1.简介排序学习LearningtorankLTR或者机器学习排序machine-learnedrankingMLRLTR或者机器学习排序machine-learned rankingMLR是应用机器学习技术来构造信息检索系统的排序模型 训练数据包含每个列表中的
训练数据包含每个列表中的项目的某种偏序关系的项目列表。这种偏序可以按照数值或者序数分值或者二元判断来确定。
排序模型的目标学习训练集中的排序方式对未来的数据进行排序
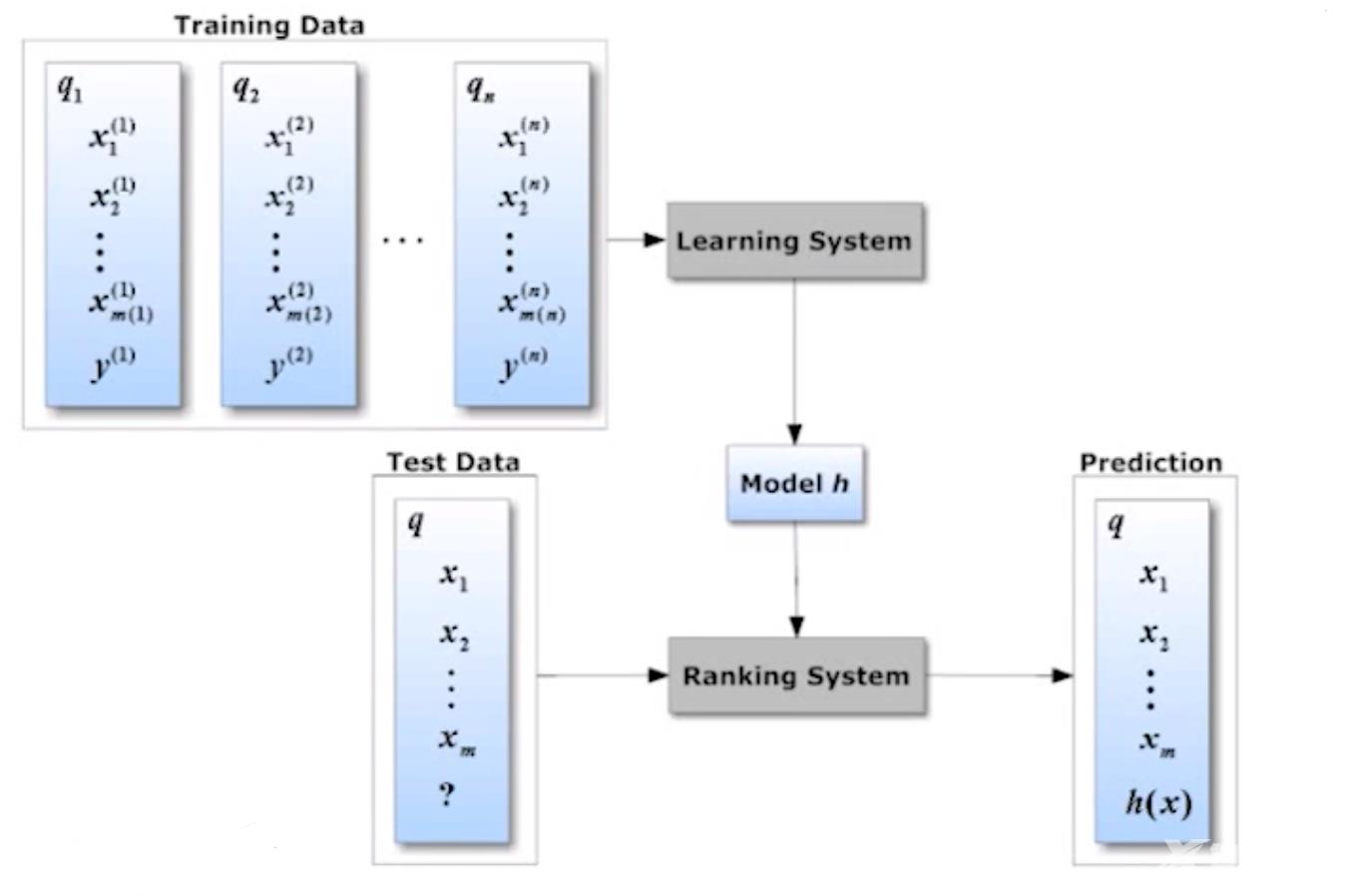
排序学习实际上是一类监督学习问题训练数据 包含查询和文档相关性的分数
- 查询集合Q{q1,⋯,qm}Q\{q_1,\cdots,q_m\}Q{q1,⋯,qm}
