《Linux内存管理ARM64体系结构与编程之cache1》
《Linux内存管理ARM64体系结构与编程之cache2》
《ARM SMMU原理与IOMMU技术“VT-d” DMA、I/O虚拟化、内存虚拟化》
《内核引导参数IOMMU与INTEL_IOMMU有何不同》
《提升KVM异构虚拟机启动效率透传(pass-through)、DMA映射VFIO、PCI、IOMMU、virtio-balloon、异步DMA映射、预处理》
目录
为什么系统软件人员要深入了解cache
inner share和outer share
PoU和PoC的区别
神马是PoU- 统一点
神马是PoC- 一致性点
PoC(一致性点)和PoU(统一点)的区别
Cache维护指令
Cache指令格式
为什么要cache一致性
ARM的cache一致性的演进路线
系统cache一致性问题
cache一致性的解决方案
第一种方案关闭cache
第二种方案软件管理cache一致性
第三种方案硬件管理cache一致性
为什么系统软件人员要深入了解cache
在一个系统中cache无处不在对于一个系统编程人员来说你无法躲藏。下图是一个经典的ARM64系统的架构图由Corte-A72和Cortex-53组成了大小核架构每个CPU核心都有L1 cache每个cluster里共享一个L2 cache另外还有Mali GPU和DMA外设。

对于系统软件人员下面几个常常疑惑的问题
所以Cache这个玩意对我们系统编程人员来说非常重要。Cache没有理解好或者没有完全搞透了对系统编程影响很大有时候我们在编程的时候一行代码小小的改动可能会影响整个系统的性能所以我是建议系统程序员有必要把cache这玩意好好系统的学一学。
笨系列文章主要源自第三季《arm64体系结构与编程》视频课程大概会有上下两篇
上篇介绍cache相关的背景知识例如什么是cachecache的layout结构图cache的层级VIPT/PIPT/VIVTcache的重名和同名问题cache的策略等。
中篇主要介绍ARM特有的inner share和outer share的概念以及神马是PoU和PoC还有cache指令的格式。为什么会有cache一致性问题arm公司对cache一致性问题的解决方案的演进。cache一致性问题业界常用的解决方案。
下篇主要介绍MESI协议怎么去看MESI协议状态图DMA和cache之间的cache一致性问题self-modifying code导致的I-cache和D-cache的一致性问题cache伪共享等问题。
inner share和outer share
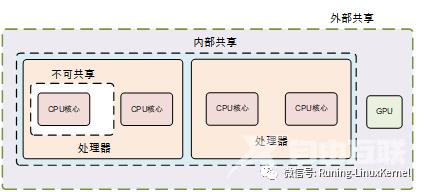
Inner 和outer shareability是arm提出来的概念。很重要的一点大家先要知道也就是只有normal memory的内存属性的内存才能设置inner 和outer shareabilitydevice memory是不能设置shareability的。
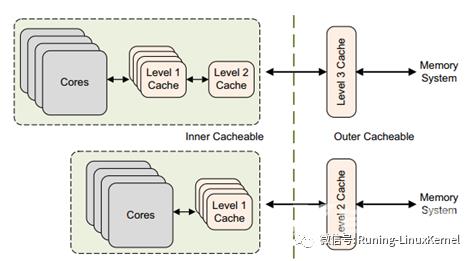
