索引常见模型
哈希表适用于等值查询区间查询速度很慢
有序数组等值区间查询性能优秀适用与静态搜索引擎。 (更新成本高)
搜索树N叉树应用为主(减少树高和磁盘交互次数)InnoDB B树。
其他跳表LSM树等
哈希表结构
哈希表是一种以键 - 值(key-value)存储数据的结构我们只要输入待查找的值即 key就可以找到其对应的值即 Value。哈希的思路很
简单把值放在数组里用一个哈希函数把 key 换算成一个确定的位置然后把 value 放在数组的这个位置。
不可避免地多个 key 值经过哈希函数的换算会出现同一个值的情况。处理这种情况的一种方法是拉出一个链表
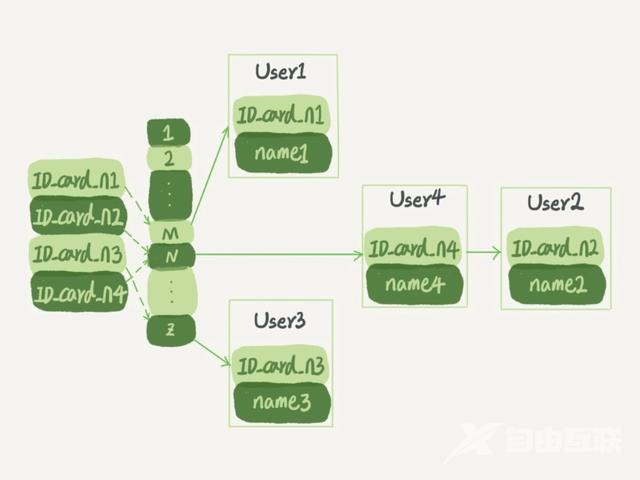
哈希表示意图
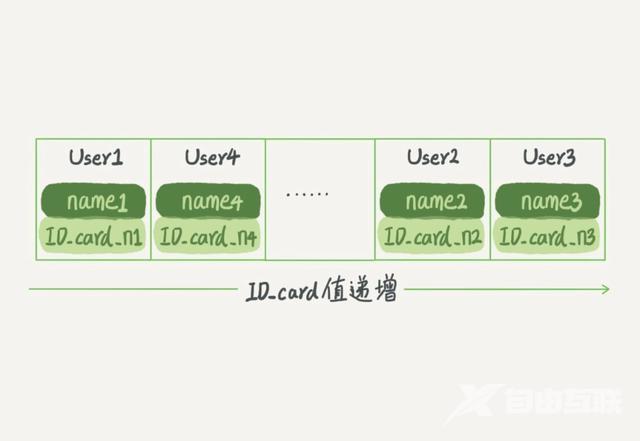
有序数组示意图
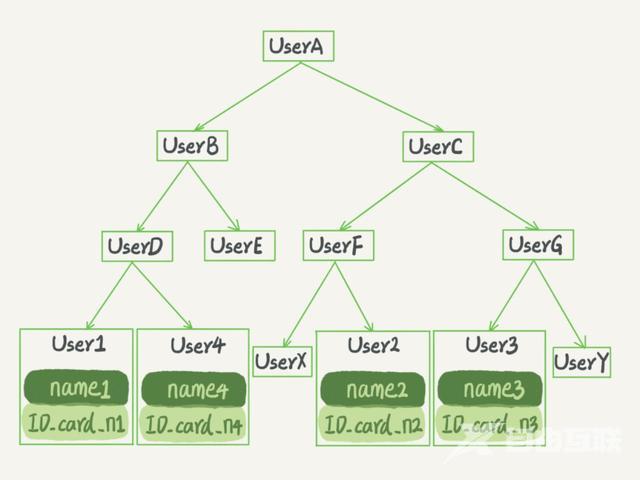
二叉搜索树示意图
InnoDB 的索引模型
每一个索引在 InnoDB 里面对应一棵 B 树。
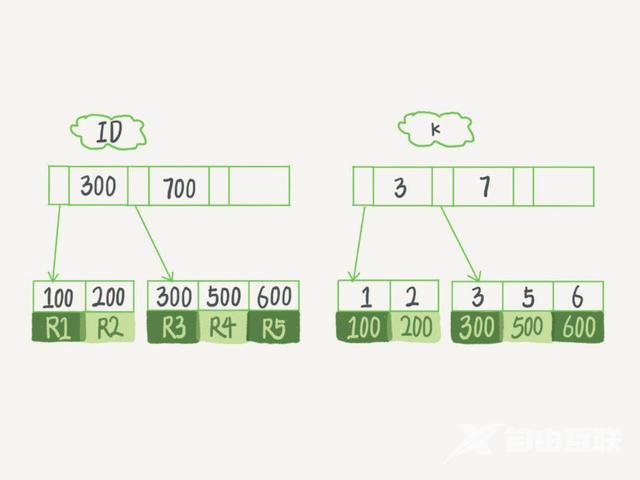
InnoDB 的索引组织结构
主键索引的叶子节点存的是整行数据也叫聚簇索引(InnoDB中)
非主键索引的叶子节点内容是主键的值。
基于非主键索引的查询需要多扫描一棵索引树。因此我们在应用中应该尽量使用主键查询。
自增主键的插入数据模式正符合了我们前面提到的递增插入的场景。每次插入一条新记录都是追加操作都不涉及到挪动其他记录也不会触发叶子节点的分裂。
