目录
- 什么是 Apache Spark
- Spark 架构
- Hadoop 与 Apache Spark
- Spark 特点
- Spark的组件
- Spark Core
- Spark SQL
- Spark Streaming
- Spark MLlib
- GraphX
- 结论
什么是 Apache Spark
- Apache Spark 是一个开源数据处理引擎,使用简单的编程结构在各种计算机集群中实时存储和处理数据。
- Spark 具有一致且可组合的 API,Spark 支持多种语言,如 Python、Java、Scala 和 R。
- 开发人员和数据科学家将 Spark 整合到他们的应用程序中,以快速查询、分析和转换大规模数据。
Spark 架构
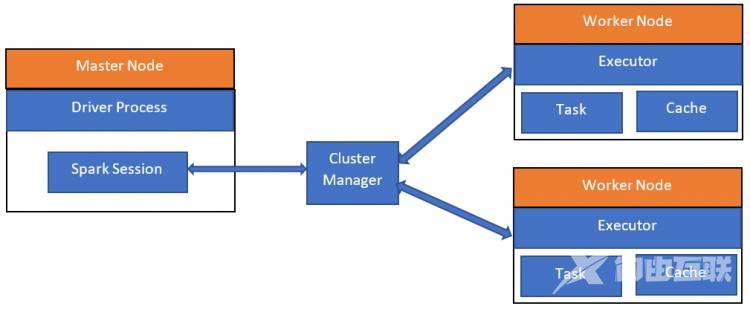
Hadoop vs Apache Spark
HadoopSpark1. Hadoop中使用MapReduce处理数据速度较慢1. Spark 在内存中处理数据的速度比 MapReduce 快 100 倍。2. 对数据进行批处理。2. 对数据进行批处理和实时处理。3. MapReduce,开发者需要手工编写每一个操作,这需要较大工作量。3. Spark 易于编程,因为它拥有大量 RDD(弹性分布式数据集)高级算子。4. Hadoop 需要较少的成本。4. Spark 需要大量内存才可正常运行,从而增加了成本。Spark 特点
快速处理 ——Spark 包含弹性分布式数据集 (RDD),它可以节省读写操作所花费的时间,因此,它的运行速度几乎是 Hadoop 的十到百倍。
**In-memory 计算 **—— 在 Spark 中,数据存储在 RAM 中,因此可以快速访问数据并加快分析速度。
灵活 ——Spark 支持多种语言,并允许开发人员使用 Java、Scala、R 或 Python 编写应用程序。
容错 ——Spark 包含弹性分布式数据集 (RDD),旨在处理集群中任何工作节点的故障。 因此,它确保数据丢失减少到零。
更好的分析 ——Spark 拥有丰富的 SQL 查询、机器学习算法、复杂分析等,借助所有这些功能,可以更好地执行分析。
Spark的组件

Spark Core
Spark Core 是用于大规模并行和分布式数据处理的基础 。 它负责:
- 内存管理
- 故障恢复
- 在集群上调度、分发和监控作业
- 与存储系统交互
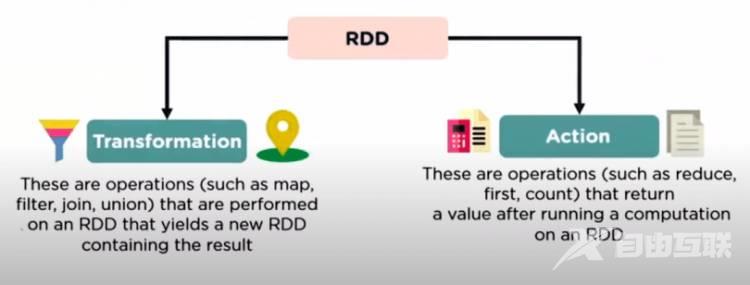
RDD (弹性分布式数据集)
Spark核心嵌入了 RDDs,这是一种不可变的容错分布式对象集合,可以并行操作。 RDD 执行两个操作。
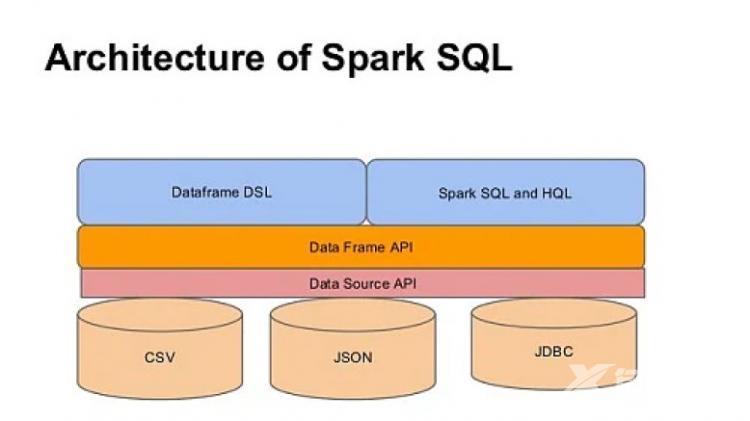
Spark SQL
Spark SQL 框架组件用于结构化和半结构化数据处理。它提供了一种称为 DataFrames 的编程抽象,也可以充当分布式 SQL 查询引擎。
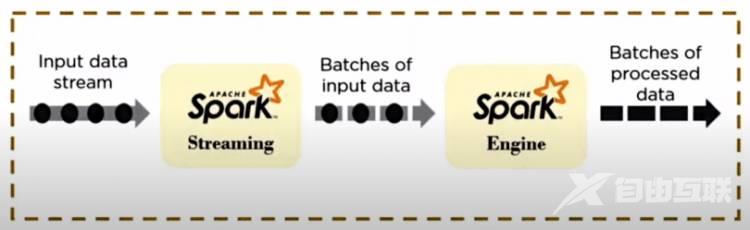
Spark Streaming
Spark Streaming 是一个轻量级 API,允许开发人员轻松执行批处理和实时数据流。它为实时数据流提供安全、可靠和快速的处理。
Spark MLlib
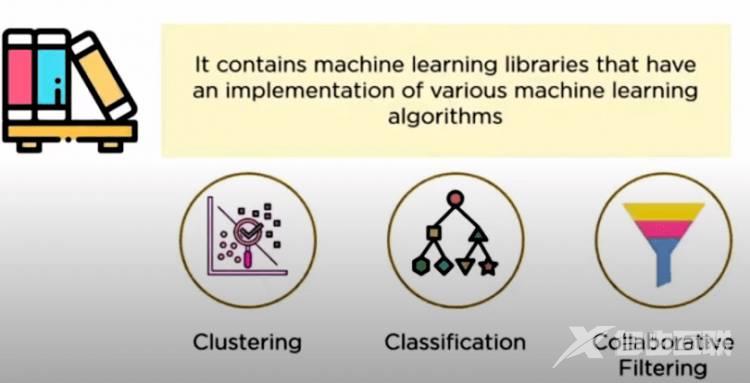
MLlib 是一种低级机器学习,使用简单、可扩展且与各种编程语言兼容。 MLlib 简化了可扩展机器学习算法的部署和开发。
GraphX
GraphX 是 Spark 自己的图形计算引擎和数据存储。
结论
在这篇博客中,我们了解了与 Apache Spark 相关的基本知识。我们还了解了 Spark 架构、Spark 特性、Spark 的组件以及 Hadoop 框架和 Apache Spark 之间的区别。
原文标题:Basic things related to Apache Spark原文作者:Shashikant tyagi原文地址:https://blog.knoldus.com/basic-things-related-to-apache-spark/