
空间测绘
一、简介
Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务:DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
Flink是一个纯流式计算引擎,而类似于Spark这种微批的引擎,只是Flink流式引擎的一个特例。
二、简单分析
1. 任意读
org.apache.flink.runtime.rest.handler.router.RouterHandler#channelRead0 部分代码如下
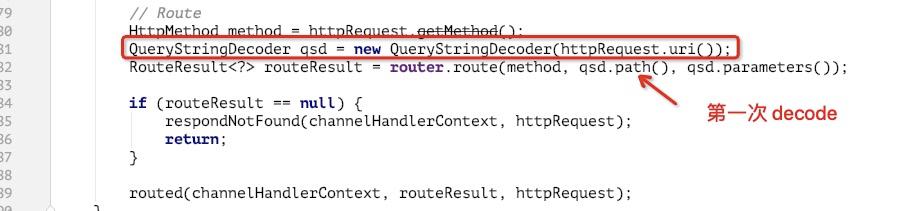
进入箭头所指 org.apache.flink.runtime.rest.handler.router.Router#route(org.apache.flink.shaded.netty4.io.netty.handler.codec.http.HttpMethod, java.lang.String, java.util.Map

如上,红框部分会将 path 利用 / 切割成 tokens,注意这里 tokens 是经过了两次 decode 的(在path被切割成tokens时进行第二次decode),而 path 只经过一次 decode,后续会利用 path 进行路由匹配,由于进行了两次 url 编码,所以路由可以正常匹配到 org.apache.flink.runtime.rest.handler.cluster.JobManagerCustomLogHandler,否则将匹配到 org.apache.flink.runtime.rest.handler.legacy.files.StaticFileServerHandler
虽然 StaticFileServerHandler 也能读文件,但是会有跨文件读的 check
最后查看 org.apache.flink.runtime.rest.handler.cluster.JobManagerCustomLogHandler#getFile 代码如下

如上图,filename 是直接从 tokens 中取出,直接拼接到 logDir 父目录下,由于 token 经过 2 次 url 解码,所以能够正常获取到 ../../ ,从而进行跨目录读
2. 任意写
触发点在 org.apache.flink.runtime.rest.FileUploadHandler#channelRead0 ,部分函数如下

如上图,fileUpload 是用户可控的内容,则 filename 也是可控的,所以可以修改 filename 进行跨目录写操作
3. 反序列化
触发点在 org.apache.flink.runtime.rest.handler.job.JobSubmitHandler#loadJobGraph:
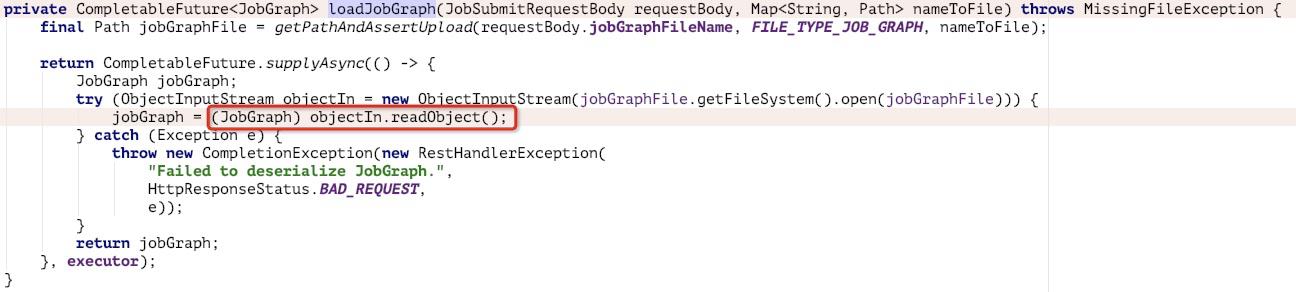
如上,当以 post 方式访问到 /v1/jobs 时,会路由到此,简单查看逻辑发现会将我们上传到文件内容进行反序列化操作
三、鸡肋的反序列化
背景:
已知 apache flink 没有后端模板渲染的功能,前端的模板是通过 nodejs 静态编译得到,如果想要以任意文件写入的方式去修改模板文件,需要重新编译并且重启服务器才能 RCE。flink 中虽然有 plugins 功能,但是不支持热拔插,plugins 中的 jar 包只会在服务启动时被加载一次。最后还有一个功能就是上传 jar 包并且动态执行,但是这是系统的正常功能,不在恶意利用考虑范围内
任意文件写:在 flink 中不能直接 RCE,大都需要重启服务
反序列化:flink 自身依赖非常少,公开已知的 gadgets 全部失效
破局:
从 反序列化入手,重新挖掘针对 flink 的 gadgets,发现 flink 中存在自己实现的反序列化逻辑,并且可以通过 readObject 函数从 jdk 原生反序列化跳到它自实现的反序列化逻辑中,见 org.apache.flink.api.common.state.StateDescriptor#readObject 函数:
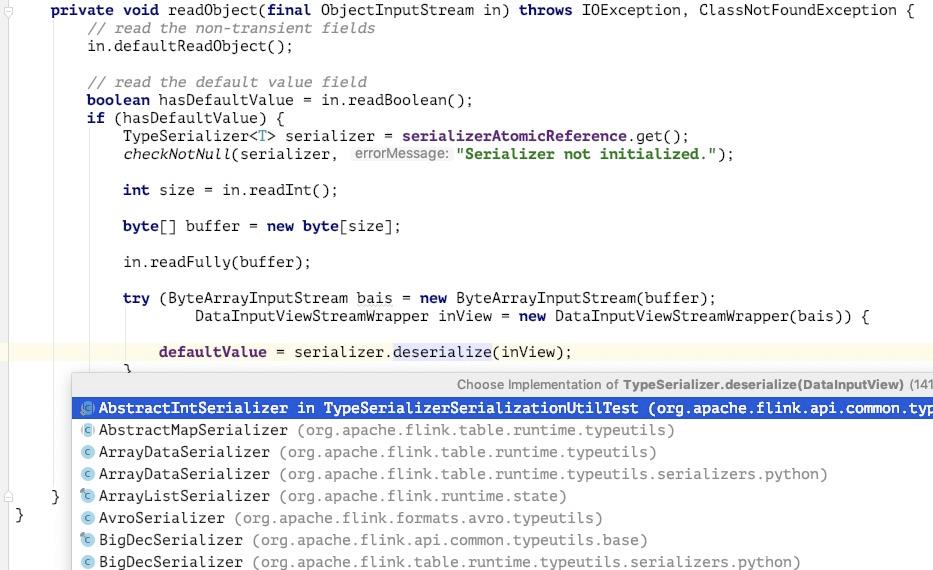
如上图,会有一个 deserialize 函数的调用,查看了一下实现类,非常多
其中找到个类:PojoSerializer,其 deserialize 函数部分如下:
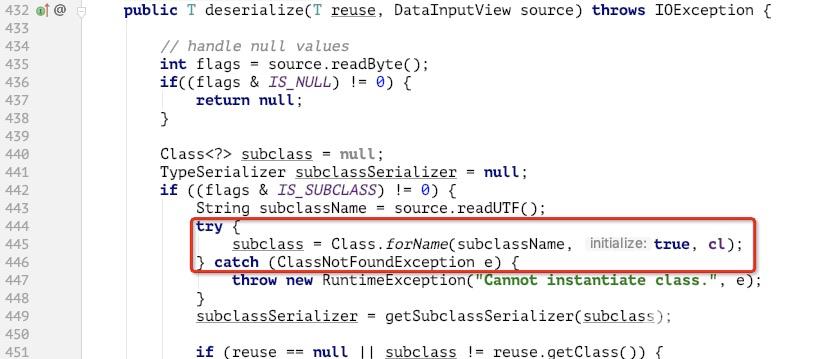
如上图,经过仔细分析其功能逻辑,发现是通过反射直接进行属性值填充,所以无法再跳到 getter/setter 调用逻辑中,但是发现上图红框部分,存在类加载调用,且第二参数为 true (会执行类初始化,调用 static 代码块)
于是转变思路,先上传恶意 class 文件,然后触发 jdk 反序列化,最后利用它自实现的反序列化功能,加载恶意 class 文件
首先需要去验证,系统启动时 classpath 是否存在目录(非 jar 文件路径),启动 classpath 参数如下

