背景
java 8已经发行好几年了前段时间java 12也已经问世但平时的工作中很多项目的环境还停留在java1.7中。而且java8的很多新特性都是革命性的比如各种集合的优化、lambda表达式等所以我们还是要去了解java8的魅力。
今天我们来学习java8的Stream并不需要理论基础直接可以上手去用。
我接触stream的原因是我要搞一个用户收入消费的数据分析。起初的统计筛选分组都是打算用sql语言直接从mysql里得到结果来展现的。但在操作中我们发现这样频繁地访问数据库性能会受到很大的影响分析速度会很慢。所以我们希望能通过访问一次数据库就拿到所有数据然后放到内存中去进行数据分析统计过滤。
接着我看了stream的API发现这就是我想要的。
一、Stream理解
在java中我们称Stream为『流』我们经常会用流去对集合进行一些流水线的操作。stream就像工厂一样只需要把集合、命令还有一些参数灌输到流水线中去就可以加工成得出想要的结果。这样的流水线能大大简洁代码减少操作。
二、Stream流程
原集合 —> 流 —> 各种操作(过滤、分组、统计) —> 终端操作
Stream流的操作流程一般都是这样的先将集合转为流然后经过各种操作比如过滤、筛选、分组、计算。最后的终端操作就是转化成我们想要的数据这个数据的形式一般还是集合有时也会按照需求输出count计数。下文会一一举例。

三、API功能举例
首先定义一个用户对象包含姓名、年龄、性别和籍贯四个成员变量
import lombok.AllArgsConstructor;import lombok.Builder;import lombok.Data;import lombok.NoArgsConstructor;import lombok.extern.log4j.Log4j;DataNoArgsConstructorAllArgsConstructorLog4jBuilderpublic class User {//姓名private String name;//年龄private Integer age;//性别private Integer sex;//所在省市private String address;}
这里用lombok简化了实体类的代码。
然后创建需要的集合数据也就是源数据
//1.构建我们的listList list Arrays.asList(new User("钢铁侠",40,0,"华盛顿"),new User("蜘蛛侠",20,0,"华盛顿"),new User("赵丽颖",30,1,"湖北武汉市"),new User("詹姆斯",35,0,"洛杉矶"),new User("李世民",60,0,"山西省太原市"),new User("蔡徐坤",20,1,"陕西西安市"),new User("葫芦娃的爷爷",70,0,"山西省太原市"));
3.1 过滤
1创建流 stream() / parallelStream()
- stream() : 串行流
- parallelStream: 并行流
2filter 过滤(T-> boolean)
比如要过滤年龄在40岁以上的用户就可以这样写
List filterList list.stream().filter(user -> user.getAge() > 40).collect(toList());
filter里面->箭头后面跟着的是一个boolean值可以写任何的过滤条件就相当于sql中where后面的东西换句话说能用sql实现的功能这里都可以实现
打印结果

3distinct 去重
和sql中的distinct关键字很相似。为了看到效果此处在原集合中加入一个重复的人就选择钢铁侠吧复联4钢铁侠不幸遇害大家还是比较伤心的。
List list Arrays.asList(new User("钢铁侠",40,0,"华盛顿"),new User("钢铁侠",40,0,"华盛顿"),new User("蜘蛛侠",20,0,"华盛顿"),new User("赵丽颖",30,1,"湖北武汉市"),new User("詹姆斯",35,0,"洛杉矶"),new User("李世民",60,0,"山西省太原市"),new User("蔡徐坤”,18,1,"陕西西安市"),new User("葫芦娃的爷爷",70,0,"山西省太原市"));
//distinct 去重List distinctList filterList.stream().distinct().collect(toList());
打印结果

4sorted排序
如果流中的元素的类实现了 Comparable 接口即有自己的排序规则那么可以直接调用 sorted() 方法对元素进行排序如
Comparator.comparingInt
反之, 需要调用 sorted((T, T) -> int) 实现 Comparator 接口。
//sorted()List sortedList distinctList.stream().sorted(Comparator.comparingInt(User::getAge)).collect(toList());
打印结果

结果按照年龄从小到大进行排序。
5limit 返回前n个元素
如果想知道这里面年龄最小的是谁可作如下操作
//limit 返回前n个元素List limitList sortedList.stream().limit(1).collect(toList());
6skip()
与limit恰恰相反skip的意思是跳过也就是去除前n个元素。
打印结果

