小时候乡愁是一枚小小的邮票你在这头我在那头
长大后乡愁是一张核酸证明你在家里我在隔离
一、python读取机制在学习Pytorch的数据读取之前我们得先回顾一下这个数据读取到底是以什么样的逻辑存在的 我们知道机器模型学习的五大模块分别是数据模型损失函数优化器迭代训练。而这里的数据读取机制很显然是位于数据模块的一个小分支下面看一下数据模块的详细内容
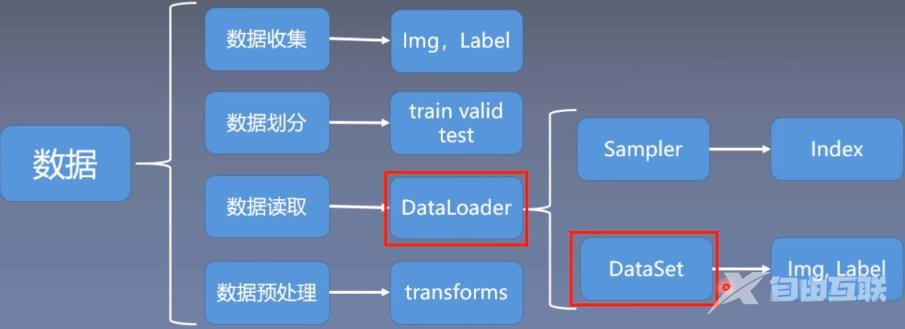
数据模块中又可以大致分为上面不同的子模块 而今天学习的DataLoader和DataSet就是数据读取子模块中的核心机制。 了解了上面这些框架有利于把知识进行整合起来到底学习的内容属于哪一块。下面正式开始DataLoader和Dataset的学习。
二、Dataloadertorch.utils.data.DataLoader(): 构建可迭代的数据装载器, 我们在训练的时候每一个for循环每一次iteration就是从DataLoader中获取一个batch_size大小的数据的。

DataLoader的参数很多但我们常用的主要有5个
dataset: Dataset类 决定数据从哪读取以及如何读取 bathsize: 批大小 num_works: 是否多进程读取机制 shuffle: 每个epoch是否乱序 drop_last: 当样本数不能被batchsize整除时 是否舍弃最后一批数据
三、Datasettorch.utils.data.Dataset(): Dataset抽象类 所有自定义的Dataset都需要继承它并且必须复写__getitem__()这个类方法或__get_sample__())。

__getitem__方法的是Dataset的核心作用是接收一个索引 返回一个样本 看上面的函数参数里面接收index然后我们需要编写究竟如何根据这个索引去读取我们的数据部分。
train函数是模型训练的入口。首先一些变量的更新采用自定义的AverageMeter类来管理然后model.train()是设置为训练模式。 for i, (input, target) in enumerate(train_loader) 是数据迭代读取的循环函数具体而言当执行enumerate(train_loader)的时候是先调用DataLoader类的__iter__方法该方法里面再调用DataLoaderIter类的初始化操作__init__。而当执行for循环操作时调用DataLoaderIter类的__next__方法在该方法中通过self.collate_fn接口读取self.dataset数据时,就会调用TSNDataSet类的__getitem__方法从而完成数据的迭代读取。读取到数据后就将数据从Tensor转换成Variable格式然后执行模型的前向计算output model(input_var)损失函数计算 loss criterion(output, target_var)准确率计算 prec1, prec5 accuracy(output.data, target, topk(1,5))模型参数更新等等。其中loss.backward()是损失回传 optimizer.step()是模型参数更新。
参考https://blog.csdn.net/wuzhongqiang/article/details/105499476
https://blog.csdn.net/rytyy/article/details/105944813
来源:深度科研
【本文来自:台湾服务器 http://www.558idc.com/tw.html 复制请保留原URL】