- 文档集合DDD
- 与第iii个查询相关的文档Di{di,1,⋯,di,ni}D_i\{d_{i,1},\cdots,d_{i,n_i}\}Di{di,1,⋯,di,ni}
- 相关性分数的向量:yi{yi,1,⋯,yi,ni}y_i\{y_{i,1},\cdots,y_{i,n_i}\}yi{yi,1,⋯,yi,ni}对每个与查询iii相关的文档 目标给定新的查询qqq输出排好序的相关文档的列表
2.常用排序学习的分类
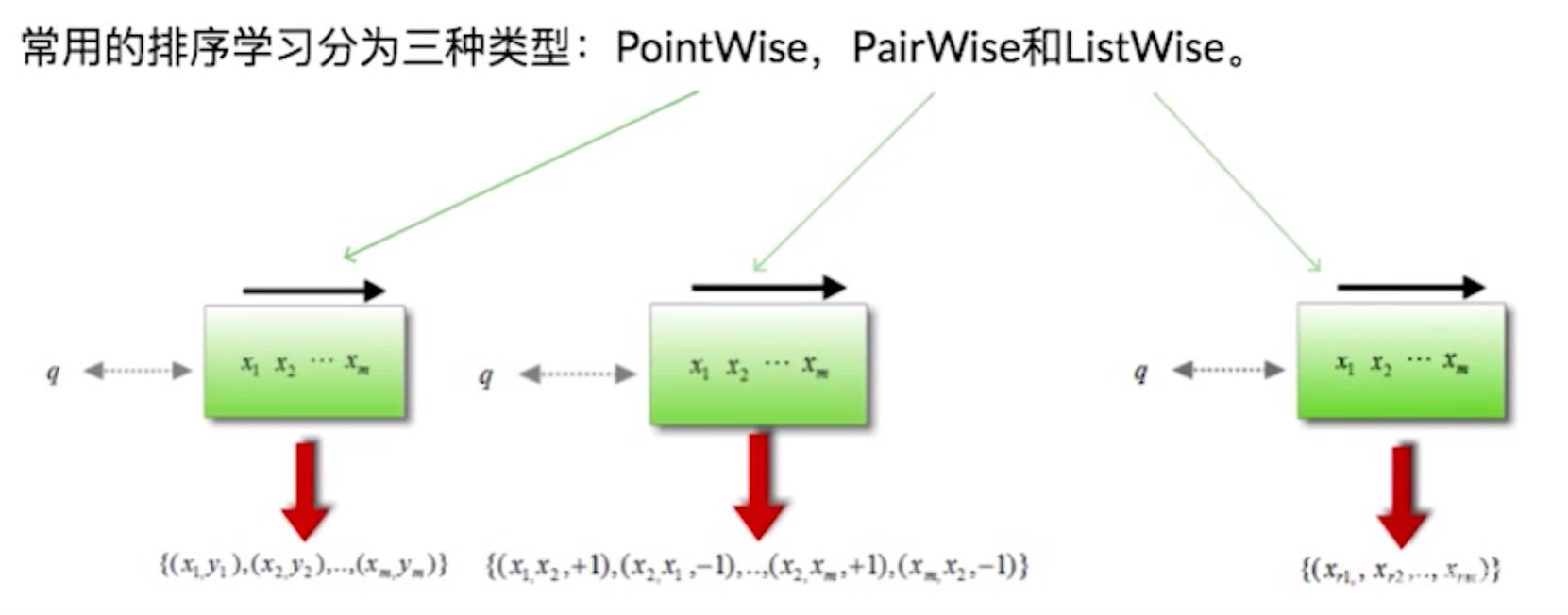
2.1 PointWise排序学习