怎么去区分inner share还是outer share呢arm手册里讲了不同的SOC设计有不同的区分方法不过有一个通用的规则inner share通常是CPU IP集成的caches包括CPU IP集成的L1 data cache和L2 cache而outer share是通过总线连接到cache比如外接的L3 cache等。
下面这个图比较直观。这个图虚线分成了两部分左边都是inner share右边都是outershare。左边表示是CPU IP集成的cache上面的cores集成了L1和L2cache而下面的core集成了L1 cache那虚线框出来的都是inner share。我们再来看虚线左边通过总线外接了L2 cache或者L3 cache这边都是outer share。
在armv8.6手册里在B2.7.1章里有一段话对inner share和outer share描述。

在这里的example B2-1里举了一个例子说在一个在一个2 cluster的系统
每一个cluster里数据cache和unified cache都是inner shareable
两个cluster之间变成了outer shareable 这个系统里每一个cluster都是一个不同的inner share但是整个系统是一个outer share。
在Programmer guide第11.3章里也有一段话描述inner和outer说的比较接地气。

PoU和PoC的区别
下面来介绍一下arm定义的两个重要的概念一个是POCPoC的英文全称为Point of Coherency 一个是PoU英文全称为Point of Unification。
神马是PoU- 统一点
PoU: 表示一个CPU中的指令cache数据cache还有MMUTLB等看到的是同一份的内存拷贝。
PoU for a PE是说保证PE看到的I/D cache和MMU是同一份拷贝。大多数情况下PoU是站在单核系统的角度来观察的。
PoU for inner share意思是说在inner share里面的所有CPU核心都能看到相同的一份拷贝。
所以PoU有两个观察点一个是poc for a PEPE就是cpu core另外一个是POU for inner share。关于pou的描述在armv8.6手册的第D4.4.7章里有详细的描述。

其中它里面举了一个例子说self-modifing code在pou for inner里使用下面两条简单的指令就能保证data cache和指令cache的一致性。如果不是pou for inner要保证data cache和指令cache的一致性需要额外的memory barrier的指令。
神马是PoC- 一致性点
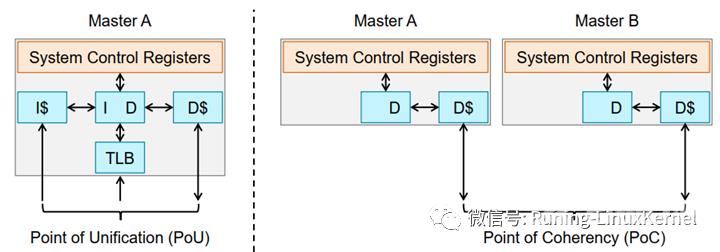
PoC系统中所有的观察者例如DSP, GPU,CPU, DMA等都能看到同一份内存拷贝。

我们来这个图左边那个图就是一个单一的一个mastermaster可以是CPUgpudma等有能力访问内存的设备。那么在单一的master系统里这些指令cache数据cacheTLB等都可以看成是POU因为在这个单一的master眼里他们都是同一份拷贝。我们来看一下右边这个图这个图里有两个master。那么在masterA和master B眼里他们要看到同一份拷贝的话需要masterA和masterB进行cache一致性这个观察角度就是POC。