果然前两个人都被去除了只剩下最老的葫芦娃爷爷。
3.2 映射
1map(T->R)
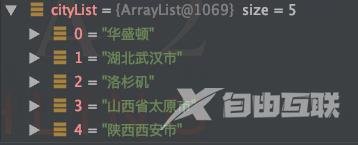
map是将T类型的数据转为R类型的数据比如我们想要设置一个新的list存储用户所有的城市信息。
//map(T->R)List cityList list.stream().map(User::getAddress).distinct().collect(toList());
打印结果
2flatMap(T -> Stream)
将流中的每一个元素 T 映射为一个流再把每一个流连接成为一个流。
//flatMap(T -> Stream)List flatList new ArrayList();flatList.add("唱,跳");flatList.add("rape,篮球,music");flatList flatList.stream().map(s -> s.split(",")).flatMap(Arrays::stream).collect(toList());
打印结果
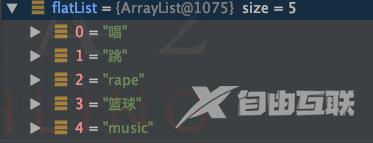
这里原集合中的数据由逗号分割使用split进行拆分后得到的是Stream字符串数组组成的流要使用flatMap的
Arrays::stream将Stream转为Stream,然后把流相连接组成了完整的唱、跳、rap、篮球和music。
3.3 查找
1allMatchT->boolean
检测是否全部满足参数行为假如这些用户是网吧上网的用户名单那就需要检查是不是每个人都年满18周岁了。
boolean isAdult list.stream().allMatch(user -> user.getAge() > 18);
打印结果
true
2anyMatchT->boolean
检测是否有任意元素满足给定的条件比如想知道同学名单里是否有女生。
//anyMatch(T -> boolean 是否有任意一个元素满足给定的条件boolean isGirl list.stream().anyMatch(user -> user.getSex() 1);
打印结果
true
说明集合中有女生存在。
3noneMatch(T -> boolean)
流中是否有元素匹配给定的 T -> boolean 条件。
比如检测有没有来自巴黎的用户。
boolean isLSJ list.stream().noneMatch(user -> user.getAddress().contains("巴黎"));
打印结果
true
打印true说明没有巴黎的用户。
4findFirst( ):找到第一个元素
Optional fristUser list.stream().findFirst();
打印结果
User(name钢铁侠, age40, sex0, address华盛顿)
5findAny():找到任意一个元素
Optional anyUser list.stream().findAny();
打印结果
User(name钢铁侠, age40, sex0, address华盛顿)
这里我们发现findAny返回的也总是第一个元素那么为什么还要进行区分呢因为在并行流 parallelStream() 中找到的确实是任意一个元素。
Optional anyParallelUser list.parallelStream().findAny();
打印结果 :
Optional[User(name李世民, age60, sex0, address山西省太原市)]
3.4 归纳计算
1求用户的总人数
long count list.stream().collect(Collectors.counting());
我们可以简写为
long count list.stream().count();
运行结果
8
2得到某一属性的最大最小值
// 求最大年龄Optional max list.stream().collect(Collectors.maxBy(Comparator.comparing(User::getAge)));// 求最小年龄Optional min list.stream().collect(Collectors.minBy(Comparator.comparing(User::getAge)));