 Pointwise的优点直接支持已有的回归或者分类的理论和算法 Pointwise的缺点文档的信息次序并不能在训练时使用因为算法接受单个文档作为输入。分类角度计算假设相关度是查询无关的只要(qi,di)(q_i,d_i)(qi,di)的相关度相同那么他们就被划分到同一个级别中属于同一类。 文档次序信息的丢失就导致pointwise方法会在不重要的文档上过度强调对于预测为同一label级别的文档之间也无法相对排序。
Pointwise的优点直接支持已有的回归或者分类的理论和算法 Pointwise的缺点文档的信息次序并不能在训练时使用因为算法接受单个文档作为输入。分类角度计算假设相关度是查询无关的只要(qi,di)(q_i,d_i)(qi,di)的相关度相同那么他们就被划分到同一个级别中属于同一类。 文档次序信息的丢失就导致pointwise方法会在不重要的文档上过度强调对于预测为同一label级别的文档之间也无法相对排序。
2.2 PairWise排序学习
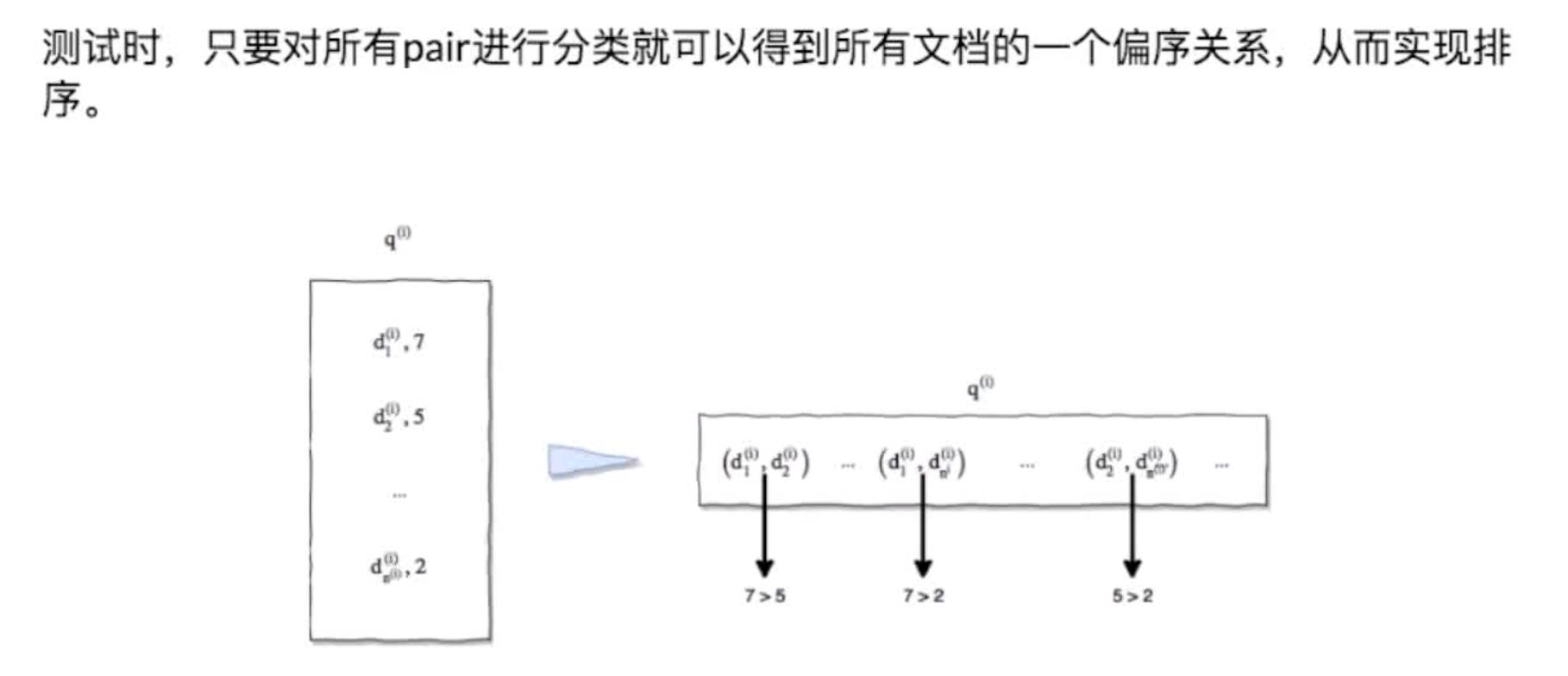
核心思想对于每个查询的文档排序对应于文档的排列如果我们知道文档对的相对次序那么最终就能恢复出整个排列
实际上针对文档对可以设计出排序问题的二分类形式。可以使用常用的机器学习方法如Boost、SVM、神经网络等来解决。 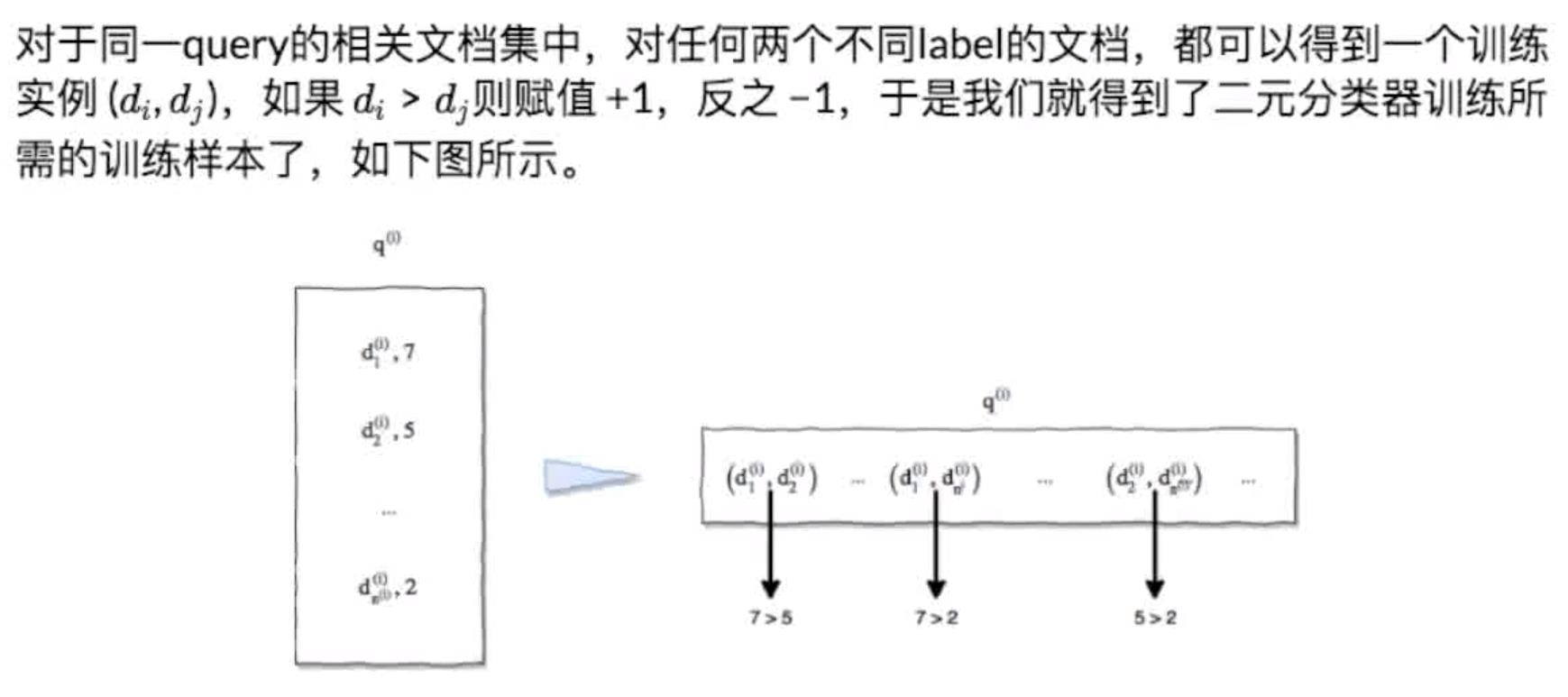


2.3 ListWise排序学习