PoC(一致性点)和PoU(统一点)的区别
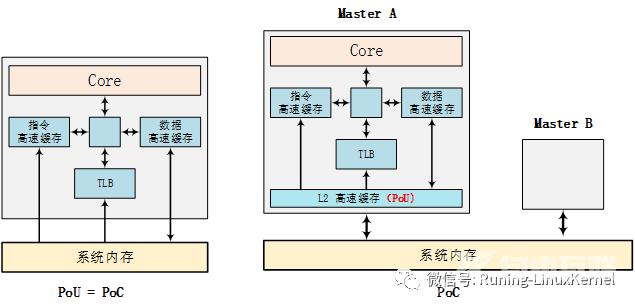
我们来看一下pou和poc的区别最大的一个区别就是poc是系统一个概念和系统配置相关它包含了系统所有有能力访问内存的设备包括cpugpudma等这些都称为observer观察者。 而pou是个局部的概念。还有一点大家需要注意系统配置的不同可能会影响pou的范围我们举个例子在Cortex-A53可以配置L2 cache和没有L2 cache可能会影响PoU的范围为什么会这样因为我们支持pou有一个重要的观察点就是pou for inner share而inner share的划分和 这个cache是不是 CPU IP集成有关。
比如下面这个图左边没有集成L2 cache那么这时候POU等于了POC而且也没有其他的master。右边那个图CORE里集成了L2 cache那么coreL1 cache和L2 cache构成了POU for inner而master a和master b和系统内存构成了poc。
Cache维护指令
接下来我们来看cache维护。前面我们讲了一大通关于cache的背景知识接下来介绍的cache的维护这里说的维护是指的手工维护也就是软件干预cache的行为。
Armv8里定义的Cache的管理的操作有三种
对高速缓存的操作可以指定不同的范围。
另外在ARMv8架构中最多可以支持7级的高速缓存L1L7高速缓存。当对一个高速缓存行进行操作时我们需要知道高速缓存操作的范围。ARMv8架构中从处理器到所有内存的角度分成如下几个视角。
Cache指令格式
下面来讲一下cache的指令格式armv8里提供了两条cache相关的指令一条是指令cache的管理指令就叫做IC其实就是instruction cache的简称。另外一条是data cache的管理指令叫做DCC其实就是data cache的简称。
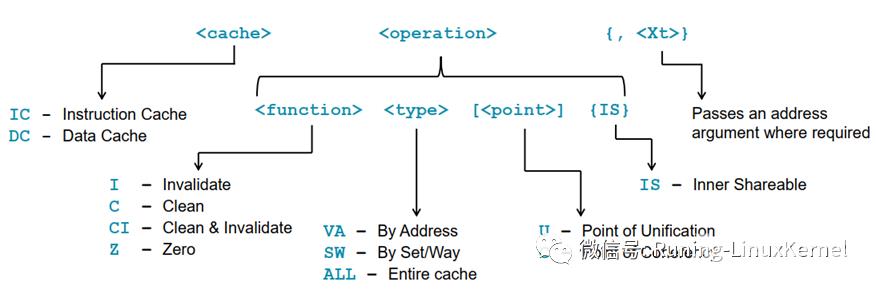
指令的有两部分组成一个是operation另外一个是xt表示参数。Operation可以4个部分分别是function就是你要操作的功能是啥我们前面讲了cache管理的三大功能一个是invalidate第二个是clean第三个zero第一个和第二个可以合起来就是clean 就是我先把cache flush回内存然后我再无效它。第二部分是类型typeVA表示要操作的地址sw表示路和组all表示整个cache。第三部分是point就是我们说的管理cache的观察点或者说范围是POU还是POCPOU和POC的范围是不一样的我们前面讲过。第4部分是IS表示是否包括inner shareable。这里POU和inner share可以合在一起的。 最后一个参数可以传递一些参数比如你需要传递地址给这条指令。
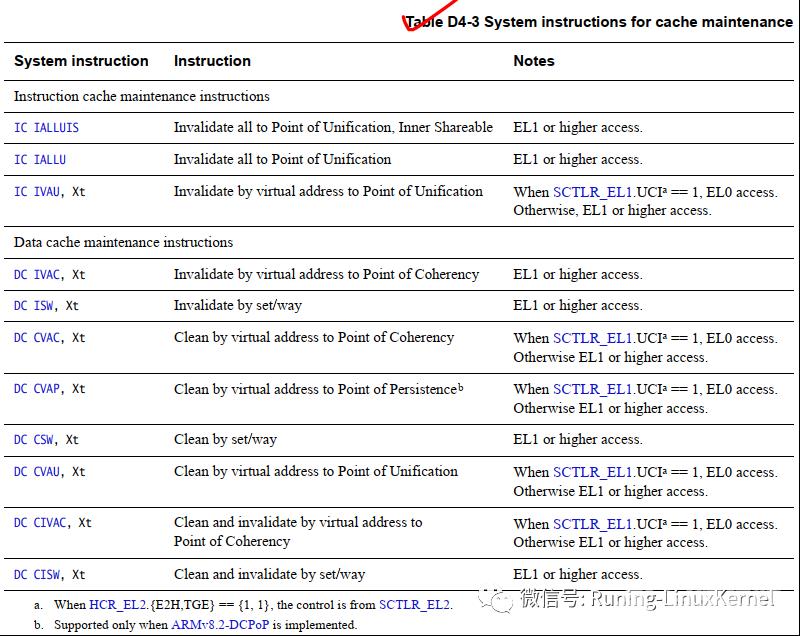
下面这个表就是 armv8里支持的cache管理指令我这里简单给大家翻译了。

大家可以去看armv8.6手册的D4.4.8章的D4-3这个表这是最权威的。
为什么要cache一致性