主键长度越小普通索引的叶子节点就越小普通索引占用的空间也就越小
所以自增主键往往是合理的选择。
重建索引的过程会创建一个新的索引把数据按顺序插入这样页面的利用率最高索引更紧凑更省空间。
主键索引只能重新建表才能重建索引。(钱的教训)删除数据索引还在索引树还是会很大。
覆盖索引
由于覆盖索引可以减少树的搜索次数显著提升查询性能所以使用覆盖索引是一个常用的性能优化手段。
如果现在有一个高频请求要根据市民的身份证号查询他的姓名这个联合索引就有意义了。它可以在这个高频请求上用到覆盖索引不再需要回表查整行记录减少语句的执行时间。
当然索引字段的维护总是有代价的。因此在建立冗余索引来支持覆盖索引时就需要权衡考虑了。这正是业务 DBA或者称为业务数据架构师的工作。
最左前缀原则
这个最左前缀可以是联合索引的最左 N 个字段也可以是字符串索引的最左 M 个字符。
第一原则是如果通过调整顺序可以少维护一个索引那么这个顺序往往就是需要优先考虑采用的。
索引下推
而 MySQL 5.6 引入的索引下推优化(index condition pushdown) 可以在索引遍历过程中对索引中包含的字段先做判断直接过滤掉不满足条件的记录减少回表次数
mysql> select * from tuser where name like 张 % and age10 and ismale1;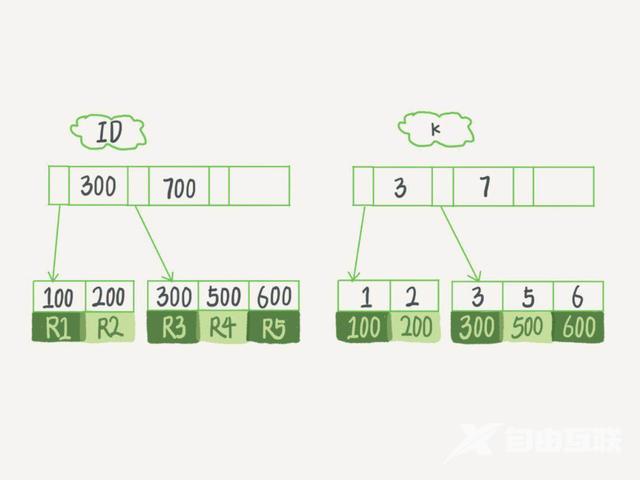
无索引下推执行流程
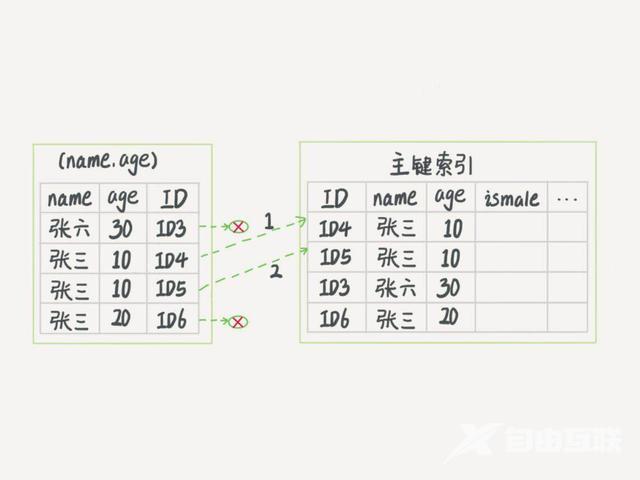
索引下推执行流程