如上图,能够看出是直接加载了所有的 /lib 目录下的 jar 文件,但是后面存在 三个 : ,猜测可能会将程序启动目录作为 classpath
动态调试如下:
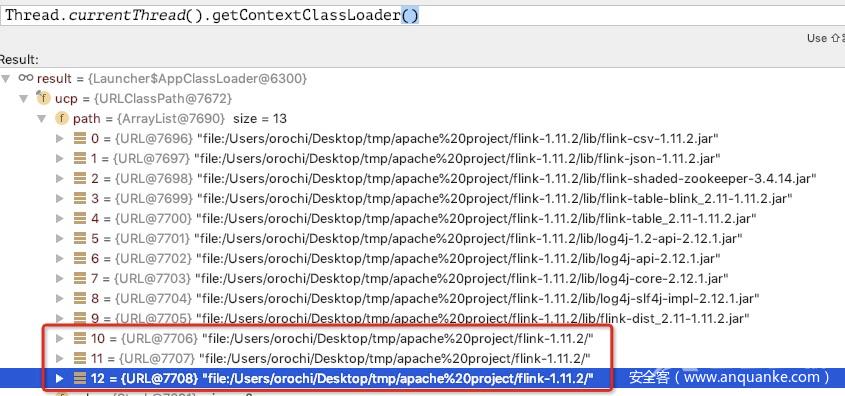
如上图,证明猜测正确,系统自动将程序启动目录(根目录)作为了一个类加载路径。
所以可以将恶意 class 写入 flink-1.11.2/ 目录,然后经过反序列化去加载 class ,从而进行 RCE
四、总结
任意读过程中的两次 urldecode 比较有意思,第一次decode产生 path,path 再次decode并切割产生tokens,path 会被当作路由进行匹配,而tokens会被当作最终的函数参数。
反序列化更是鸡肋,但是从上文中也能发现,虽然现在通用反序列化gadgets越来越不好用,但是由于程序自身需要,还是会涉及到很多反序列化场景,所以针对性的gadgets挖掘很有必要,在漏洞挖掘的时候应该让思路更活跃一些,就会发现更多有意思的东西
flink 本身是没有鉴权的,并且它本身支持任意jar包上传并执行,所以需要严格控制其网络访问权限,目前任意文件读写都已经在最新版修复