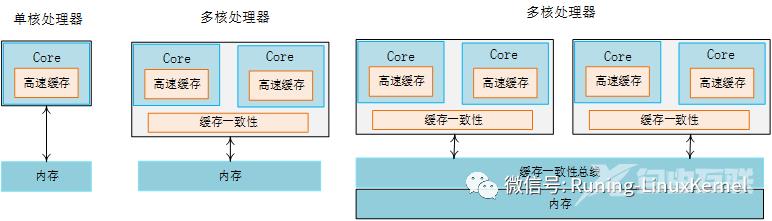
为什么要有cache一致性或者说cache一致性这个问题是怎么产生的。要了解这个问题我们需要从单核cpu进化到多核处理器这个过程开始说起。以arm为例在cortex-a8其实都是单核处理器到了cortex-a9之后就有了多核处理器不过准确来讲在ARM11的时候也有多核不过那时候的多核还不是很成熟。在多核处理器里每个核心都有自己L1 cache多核之间可能共享一个L2的cache等等。以这个图为例core0有自己的L1 cachecore1有自己的L1 cahe然后才是内存。那么当core0 先访问一个地址然后把这个地址的数据加载到它自己的cache里那么这时候如果core1 也想要这个数据它应该怎么办呢它是应该也从内存中去读还是去问core0 要数据呢所以这种情况下就产生了cache一致性问题。

cache一致性关注的是同一个数据在多个高速缓存和内存中的一致性问题解决高速缓存一致性的方法主要是总线监听协议例如MESI协议等。所以我们这节课很重要一点是和大家去介绍MESI协议。
我们做系统软件的为啥要去关注cache一致性呢虽然刚才提到的MESI协议对软件是透明的也就是说完全是硬件实现的但是在有些场景下需要软件手工来干预。下面举几个例子。
ARM的cache一致性的演进路线
我们来看一下ARM的cache一致性的演变。这张图比较有意思。
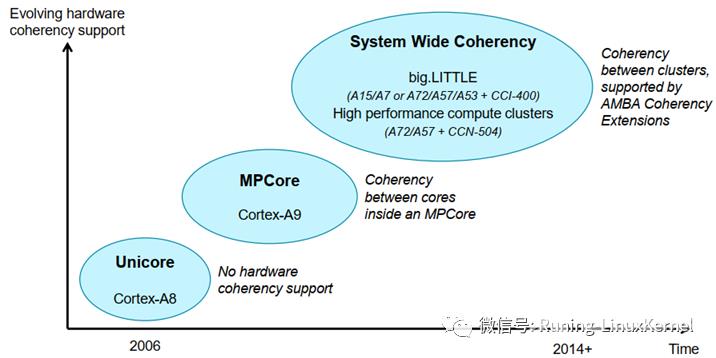
在单核CPU里我们刚才提到因为系统只有一个CPU那么他也只有一个L1 cache和L2 cache不会有第二个CPU来访问cache所以单核处理器没有cache一致性问题大家注意这里说的cache一致性问题指的是 多核之间的cache一致性问题它依然有DMA和cpu之间的cache一致性问题。还有一点大家需要注意在单核处理器系统里cache管理指令它的作用范围仅仅限于单核。
我们来看一下多核处理器的情况比如cortex-a9的MP core这种情况硬件上就支持了多核的cache一致性硬件上实现了MESI指令的协议在arm 的手册里一般称为Snoop Control Unit的硬件单元这个SCU的单元实现了MESI的协议。还有一点在多核处理器系统里cache的管理指令它会发广播消息到其他的CPU核心里这一点和单核处理器不一样。
下面三个图第一个是单核处理器的情况它只有一个cpu核心和单一的cache没有多核cache一致性问题。第二个图是一个双核的处理器每个核心内部有自己的cache那么就需要一个硬件单元来完成这两个cache的一致性问题通常就是我们说的SCU的硬件单元了。第三个图要复杂一些它由两个cluster组成每个cluster有两个核心。我们来看一个cluster它有一个缓冲一致性的硬件单元来保证core与core直接的一致性。那么在最下面有一个缓存一致性总线或者缓存一致性控制器来保证这两个cluster之间的cache一致性问题。
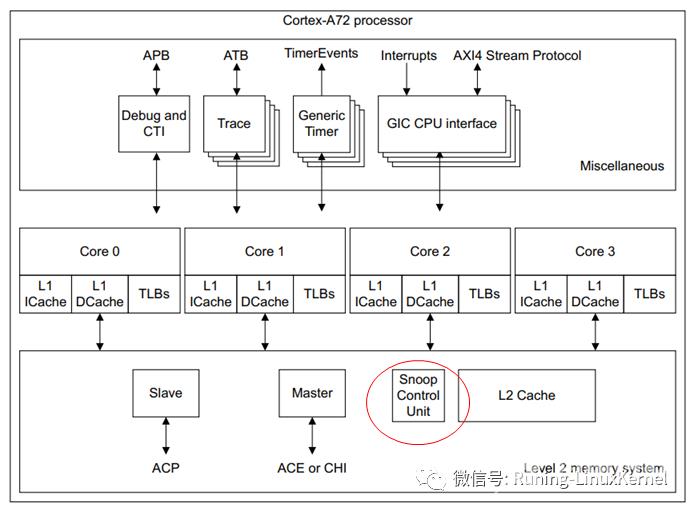
系统cache一致性问题
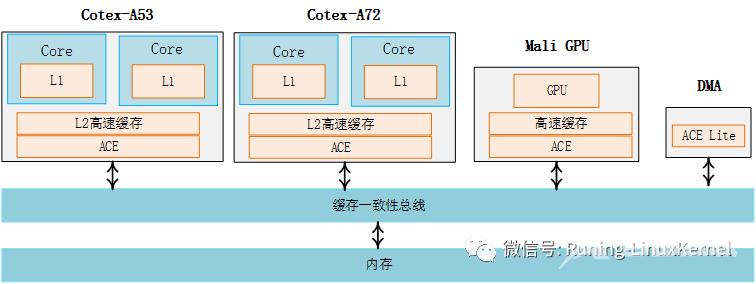
