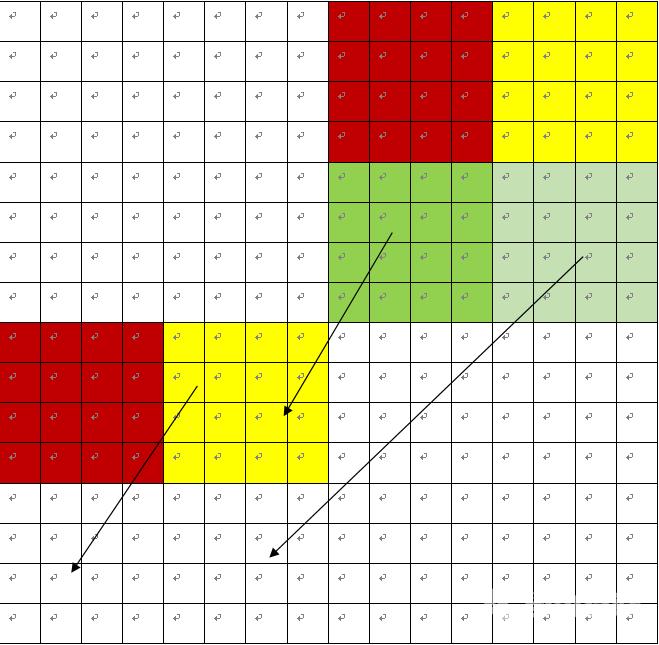
#include "cachelab.h"#include #include #include #include /*要打印的答案*/long long hit_count,miss_count,eviction_count;int output;/*定义cache的结构*/struct Line{int valid;long long s_add;unsigned long LRU_counter;};struct Group{struct Line* lines;};struct Cache{long long s;long long E;long long b;struct Group* groups;};/*初始化cache*/struct Cache initCache(long long s,long long E,long long b){struct Cache cache;cache.ss;cache.EE;cache.bb;long long S1< 挺魔鬼的..感觉没有彻底吃透 图片参考https://www.bilibili.com/read/cv2955433/ 首先做这个题我们需要两张图方便思考。 cache的s5E1b5. 因此这是32X32时候每个int对应到cache中的组索引 因此这是64X64时候的组索引 。 先来考虑32X32. 我们发现一次读掉一行然后进行转置如此进行第一个8X8之后。此时cache【0】存A【0】【0】~A【0】【7】。 再进行处理的时候此时cache【0】cache【8】cache【16】...cache【28】已经存下来了。我们想让命中尽可能多此时可以尝试把第一个8X8的矩阵完成转置。 但是你看到当cache【0】被B覆盖的时候A【0】【0】~A【0】【7】此时就只赋值了一个剩下的抖动掉了。 于是我们尝试用12个变量中的8个来保存这次的A【0】【0】~A【0】【7】这样就不用再去读导致miss了。 因此我们采取8个一块的策略。 可以观察到除了对角线上存在多一点的抖动其他地方主要一次冷不命中。 其结果命中图如下 可以计算出A的miss总数为32*4128 B的miss总数为32*47*4156. 总共为284。 测验得287.说明有函数开销。 void transpose_submit(int M, int N, int A[N][M], int B[M][N]){if(M3232){for (int i 0; i 64X64的情况 我们发现这次4行就是一轮回了沿用上次代码发现miss率非常高。模拟一下第一个8x8的块就发现存在反复抖动的现象。 我们尝试4X4的分块发现将刚才的代码改成4X4能到1699次。其实还是可以的。但是不够优秀。因为我们没有充分利用每次的cache块里面的后面空间。 这里想了挺久不会参考了网上的题解。 图片来源https://blog.csdn.net/weixin_43821874/article/details/86481338 尝试一个折中的办法就是将8*8和4*4相结合。虽然不能直接移动到目的我们可以缓存在一个地方再放进去。 具体如下 首先将红色块移至目的地再将黄色块移至红色块左边“暂存”一下。此时移动是伴随着转置的。 再实现图中的移动即可将黄色块移到红色块的下面在将绿色快移到之前“暂存”黄色块的地方最后将灰色块移动到目的地即可。 模拟这个过程还有一个很重要的细节问题。 结合这张图就能发现。 “再实现图中的移动即可将黄色块移到红色块的下面在将绿色快移到之前“暂存”黄色块的地方最后将灰色块移动到目的地即可。”过程中我们移动黄色上一次已经转置的时候是横着一次性移动过来的而不是竖着对应竖着。因为横着一次就能把此时的cache【0】用完不用再取黄色块了。而如果竖着每次回来还要接着抖动更多的次数。 因此由黄色块横着移过去所以绿色块移动方式也确定下来了。用竖着的一列来填补cache[0]。 这样一来就节省很多了。 最后再把灰色的横着转置过来就行灰色部分提前一步已经在cache中了黄块转移好的时候cache[0],[8],[16],[24]也好了。因此命中率杠杠的。 if(M6464){for(int i0;i 因此我们按照17X17的方式分块。 看来不能完整分块的时候还是要多暴力尝试各种分块方式。 if(N6761){for(int i0;i 这个lab还是比较折磨人的。partA部分只是个开胃小菜让你手动来一个cache。对于LRU的策略优化的时间复杂度还可以优化。不过这是算法部分的策略了不是这个lab的目的。 partB部分是感觉比较难难在考虑的情况不好考虑具体的不命中策略不好计算当然可以用自己做的partA部分和后期拿到的数据来找哪里的不命中来分析。但是感觉过于细节。难度还是在于不命中率的整体思考角度和想法。 同时其中的转移模拟可以手动模拟如果容易晕并且麻烦可以代码输出路径这样更方便模拟更好找路径以及发现时候存在漏移错移。 起码知道几点 1.能整块分的尽量按照整块的大小去分。 2.不能整块的暴力尝试分块大小优化。 3.直接转移的命中率高可以尝试间接转移找到“缓存区”来转移 4.wsl2很坑 以及对cache有了进一步的理解。 PartB