运行结果
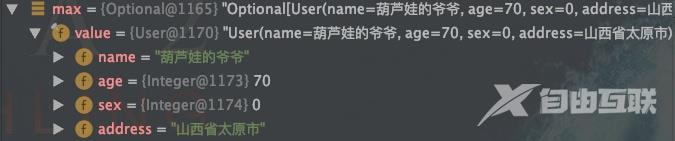
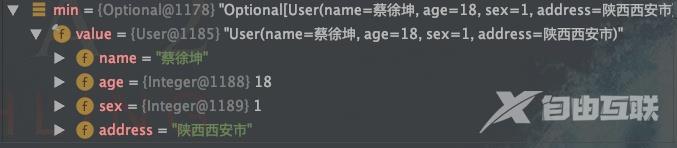
3求年龄总和是多少
// 求年龄总和int totalAge list.stream().collect(Collectors.summingInt(User::getAge));
运行结果
313
我们经常会用BigDecimal来记录金钱假设想得到BigDecimal的总和
// 获得列表对象金额 使用reduce聚合函数,实现累加器BigDecimal sum myList.stream() .map(User::getMoney).reduce(BigDecimal.ZERO,BigDecimal::add);
4求年龄平均值
//求年龄平均值double avgAge list.stream().collect(Collectors.averagingInt(User::getAge));
运行结果:
39.125
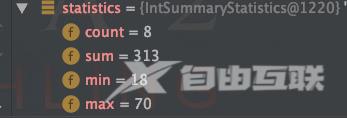
5一次性得到元素的个数、总和、最大值、最小值
IntSummaryStatistics statistics list.stream().collect(Collectors.summarizingInt(User::getAge));
运行结果
6字符串拼接
要将用户的姓名连成一个字符串并用逗号分割。
String names list.stream().map(User::getName).collect(Collectors.joining(", "));
运行结果
钢铁侠, 钢铁侠, 蜘蛛侠, 赵丽颖, 詹姆斯, 李世民, 蔡徐坤, 葫芦娃的爷爷
3.5 分组
在数据库操作中我们经常通过GROUP BY关键字对查询到的数据进行分组java8的流式处理也提供了分组的功能。使用Collectors.groupingBy来进行分组。
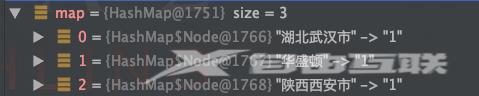
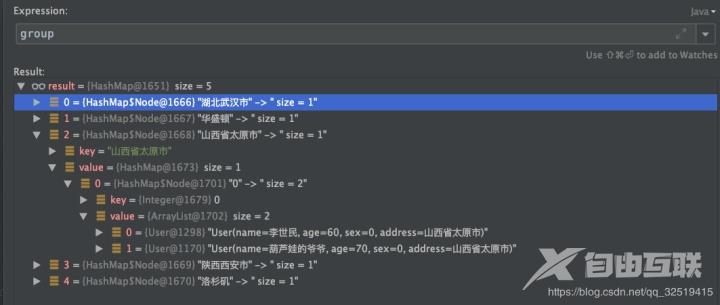
1可以根据用户所在城市进行分组
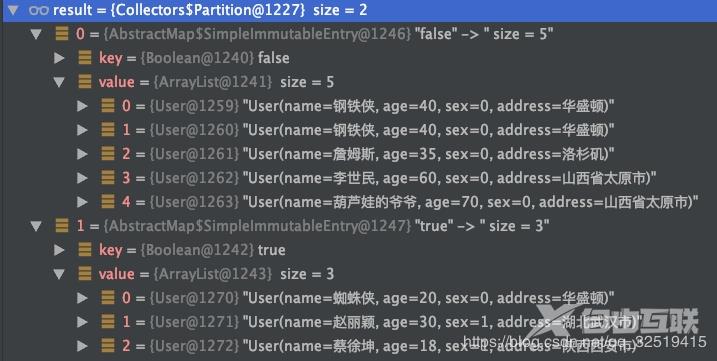
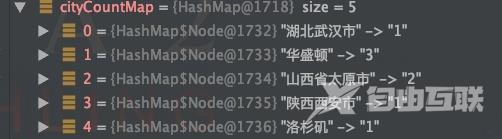
Map 结果是一个mapkey为不重复的城市名value为属于该城市的用户列表。已经实现了分组。 Map 运行结果 按城市分组并统计人数 Map cityCountMap list.stream().collect(Collectors.groupingBy(User::getAddress,Collectors.counting())); 运行结果 Map map list.stream().filter(user -> user.getAge() < 30).collect(Collectors.groupingBy(User::getAddress,Collectors.counting())); 运行结果 5partitioningBy 分区 分区与分组的区别在于分区是按照 true 和 false 来分的因此partitioningBy 接受的参数的 lambda 也是 T -> boolean //根据年龄是否小于等于30来分区Map 运行结果 总结 到目前为止stream的功能我们已经用了很多了感觉有点眼花缭乱却无所不能stream能做的事情远远不止这些。 我们可以多学习使用stream把原来复杂的sql查询一遍又一遍地for循环的复杂代码重构让代码更简洁易懂可读性强。 拓展阅读Redis专题1构建知识图谱 Redis专题(2)Redis数据结构底层探秘 作者杨亨 来源宜信技术学院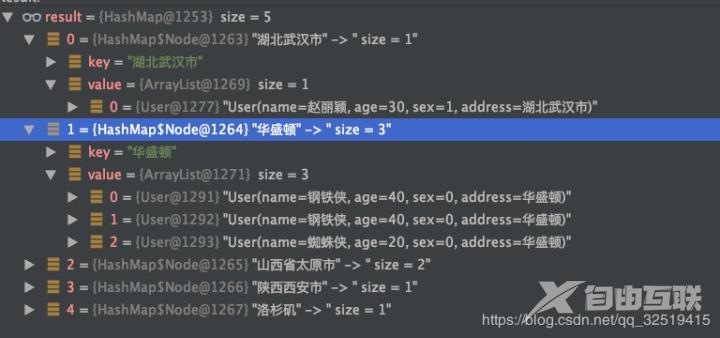
2二级分组先根据城市分组再根据性别分组
3如果仅仅想统计各城市的用户个数是多少并不需要对应的list
4当然也可以先进行过滤再分组并统计人数