我们来看一下系统级别的cache一致性问题。因为现在的arm系统越来越复杂了从多核发展到多族例如大小核架构等。比如下面这个图这是一个典型的大小核架构小核由A53来担当大核由A72来担当两个A53核心构成了一个cluster这个cluster里每个a53的cpu都有各自独立的L1 cache然后一起共享一个L2 cache然后通过一个ACE的硬件单元连接到缓存一致性总线里ACE其实就是AXI coherent extensions的简称这个是AMBA 4协议中定义的。我们再来看大核这边它同样也是2个核心每个核心都有一个L1 cache也是共享一个L2 cache同样也是通过ACE接口连接到缓存一致性总线上。那么除了CPU之外系统还有GPU比如arm公司的mali GPU还有一些带有DMA的外设等这些设备他们都有独立访问内存的能力比如GPU还自己带有cache那么他们也必须通过ACE接口来连接到这个缓存一致性总线上。这个缓存一致性总线就是用来实现系统级别的cache一致性的。关于系统级别的cache一致性我们后面还会讲到。
cache一致性的解决方案
我们来简单看一下cache一致性的解决办法我们来讲业界常用的三种方法。
cache一致性需要保证系统中所有的CPU所有的bus master从例如GPUDMA等他们观察到的内存是一致的。举个例子外设都用DMA如果你的软件通过CPU来产生了一些数据然后想通过DMA来搬移这些数据到外设。如果CPU和DMA看到的数据不一致比如说CPU产生的数据还在cache里而DMA却从内存中直接去搬移数据那么DMA就会看到一个旧的数据那就产生了数据的不一致性。因为这个时候最新的数据是在CPU这一侧的cache里因为这个场景下CPU是生产者它来负责产生数据。
一般情况下系统的cache一致性有三种方案。
第一种方案关闭cache
第一个方案关闭cache。这是最简单的办法不过它会严重影响性能。比刚才那个例子为例CPU产生数据然后把数据会先放到一个DMA buffer里如果采用关闭cache的方式那么CPU在产生数据的过程中CPU不能利用cache这会严重影响性能因为CPU要频繁的访问DDR这样导致性能下降和功耗增加。
第二种方案软件管理cache一致性
第二个方案软件管理cache一致性。这是最常用的方式软件需要在合适的时候去clean or flush dirty cache或者invalidate old data。这种方式需要编写驱动的工程师特别小心。 优点硬件RTL实现简单 缺点
第三种方案硬件管理cache一致性
第三个方案硬件管理cache一致性。对软件是透明的。
对于多核之间的cache一致性通常的做法就是在多核里实现一个MESI协议实现一种snoop的控制单元。 对于系统级别的cache一致性需要需要实现一种coherent bus protocol。在2011年arm在AMBA 4协议里提出了AXI Coherency Extensions简称ACE来实现这个。ACE接口用来实现cluster之间的cache一致性ACE lite接口用来实现IO设备的cache一致性比如DMAGPU等。
【本文由: 响水网页设计公司 http://www.1234xp.com/xiangshui.html 欢迎留下您的宝贵建议】